
[ComfyMaster29] 参照画像でAIをコントロール!IPAdapterの使い方 #ComfyUI

理想のビジュアルをAIに伝えたいのに、テキストだけでは限界を感じていませんか?
IPAdapterなら、参照画像を使って視覚的に指示できます。
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第29回目になります。
本記事では、1枚の画像から高度に画風を適用できる「IPAdapter」(アイピーアダプター)の解説です。例えば、「劇画風のしらいはかせ」画像を使うとこんな画像がプロンプトだけで生成できます。
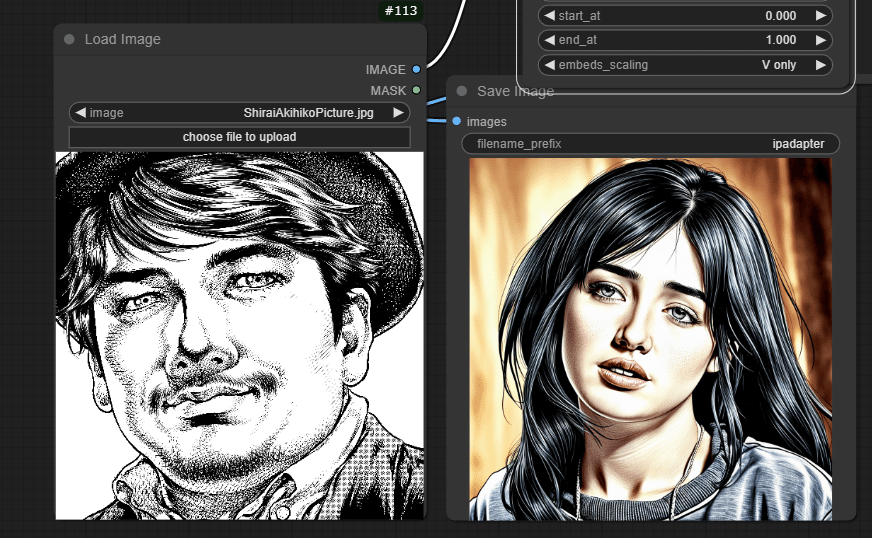
本稿ではIPAdapterの仕組みとComfyUIでの活用方法をステップバイステップで解説し、参照画像に基づいた高品質な画像生成を行えるようになることを目指します。気になる倫理面についても配慮していきましょう。
[ComfyMaster28] 落書きが画像に!ControlNet Scribble入門 #ComfyUI
1. 概要
IPAdapterは、テキストプロンプトに加えて参照画像を入力することで、AIによる画像生成をより精密に制御する技術です。画像のスタイル、特定の視覚要素、全体的な構図など、テキストでは表現しきれないニュアンスをAIに伝えることを可能にし、生成画像の品質、一貫性、再現性を向上させます。
本記事では、IPAdapterの仕組み、ComfyUI上での具体的なワークフロー、そして生成結果を通して、その効果と活用方法を解説します。蝶の画像を参考に人物画像を生成する例を通して、IPAdapterの強度や適用方法による変化、linear、style transfer、ease_inといった異なる重みタイプの効果の違いを検証します。
2. IPAdapterとは
IPAdapterは、テキストベースのプロンプトと視覚的な参照画像を組み合わせることで、AIに対してより詳細で正確な指示を与えることを可能にする技術です。この手法により、生成される画像の品質、スタイルの一貫性、特定の視覚要素の再現性が大幅に向上します。
技術的背景
IPAdapterの核心は、画像エンコーダーとテキストエンコーダーの出力を効果的に統合する能力にあります。この過程は以下のように要約できます。
画像エンコーディング: 入力された参照画像は、畳み込みニューラルネットワーク(CNN)などの画像エンコーダーによって処理され、高次元の特徴ベクトルに変換されます。
テキストエンコーディング: 同時に、テキストプロンプトは言語モデルによって処理され、同じく高次元の特徴ベクトルに変換されます。
特徴の融合: 画像とテキストから得られた特徴ベクトルは、複雑な方法で結合されます。この過程では、注意機構(Attention Mechanism)などの技術が用いられることがあります。
潜在空間への投影: 融合された特徴は、Stable Diffusionの潜在空間に投影されます。この空間内で、画像生成プロセスが行われます。
画像生成: 最後に、潜在表現から実際の画像ピクセルへのデコードが行われ、最終的な出力画像が生成されます。
IPAdapterの利点
精密な視覚情報の伝達: テキストだけでは表現しきれない細かいニュアンスや視覚的特徴を、AIモデルに効果的に伝達できます。
スタイルの一貫性: 特定のアーティストのスタイルや、製品デザインなどを高い一貫性で再現することが可能です。
学習効率の向上: 新しい視覚概念や複雑な構図を、画像を通じてAIモデルに効率的に「教える」ことができます。
創造性の拡張: 視覚的なインスピレーションを直接AIに伝えることで、より革新的で予想外の結果を得られる可能性が高まります。
3. ワークフローの使用準備
カスタムノード
ComfyUI IPAdapter plus: IPAdapterをComfyUI上で使用できるようにしたカスタムノードです。ComfyUI Managerからインストール可能です。このカスタムノードの詳細を知りたい方は、以下のリポジトリを参照してください。
モデル
RealVisXL V5.0: 実写系を得意とするモデルで、商用利用可能(画像の販売、サービスへの組み込み可能)になります。このモデルを以下のリンクよりダウンロードし、「ComfyUI/models/checkpoints」フォルダに格納してください。
CLIP Vision: IPAdapterで使用します。以下のいずれか、または両方をダウンロードし、「ComfyUI/models/clip_vision」フォルダに格納してください。
IPAdapterモデル: HuggingFace/h94 よりIPAdapterのモデルをダウンロードし、「ComfyUI/models/ipadapter」フォルダに格納してください。
画像素材
今回は、以下の画像をIPAdapterで参照します。

画像ファイルは、以下よりダウンロードしてください。
画像ファイル (右クリックで保存)
4. ワークフロー解説
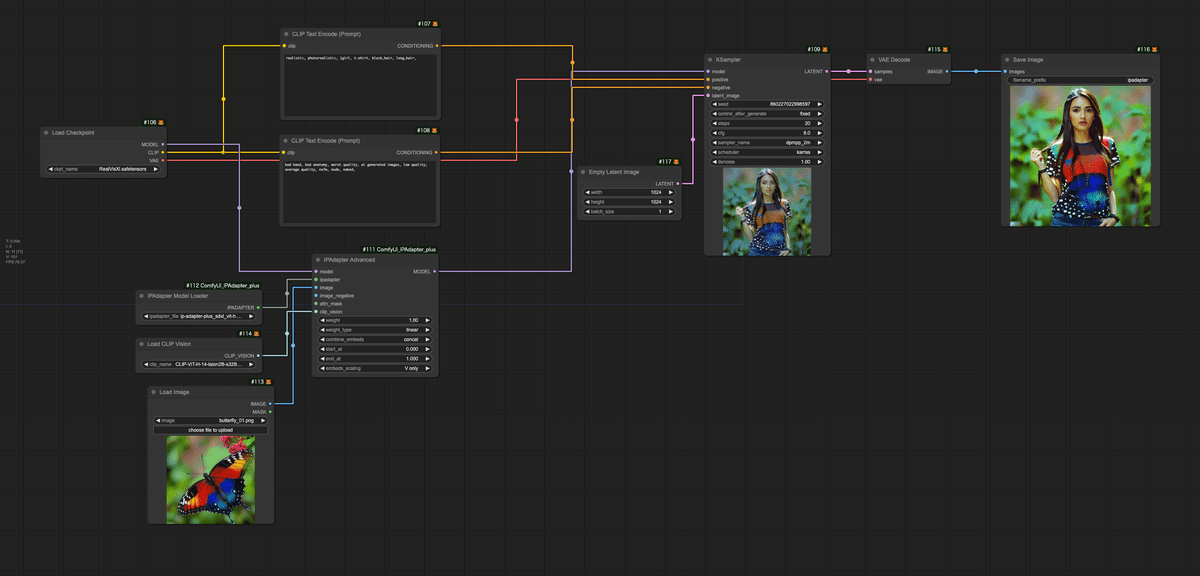
以下がワークフローの全体構成になります。
GPU不要でComfyUIを簡単に起動できる
AICU特製Colabノートブック(ConrolNetつき)はこちら
https://j.aicu.ai/ComfyCN
今回作成したワークフローのファイルは、文末のリンクよりダウンロードください。
以下に、このワークフローの主要な部分とその機能を図示し、詳細に説明します。
入力画像の読み込みと前処理
Load Image ノード: 「butterfly_01.png」という画像を読み込みます。
モデルとIP-Adapterの読み込み
Load Checkpoint ノード: 「RealVisXl.safetensors」モデルを読み込みます。
IPAdapter Model Loader ノード: 「ip-adapter-plus_sdxl_vit-h.safetensors」を読み込みます。
Load CLIP Vision ノード: 「CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors」を読み込みます。
プロンプト処理 (CLIP Text Encode ノード x2)
ポジティブプロンプト: 「realistic, photorealistic, 1girl, t-shirt, black_hair, long_hair,」
ネガティブプロンプト: 「bad hand, bad anatomy, worst quality, ai generated images, low quality, average quality, nsfw, nude, naked,」
IP-Adapterの適用 (IPAdapter Advanced ノード)
入力画像、IP-Adapter、CLIP Visionモデルを組み合わせて、元のStable Diffusionモデルを調整します。
重み: 1.0 (IP-Adapterの最大影響力)
ノイズ追加方法: linear
モード: concat
適用範囲: V only (Value embeddings only)
潜在画像の準備 (Empty Latent Image ノード)
サイズ: 1024x1024
バッチサイズ: 1
画像生成 (KSampler ノード)
Seed: 860227022998597
Steps: 20
CFG Scale: 8
Sampler: dpmpp_2m
Scheduler: karras
Denoise: 1.0 (完全に新しい画像を生成)
画像のデコードと保存
VAE Decode ノード: 生成された潜在表現を実際の画像にデコードします。
Save Image ノード: 最終的に生成された画像を "ipadapter" という名前で保存します。
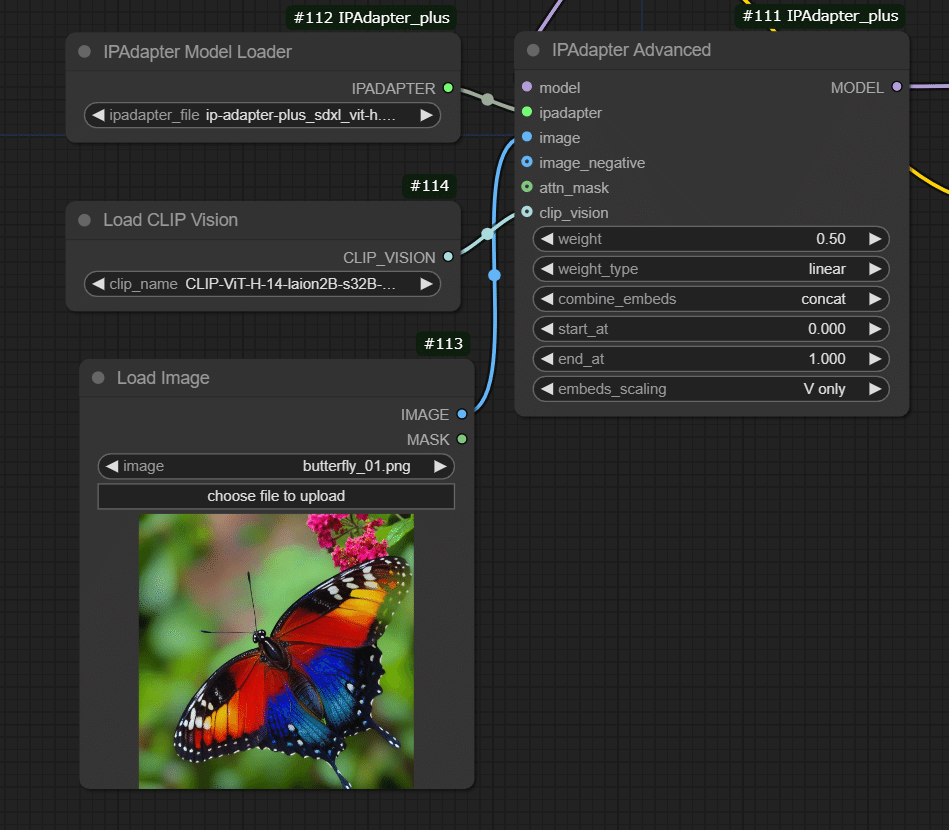
IPAdapter Model Loderと IPAdapter Advancedの拡大です。パラメーターの参考にどうぞ。
5. 生成結果
以下が生成結果になります。左がIPAdapter非適用の画像、右がIPAdapterの強度を0.50で適用した結果です。IPAdapterを適用することで、シャツに学習元である蝶の模様が浮かんだり、背景が自然の風景になっています。

IPAdapter Advancedノードのweight_typeがlinearの場合の強度ごとの生成結果一覧です。0.80になると、蝶が全面に現れてしまい、人物がいなくなってしまいます。

これをweght_typeをstyle transfer、強度を1.0に変更して生成してみました。style transferの場合は、蝶の形状自体は継承しないので、蝶が前面に現れることなく、蝶の模様のみが反映されています。参照元画像のスタイルだけを適用したい場合は、weght_typeをstyle transferにした方が効果的です。
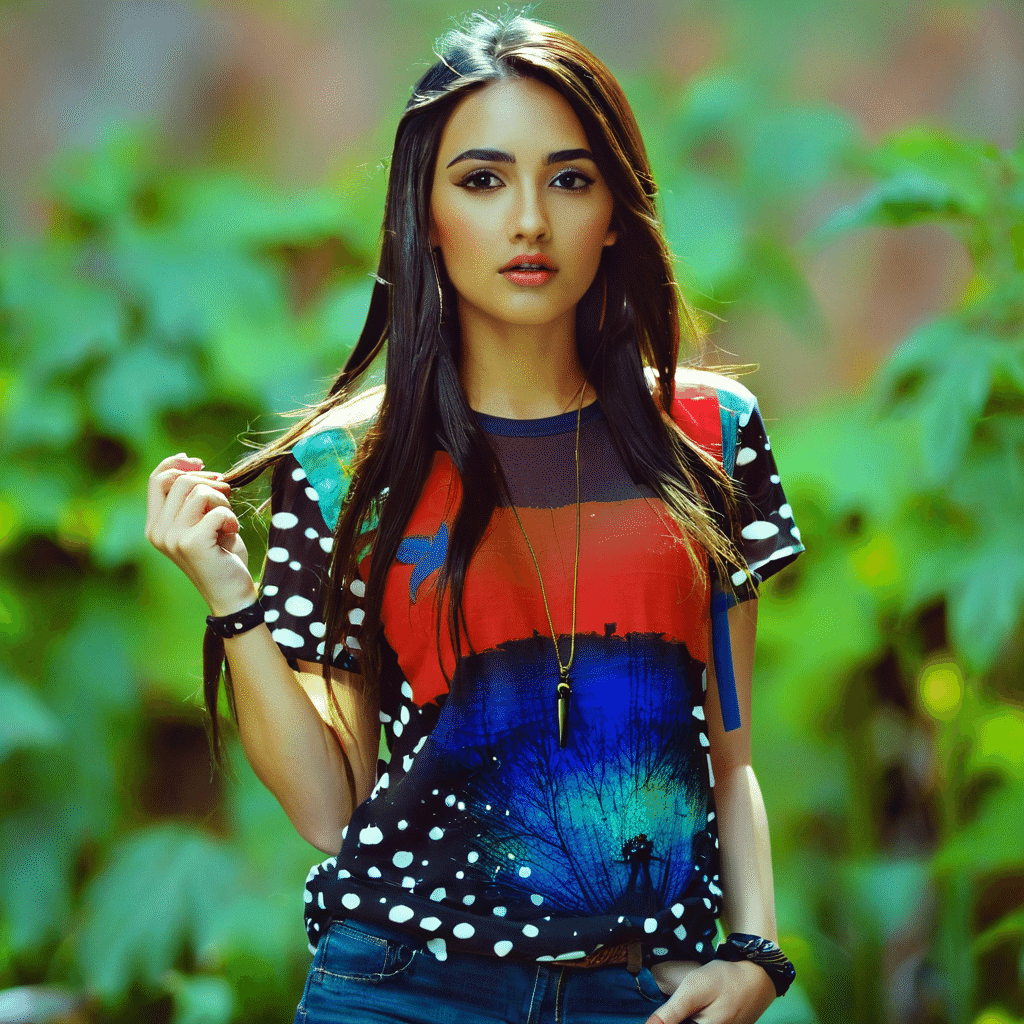
weght_typeがlinearやease_inなどのスタイルと形状の両方を参照させるタイプの用途は、例えば左のパーカーの画像を参照し、右の画像のように生成した人物に着せることが考えられます。しかし、あくまで参照なので、完全に左の洋服を再現することは難しいです。
補足として、右の画像は、weght_typeをease_in、強度を9.5にして生成した画像です。ease_inにすることで、最初はIPAdapterの効きを弱くし、後から効果が上がるようにすることで、プロンプトを反映させつつ、IPAdapterの効果も効かせるようにしています。

6. まとめと倫理面への配慮
本記事では、ComfyUIとIPAdapterを用いて、参照画像に基づいた高品質な画像生成を行う方法を解説しました。IPAdapterは、テキストプロンプトだけでは難しい、微妙なニュアンスや視覚的特徴の再現を可能にします。特に、IPAdapterの強度調整とweight_typeの選択によって、参照画像の要素をどのように反映させるかを細かく制御できることを示しました。linearでは形状とスタイルの両方を、style transferではスタイルのみを、ease_inでは徐々にIPAdapterの効果を強めることで、プロンプトと参照画像のバランスを調整できることを実例を通して確認しました。
これらの技術を活用することで、AIによる画像生成の可能性は大きく広がり、より創造的で自由な表現が可能になります。今後の展望として、更なるモデルの改良や新たなカスタムノードの登場によって、IPAdapterの適用範囲はますます拡大していくことが期待されます。より高度な活用方法の探求や、他のモデルとの組み合わせなど、更なる実験を通して、IPAdapterの潜在能力を引き出し、自身の創作活動に役立ててください。
一方では、「IPAdapter」の名前からも、IP、すなわち知的財産やキャラクタービジネスにとっては、著作権法違反、つまり違法行為や迷惑行為の原因となる技術でもあります。「技術的に出来る/できない」といった視点とは別に、Load Imageにおいて利用する画像の権利や、客観的に見た「依拠性」や「類似性」についても評価を行っておく習慣は大切です。この解説の中でも、weightパラメーターが0.5以上であれば、それは元の画像と同じものに近くなっていきます。パラメータを0.5以上にすることは「原作に対する類似と依拠を同時に認めているという証拠」とも言えますので、画像生成を行う際には、その責任をしっかりと認識して利用してください。
AICUでは画像生成AIクリエイター仕草(v.1.0)といった形で、モラル面も啓蒙活動を行っていますが、IPAdapterの使用についてはより高度な倫理観をもっていくことを推奨します。
次はいよいよLoRA編がはじまります。
そしてその前に、特別編が予定されています!
【特別編】
ここから始める動画編!SDXL+AnimateDiffでテキストから動画を生成しよう!
X(Twitter)@AICUai もフォローよろしくお願いいたします!
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
動画で一気に学びたい方は、こちらのColoso講座もオススメです
ボーナストラック
有料・メンバーシップ向けのボーナストラックには今回解説したワークフローの完成品ダウンロードリンクに加えて、お楽しみ画像です。
某有名漫画家のアシスタントさんに書いていただいた劇画風しらいはかせをIPAdapterに使ったら…!?生成画像を収録しています。
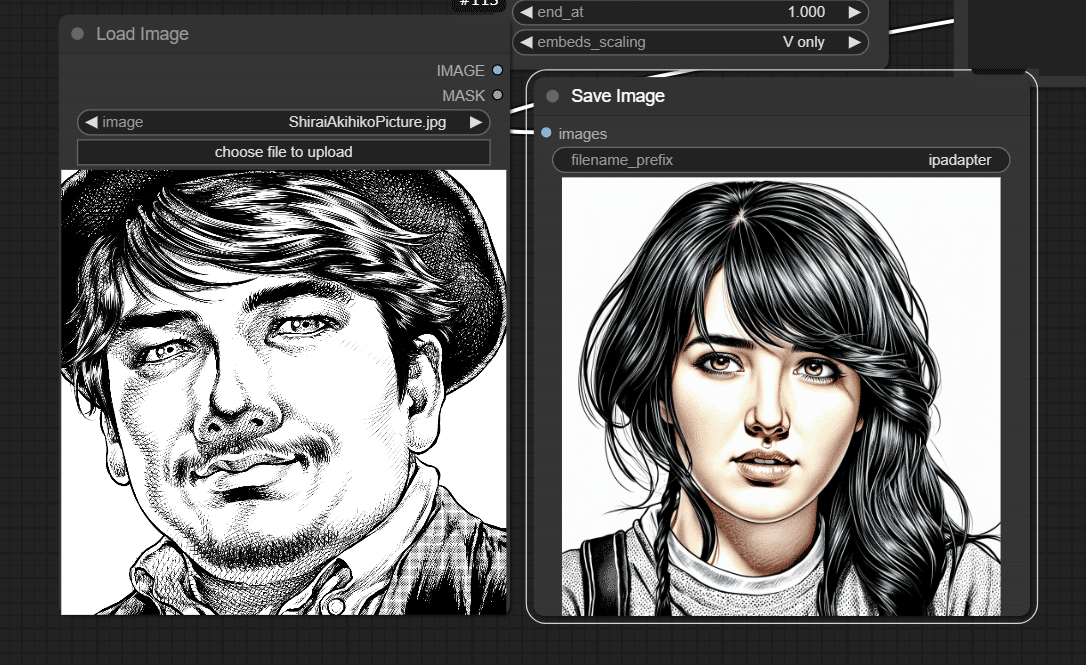
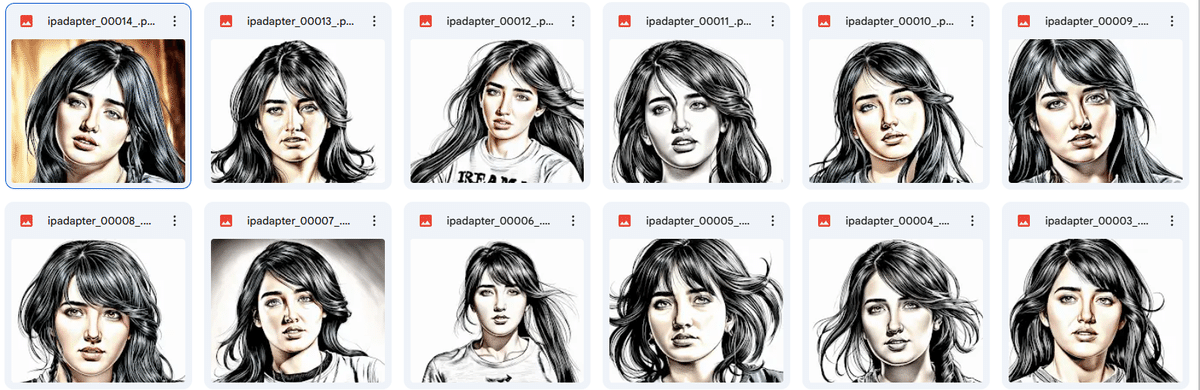
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!