
【論文瞬読】大規模言語モデルの推論能力の秘密:前提の順序が鍵を握る!

みなさん、こんにちは!株式会社AI Nestです。
今日は、大規模言語モデル(Large Language Models: LLMs)の推論能力における前提の順序の影響について、興味深い研究を紹介したいと思います。
タイトル:Premise Order Matters in Reasoning with Large Language Models
URL:https://arxiv.org/abs/2402.08939
所属:Equal contribution, Google DeepMind, Stanford University
著者:Xinyun Chen, Ryan A. Chi, Xuezhi Wang, Denny Zhou
研究の概要
LLMsは、自然言語処理の分野で大きな注目を集めています。GPT-3やBERTなどの大規模な言語モデルは、質問応答、文章生成、感情分析などの様々なタスクで驚くべき性能を示し、AIの可能性を大きく広げてきました。しかし、その一方で、LLMsの推論能力の限界についてはまだ多くの謎が残されているのも事実です。
そんな中、ある研究チームが、LLMsの推論能力における前提の順序の影響という、これまであまり注目されていなかった側面に着目しました。彼らは、演繹的推論と数学的問題解決という2つのタスクを用いて、複数のLLMs(GPT-4-turbo、GPT-3.5-turbo、PaLM 2-L、Gemini Proなど)の性能を評価しました。
驚くべき発見
その結果、驚くべきことが明らかになりました。LLMsは前提の順序に非常に敏感で、その順序が推論ステップに沿っていない場合、パフォーマンスが大幅に低下するというのです。具体的には、前提の順序を変更すると、LLMsの精度が30%以上も低下したとのこと。これは、LLMsの推論能力の限界を理解する上で、非常に重要な発見だと言えます。

前提の順序が正しい場合と、シャッフルされた場合のGPT-4-turboの予測結果の比較
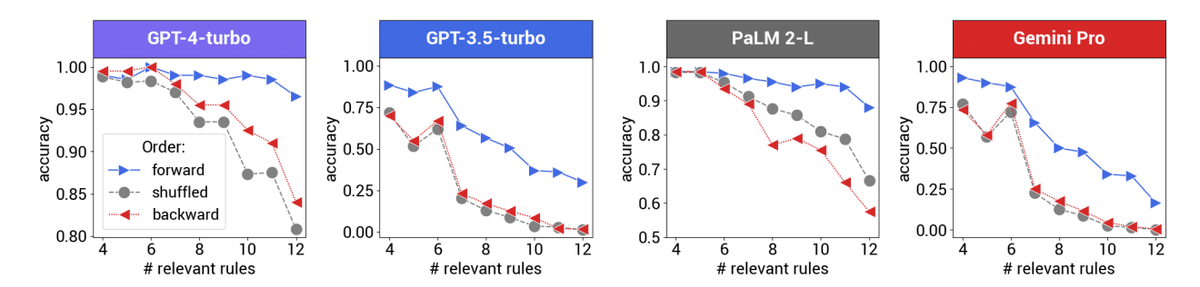
前提の数が増えるほど、順序の影響が大きくなることを示している

さらに興味深いのは、この現象が演繹的推論と数学的問題解決という2つの異なるタスクで一貫して観察されたことです。つまり、この現象はタスク固有のものではなく、LLMsの推論能力に内在する特性である可能性が高いということです。
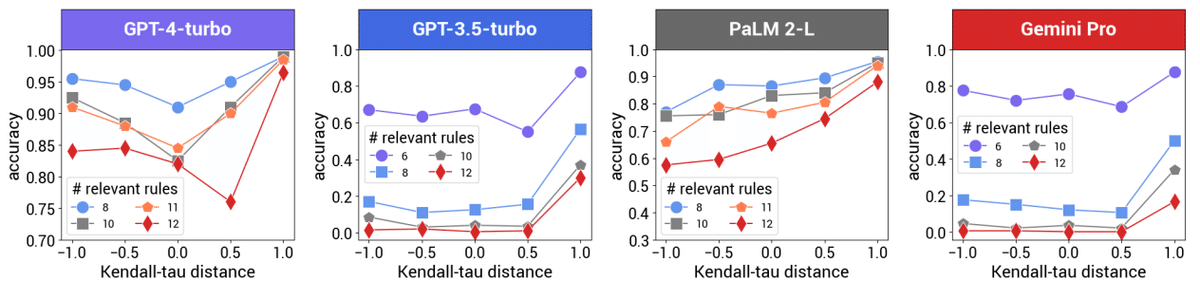
τ=1が正解の証明に沿った順序、τ=-1が逆順である

新しいベンチマーク:R-GSM
研究チームは、前提の順序の影響を定量的に評価するための新しいベンチマーク(R-GSM)も提案しています。R-GSMは、有名な数学の問題集であるGSM8Kをベースに、問題文の順序を変更したバージョンを作成したものです。このようなベンチマークは、LLMsの推論能力の限界を理解し、それを改善するための新しい技術を開発する上で重要な役割を果たすでしょう。

ステップ数が多いほど、順序の影響が大きくなる

長い問題文ほど、順序の影響が大きくなる


今後の課題
ただし、この研究では、LLMsが前提の順序に敏感である理由について明確な結論は出ていません。研究チームは、自己回帰モデル設計、トレーニング目的、トレーニングデータのバイアスなどが原因である可能性を示唆していますが、確定的なことは言えないようです。また、この限界に対処するための具体的な技術の提案も、今後の課題として残されています。

おわりに
とはいえ、この研究は、LLMsの推論能力の限界を理解する上で重要な一歩を踏み出したと言えます。LLMsの推論能力の向上には、前提の順序の影響を考慮した新しいモデル設計やトレーニング手法の開発が必要不可欠であり、この研究はそのための重要な基礎を提供していると言えるでしょう。
今後、LLMsの推論能力の謎を解明するために、さらなる研究が進められることを期待しています。前提の順序の影響以外にも、LLMsの推論能力に影響を与える要因は多数あると考えられます。それらを1つ1つ明らかにしていくことで、より高度な推論能力を持つLLMsの開発が可能になるかもしれません。
AIの発展は目覚ましいものがありますが、まだまだ未知の領域も多く残されています。LLMsの推論能力の限界を探求する研究は、AIの可能性を広げ、より賢いAIの実現に向けた重要なステップになるでしょう。これからのLLM研究の動向から目が離せませんね!