Akira's ML news #Week 38, 2020

※有料設定してますが、投げ銭用なので全部無料でみれます。
2020年第37週(9/13~)に私が読んだ論文や記事で特に面白かったものを紹介します。※なるべく新しいものを紹介していますが、論文投稿日はこの週のものとは限りません。
内容 1. 論文, 2.技術的な記事等, 3. 機械学習の活用/社会実装, 4. その他話題
1. 論文
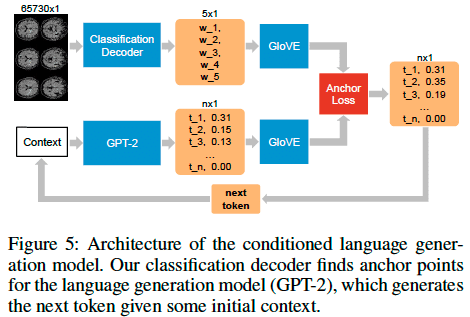
脳の中をGPTを使って見てみる
Brain2Word: Decoding Brain Activity for Language Generation
https://arxiv.org/abs/2009.04765
脳の状態を調べるfMRIの画像から見ている文字を再現する研究。fMRIの画像を入力とし、180の単語候補から有力候補5つのGloVE埋め込みベクトルを生成。次に50257の語彙をもつGPT-2での同じことをして2つを比較することで言語モデルとして解く。既存手法と比較して大きく精度が向上した。
数学の定理の証明をNLPで実施する
Generative Language Modeling for Automated Theorem Proving
https://arxiv.org/abs/2009.03393
自然言語処理界隈でよく使われるTransformerモデルを用いて、数学定理の証明を自動で行うGPT-fを提案。定理の証明を[GOAL,(定理),PROOFSTEP,...]のように言語モデルとして定義して学習させる。事前学習を行うことで精度が向上し、23個の定理で既存の証明より短くすることに成功。数学界隈でも評判よかったとのこと。

AlphaZeroでゲームバランスを整える
Assessing Game Balance with AlphaZero:Exploring Alternative Rule Sets in Chess
https://arxiv.org/abs/2009.04374
トップ囲碁棋士に勝利したAlphaGoの後継モデルで、将棋なども扱えるAlphaZeroを用いてゲームバランス評価をする試み。キャスリング不可など微量のルール変化を与えたチェスもどきをAlphaZeroで学習させることで、熟練プレーヤーがそれぞれのチェスの亜種に対してどのような見方をしているのかを見ることができる。チェスの歴史でもルールの改変を繰り返して今のルールに落ち着いており、他のゲームでもそのようなことがAlphaZeroを使うことで擬似的にできるようになることができるとのこと。

人の評価結果を使って要約精度を向上させる
Learning to summarize from human feedback
https://arxiv.org/abs/2009.01325
文書要約ではROUGEスコアを使って評価しているが、要約の質を正しく評価できておらず、人の評価と肌感が合わないことがある。人の評価をRewardとして強化学習で文書要約をさせることで、人間が好む(良いと思う)要約を生成する研究。人の評価において既存のモデルを大きく上回る。さらにデータドメイン間の変更(Redditで学習→CNN/DMで評価)にも強いとのこと

ディープフェイクを生体信号を使って検知する
How Do the Hearts of Deep Fakes Beat? Deep Fake Source Detection via Interpreting Residuals with Biological Signals
https://arxiv.org/abs/2008.11363
深層生成モデルを使ったDeepFake(偽ビデオ)は社会問題になっている。この研究ではPPGという生物学的な信号の情報を使うことで、DeepFake検知の精度97.29%を達成した。また、生成モデル毎に特有な偽のPPG信号っぽいものが生成されることがわかり、生成モデルの特定も93.39%することが可能。

ビデオの中の人の時間軸を操作する
Layered Neural Rendering for Retiming People in Video
https://arxiv.org/abs/2009.07833
動画中の人物の動きのタイミング(動作の開始、速度)を変更できるモデル。まず、影になっている人も含めてそれぞれの人の動きと背景を分離する。そして、背景とそれぞれの人の情報を組み合わせて特徴量化し、それらを組み合わせることで合成する。人の動きに付随する水しぶきなどのタイミングも変更できている。

2.技術的な記事等
良い初期値だけでネットワークを疎に保ったまま学習
GoogleのICML2020の研究で、個人的にすごく注目していた論文。初めからスパースなネットワークで枝刈&接続しながら、スパース性を保ちつつ良い初期値のみで学習させる"Rigging the Lottery"という手法を提案。手法名は、「NNには精度に貢献する良い初期値をもつニューロンが少数のみ存在する」宝くじ仮説(Lottery Ticket Hypothesis)より、良い初期値のみをとってこれるイカサマ(Rigging)ができることより由来している(と思う)。ネットワークがスパースなまま学習できるので、メモリに乗り切らない超巨大なネットワークを学習できることができると主張している。
以前私が書いた解説はこちら↓
ACL2020 SlideLive
ACL2020のSlideLive(著者が論文をスライドにおとして数分で解説してくれるビデオ)が公開されている。下記URLで、論文の左側にあるビデオカメラのアイコンをクリックすると再生できる。
ICML 2020
ICMLL2020のSlideLive(著者が論文をスライドにおとして数分で解説してくれるビデオ)が公開されている。わりと見やすいWebページになっており、最新のものや人気のものでソートが可能。
強化学習の網羅的な資料
えるエル(@ImAI_Eruel)さんによる深層強化学習サマースクールにおける講義資料。強化学習の基礎からAgent57のような新しめの話題まで網羅されている。7ページ目から度々登場する強化学習の流れをまとめた図は必見。
3. 機械学習の活用/社会実装
GNNを使ってGoogle Mapの到着時刻予測を改善する
Graph Neural Networksを用いて、Google Mapの到着時刻を最大で50%程度の改善に成功した。グラフで局所的な交通網をグラフデータとして扱い、サンプリングすることで単一のモデルを大規模に展開できる。

AIツールへの保険適用
脳卒中の兆候を察知して患者が時間的に重要な治療を受けられるようにするAIツール「Viz LVO」の使用に対する病院への払い戻しに合意した。Viz LVOは、90パーセントの精度で脳のCTスキャンから脳卒中患者を特定し、自動的に専門家に通知する。1回の使用毎に最大で1040ドルの払い戻しができる。病院側が大きな経済的な負担なしにこのようなAIツールを使えるようになる。
4. その他話題
deeplearning.ai のNLPのオンライン講義
Andrew Ng先生が立ち上げたdeeplearning.ai による自然言語処理講座。全部で4つの講義から成り、4つ目ではT5やReformerなど最新のモデルを扱っている。
BYOLのソースコードが公開
自己教師あり学習BYOL(Bootstrap Your Own Latent)のソースコードと学習済みモデルがDeepMind公式のものが公開された。BYOLはSimCLRやMoCoと異なり、対比損失(Contrastive Loss)を陽に用いていないモデル。日本語の解説ではAi-scholorの記事が詳しい。
The source code and checkpoints for BYOL are now available along with an updated version of the BYOL paper - including new theoretical and experimental insights.
— DeepMind (@DeepMind) September 15, 2020
Code: https://t.co/6QEUjmAt9L
Paper: https://t.co/qyaSXnPQjN https://t.co/8226fwJBuP
DeepSpeedで1兆パラメータモデルの学習が可能に
Micorsoftの深層学習ライブラリDeepspeedで最大1兆パラメーターのモデルの学習が可能になった。これはGPT-3(2020年9月17日現在で最大のパラメータ数をもつモデル)の5倍以上のパラメータ数である。NvidiaのV100 GPUが1つしか使えないとしても、130億パラメータのモデルが学習できるもよう。貧弱な計算環境しかない企業や研究室でも色々できるようになるかもしれない。
---------------------------------------------------------
TwitterでMLの論文や記事の紹介しております。
https://twitter.com/AkiraTOSEI
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。