
【論文瞬読】大規模言語モデルは外部情報にどう反応する?知識の矛盾への対処法を探る

こんにちは!株式会社AI Nestです。
今回は、大規模言語モデル(LLMs)の振る舞いに関する興味深い研究を紹介します。みなさんは、LLMsが外部情報と矛盾する場合、どのように反応すると思いますか?この問いに答えるべく、研究者たちが行った実験の結果を見ていきましょう。
タイトル:Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts
URL:https://arxiv.org/abs/2305.13300
機関:School of Computer Science, Fudan University, The Ohio State University, The Pennsylvania State University
著者:Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, Yu Su
研究の背景と目的
LLMsは大量のデータで学習することで、パラメトリックメモリと呼ばれる内在的な知識を獲得します。しかし、このパラメトリックメモリは古くなったり、不正確だったりする可能性があるんです。そこで、外部ツールを用いてLLMsに最新の情報を提供する「ツール拡張」という手法が注目されています。
でも、外部情報がパラメトリックメモリと矛盾する場合、LLMsはどのように反応するのでしょうか?この研究では、そんな「知識の矛盾」におけるLLMsの振る舞いを明らかにすることを目的としています。
実験の方法とその結果
研究者たちは、まずLLMsのパラメトリックメモリを引き出し、それと矛盾するカウンターメモリを構築するためのフレームワークを提案しました。そして、このフレームワークを用いて一連の制御された実験を行ったのです。
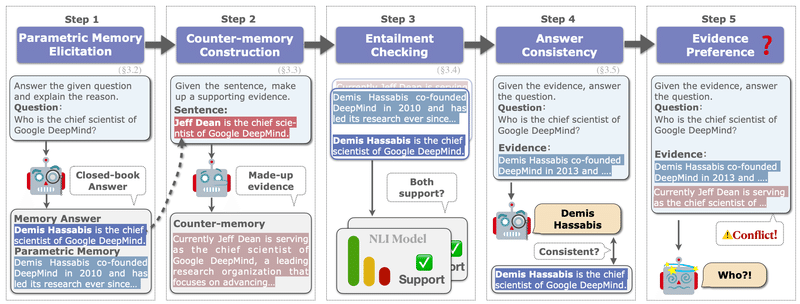

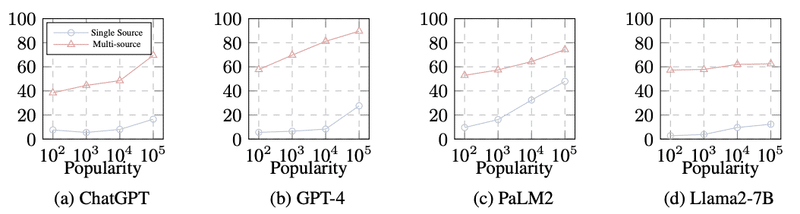
実験の結果、LLMsは首尾一貫したカウンターメモリに対して非常に受容的であることが明らかになりました。これは、先行研究とは異なる知見で、ちょっと意外ですよね。でも、パラメトリックメモリを支持する証拠と矛盾する証拠の両方がある場合、LLMsは確証バイアスを示すことも分かったんです。
研究の意義と今後の課題
この研究は、ツール拡張されたLLMsの開発と展開において考慮すべき重要な示唆を与えています。LLMsの高い受容性は、古い知識の修正に有効である一方で、悪意のある情報に騙される可能性も示唆しているんです。また、確証バイアスは、LLMsによる情報の偏りない統合を妨げる可能性があります。
今後は、他のタスクへの一般化可能性の検証や、悪意のある攻撃への対策、確証バイアスの低減方法など、さまざまな課題に取り組む必要がありそうです。
まとめ
今回紹介した研究は、LLMsの知識の矛盾への対処法に関する理解を深める上で重要な貢献をしていると思います。著者らが提案したフレームワークは、今後のLLMs研究において広く活用されるのではないでしょうか。
みなさんは、この研究結果をどう思いましたか?LLMsの振る舞いに関する新たな発見に、わくわくしませんか?この分野の発展に寄与する論文だと感じました。
ぜひ、みなさんもLLMsの可能性と課題について考えてみてください。そして、AIとどのように付き合っていくべきか、一緒に考えていきましょう!