
【論文瞬読】大規模言語モデルの算術推論能力を適切に評価する新手法-ベンチマークデータの汚染と過学習の問題に迫る-

こんにちは!株式会社AI Nestです。
みなさん、こんにちは。今回は自然言語処理の分野で注目を集めている大規模言語モデル(LLM)の評価手法について、興味深い研究論文を見つけたのでご紹介します。タイトルは「A Careful Examination of Large Language Model Performance on Grade School Arithmetic」。LLMの算術推論能力を適切に評価するための新しいアプローチを提案しています。
タイトル:A Careful Examination of Large Language Model Performance on Grade School Arithmetic
URL:https://arxiv.org/abs/2405.00332
著者:Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, Summer Yue
大規模言語モデル(LLM)とは?
まず、LLMについて簡単に説明しましょう。LLMは大量のテキストデータを用いて学習された言語モデルで、GPTやBERTなどが有名です。膨大な知識を持ち、質問応答や文章生成など、さまざまなタスクで人間に迫る性能を示すことで注目を集めています。
GSM8kベンチマークの問題点
LLMの算術推論能力を評価するためのベンチマークとして、GSM8kがよく知られています。これは小学校レベルの算術問題からなるデータセットで、問題を解くのに平均8ステップを要するとされています。しかし、本論文の著者らは、GSM8kには重大な問題があると指摘しています。
LLMの学習データにGSM8kの問題が紛れ込んでいる可能性があるのです。つまり、モデルがGSM8kで高い精度を示しているのは、単に問題を丸暗記しているだけかもしれません。これでは、LLMの真の推論能力を測ることはできません。
GSM1kベンチマークの提案
そこで著者らは、GSM8kと同等の問題を新たに作成し、GSM1kと名付けました。ポイントは、GSM1kを非公開にすることです。これによって、モデルがGSM1kの問題を事前に学習することを防ぐことができます。
GSM1kの作成には細心の注意が払われました。問題の難易度分布がGSM8kと同等になるよう調整し、人手で精査することで品質を担保しています。
GSM8kとGSM1kの比較実験
著者らは、代表的なオープンソースとクローズドソースのLLMについて、GSM8kとGSM1kの性能を比較しました。すると、興味深い結果が得られました。
GSM8kでは高い精度を示すモデルの中に、GSM1kでは大幅に性能が低下するものが見られたのです。図1は、各モデルのGSM8kからGSM1kへの性能低下を示しています。MistralやPhiといったモデルファミリーで過学習の兆候が顕著なのに対し、Gemini、GPT、Claudeでは過学習が少ないことがわかります。

さらに、GSM8kで70%以上の精度を持つモデルに注目してみましょう。図5は、これらのモデルについて、過学習のないライン(点線)との比較を示しています。やはりMistral、Phiの過学習が明確に見て取れる一方、Claudeファミリーはラインの上にあり、過学習が少ないことがわかります。

これらの結果は、GSM8kの問題が学習データに混入していた可能性を強く示唆しています。
モデルは本当に暗記しているのか?
過学習が見られたモデルは、完全に暗記に頼っているのでしょうか?著者らは、必ずしもそうではないと分析しています。
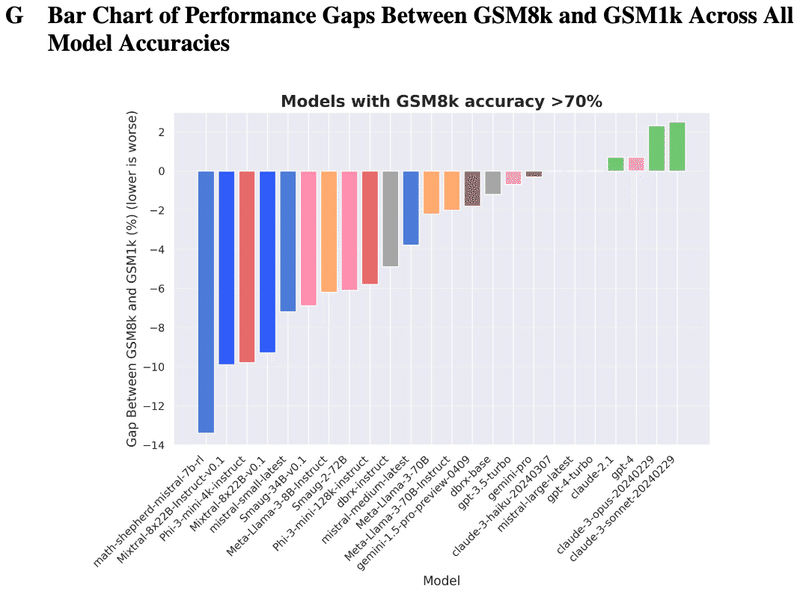
たとえ過学習の度合いが大きいモデルでも、GSM1kで一定の性能を示しました。学習データに含まれていない新しい問題にも、ある程度は一般化できるようです。図12は、GSM8kで70%以上の精度を持つモデルについて、GSM8kとGSM1kの性能差を棒グラフで示したものです。過学習の度合いに違いはあれど、どのモデルもGSM1kで一定の性能を維持していることがわかります。
データ汚染の影響
著者らは、過学習の一因としてデータ汚染の影響を指摘しています。図8は、モデルがGSM8kの問題を生成する確率と、過学習の度合いの関係を示したものです。両者の間には正の相関が見られ、過学習の一因としてGSM8kの問題が学習データに混入していた可能性が裏付けられています。

ただし、データ汚染だけが原因ではないようです。例えば、学習データにGSM8kの問題が含まれていないことがわかっているモデルでも、過学習が見られたケースがありました。ベンチマークへの過学習には、ほかにも要因があると考えられます。
今後の展望
本論文は、LLMの適切な評価に向けて重要な示唆を与えてくれました。著者らは、以下のようなアプローチを提案しています。
・ベンチマークを非公開にし、一定の条件を満たした時点で公開する
・合成データではなく、人手でデータセットを作成する
・個々のデータポイントに依存しない、機能的評価の活用
LLMの評価は簡単ではありません。でも、その能力を正しく理解することは、自然言語処理の発展にとって欠かせません。本論文は、そのための重要な一歩を示してくれたと言えるでしょう。
おわりに
というわけで、LLMの評価手法に関する興味深い論文を紹介しました。著者らの提案するアプローチは、今後の研究の発展に大きく寄与すると期待されます。
LLMは自然言語処理の未来を担う技術の一つです。その可能性を最大限に引き出すには、適切な評価手法の確立が不可欠です。本論文のような地道な研究の積み重ねが、その実現につながるのだと感じました。
みなさんも、LLMの評価に関する最新の研究動向に注目してみてくださいね。それでは、今回はここまで。また次の記事でお会いしましょう!