
【論文瞬読】最新AI研究!LLMの知識の限界を見極める!適応型検索拡張生成(ARAG)の新評価手法とは?

はじめに
こんにちは!株式会社AI Nestです。今回は、最新のAI研究から、大規模言語モデル(LLM)の知識の限界を探る興味深い論文を紹介します。「RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering」という論文なんですが、これがなかなか面白いんです!
LLMってすごい知識の塊ですよね。でも、「全部知ってる」わけじゃないんです。そこで登場するのが「検索拡張生成(RAG)」という技術。LLMが自分の知識で答えられないときに、外部の情報を検索して回答するんです。でも、いつも検索すればいいってもんじゃない。そこで注目されているのが「適応型検索拡張生成(ARAG)」。これ、すごく重要なんです!
タイトル:RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
URL:https://arxiv.org/abs/2402.16457
所属:University of Technology Sydney, University of Liverpool
著者:Zihan Zhang, Meng Fang, Ling Chen
ARAGって何?なぜ重要なの?
ARAGは、簡単に言うと「LLMが自分で『検索が必要かどうか』を判断する」技術です。これがなぜ重要かというと:
効率が上がる:必要なときだけ検索するので、処理が速くなります。
精度が上がる:不要な情報を引っ張ってこないので、的確な回答ができます。
コストが下がる:APIコールの回数が減るので、運用コストが抑えられます。
つまり、ARAGは「賢く検索する」技術なんです。でも、これまでARAGをちゃんと評価する方法がなかったんです。ここで登場するのが今回の論文!

上の図を見てください。これは異なるモデルでのRetrievalQAの性能を示しています。青い棒が「検索なし」、オレンジの棒が「適応型検索」、緑の棒が「常時検索」の精度です。見てわかるように、適応型検索(ARAG)は、単純に常に検索するよりも効率的で、かつ高い精度を実現できる可能性があるんです。
RetrievalQA:ARAGを評価する新しいベンチマーク
研究チームが提案したのは、「RetrievalQA」という新しいデータセット。これ、すごくよくできてるんです。
特徴は:
1,271の短い質問で構成
新しい世界の知識と、あまり一般的ではない長期的な知識をカバー
LLMの知識では答えられない質問ばかり
つまり、このデータセットを使えば、LLMが「自分の知識の限界」をどれだけ正確に判断できるか、そして「検索が必要」と判断したときに、ちゃんと正しい答えにたどり着けるかを評価できるんです。
既存手法の問題点
研究チームは、既存のARAG手法を2つのタイプに分類しています:
校正ベース:あらかじめ設定した閾値を超えたら検索する
モデルベース:LLMに直接「検索する?しない?」と聞く
で、どっちにも問題があったんです。
校正ベースは、閾値の設定が難しい。データセットやモデルが変わるたびに調整が必要で、これが結構面倒くさい。
モデルベースは、単純に「検索する?」って聞くだけじゃダメだったんです。LLMが「うーん、大丈夫かな?」って思っちゃうことが多くて、結局必要な検索をしないことがあったんです。
図1の下部は、GPT-3.5モデルのエラー分析を示しています。赤い部分は、モデルが検索の必要性を認識できなかったケースを示しています。つまり、既存の手法では、LLMが自分の知識の限界を正確に把握できていないことがわかります。
新提案:TA-ARE
そこで研究チームが提案したのが、「Time-Aware Adaptive REtrieval(TA-ARE)」という新しい手法。これ、シンプルなのにめちゃくちゃ効果的なんです!
TA-AREのポイントは2つ:
時間認識:「今日の日付はXXXXです」ってLLMに教えてあげる
文脈学習:検索が必要な質問と不要な質問の例を示してあげる
これだけで、LLMの判断精度が大幅に向上したんです。特に、最新の出来事に関する質問や、マイナーな知識を問う質問での改善が顕著でした。
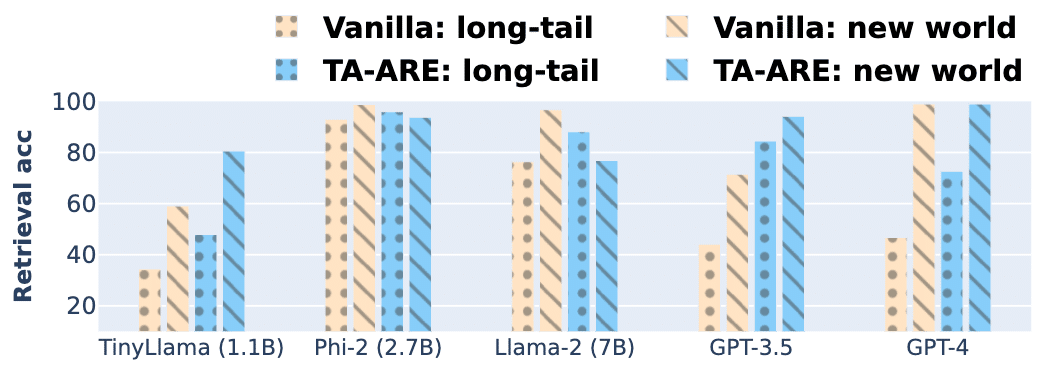
この図を見てください。縦軸が検索精度、横軸が異なるモデルを示しています。黄色い線が既存の手法(Vanilla)、青い線が新しい手法(TA-ARE)です。点線は長期的知識に関する質問、斜線は新しい世界知識に関する質問の結果です。ほとんどのモデルで、TA-AREが既存手法を上回っていることがわかりますね。
実験結果:TA-AREの威力
実験結果を見てみましょう。様々なサイズのLLM(TinyLlama、Phi-2、Llama-2、GPT-3.5、GPT-4)で試してみたんですが、どのモデルでもTA-AREは既存手法を上回る性能を示しました。

この表を見てください。「Vanilla」が既存手法、「TA-ARE」が新しい手法です。「Retrieval」列が検索判断の精度、「Match」列が質問応答の正確さを示しています。
特に印象的なのは:
検索判断の精度が平均で14.9%も向上
質問応答の正確さが平均で6.7%向上
GPT-3.5での改善が特に顕著で、検索判断の精度が37%も向上したんです!これ、すごいことですよ。
今後の展望と課題
この研究、すごく面白いんですが、まだまだ課題もあります。
長文生成タスクでの評価がまだ
検索の質自体の改善も必要
プロンプトの最適化でもっと性能が上がる可能性も

この図は、デモンストレーション例の数による性能の変化を示しています。4つの例を使うのが最適だというのがわかりますね。こういった細かい調整で、さらに性能が向上する可能性があるんです。
まとめ:AI研究の最前線
今回紹介した研究、すごく重要なんです。なぜって?
LLMの限界を正確に把握できるようになる
必要なときだけ外部知識を使うので、効率的で正確な AI システムが作れる
コストダウンにもつながる
つまり、より賢く、効率的で、経済的なAIシステムへの大きな一歩なんです。
AIの世界は日々進化しています。今回の研究のように、既存の技術の限界を突き詰め、新しいアプローチを提案する。そんな挑戦が、AIの未来を切り開いているんですね。
みなさんも、こんな最先端の研究に触れて、AIの可能性について考えてみてはいかがでしょうか?
それでは、次回のテックブログでまたお会いしましょう!AI の世界には、まだまだ驚きがいっぱいです!