
[ComfyMaster11]ComfyUIでのTextToImageを極める!!(1)プロンプトの基本文法 #ComfyUI

「思い通りの画像を生成したい!けど思うようにいかない…」という方、TextToImage(t2i)を使いこなせていますか?
Stable Diffusionの内部の仕組みを理解し、ComfyUIでのText to Imageテクニックを身につけて、思い通りの画像を生成できるようになりましょう!
こんにちわ、AICU media編集部です。
「ComfyUI マスターガイド」第11回目になります。
この記事では、ComfyUIを始めたばかりの方向けに、「text to image」プロンプトによる画像生成の基本から応用、そしてComfyUI特有のテクニックまでを、実用的なプロンプト例を交えながら数回に分けて解説していきます。
前回はこちら
1. 今回の対象とするモデル
今回は、SDXLを対象にプロンプトテクニックを解説します。特定のモデルに焦点を当てて話す理由としては、プロンプトの書き方や使用するノードがモデルの種類やバージョンにより異なるためです。ここでは、複雑性を減らして解説するために、メジャーなモデルのSDXLを利用します。各種モデルの評価については、別記事にて解説予定です。
ユーザーが知っておくべき「モデルとの対話」について簡単に図解しておきます。

ここからの画像生成では、モデル(checkpoint)としてstable-diffusion-xl-base-1.0を使用します。
メニューから「Manager」を選択します。
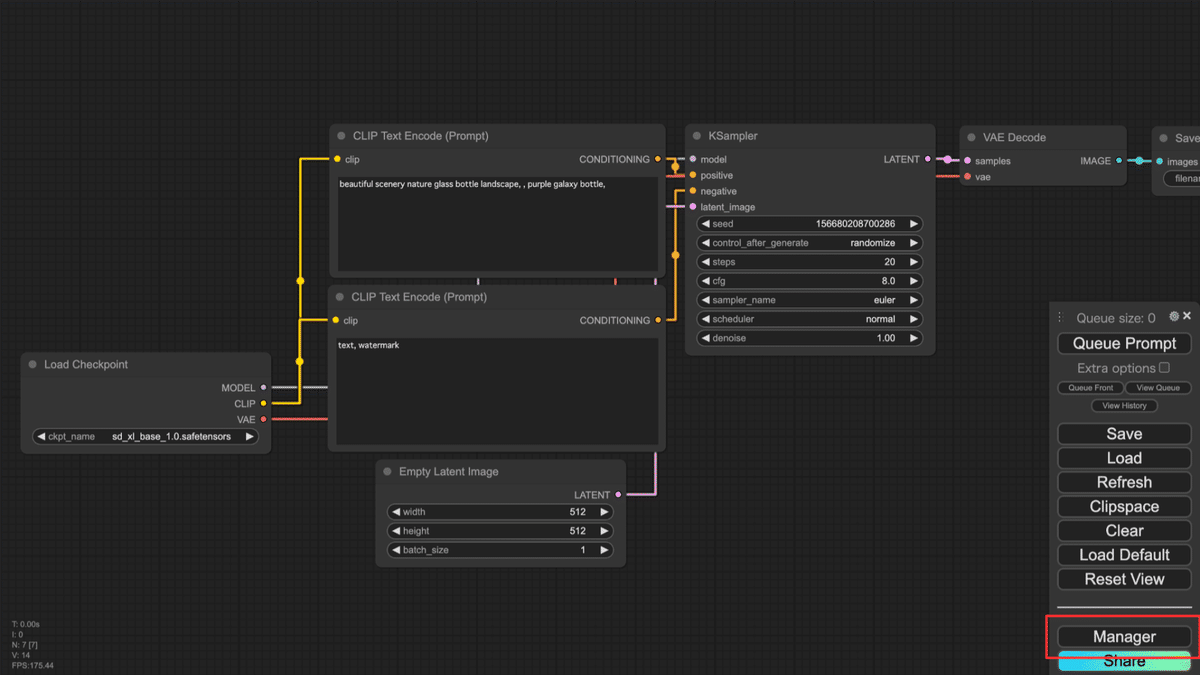
ComfyUI Manager Menuが開きます。ここで「Model Manager」を選択します。

モデルの検索画面が表示されます。
上部の検索バーに「sd_xl_base_1.0.safetensors」と入力すると、モデル一覧にsd_xl_base_1.0.safetensorsが表示されます。
sd_xl_base_1.0.safetensorsの「Install」をクリックしてください。
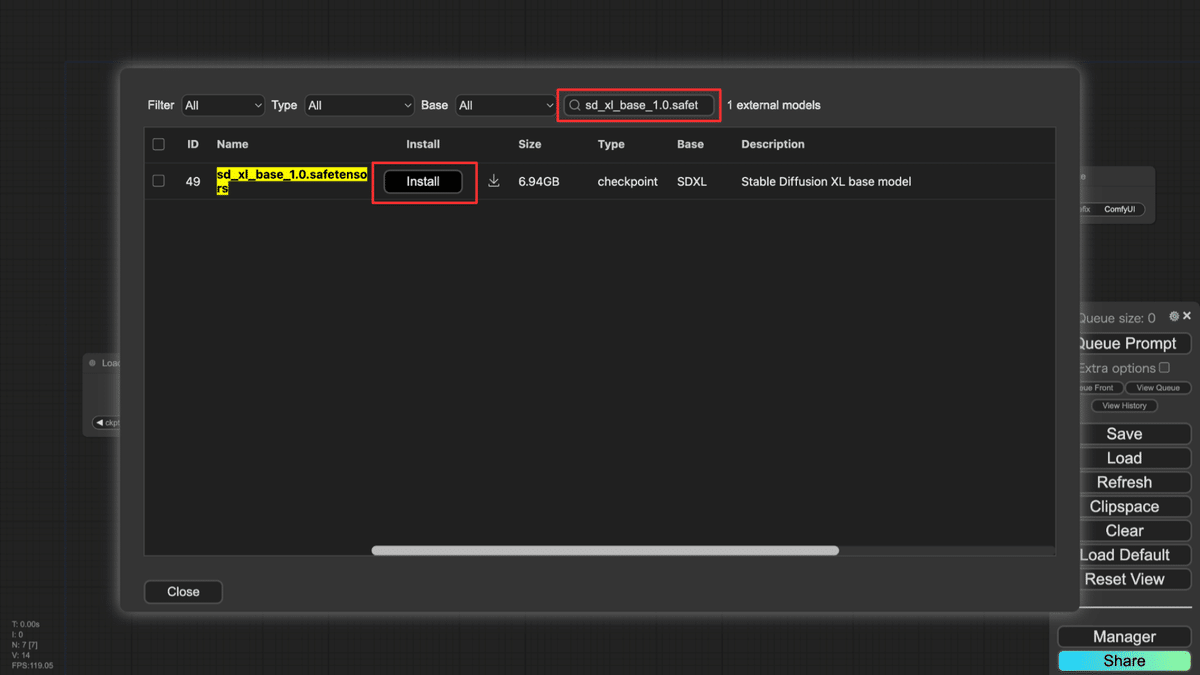
しばらくすると、インストールが完了し、Refreshを求められます。

トップ画面に戻り、メニューの「Refresh」をクリックしてください。
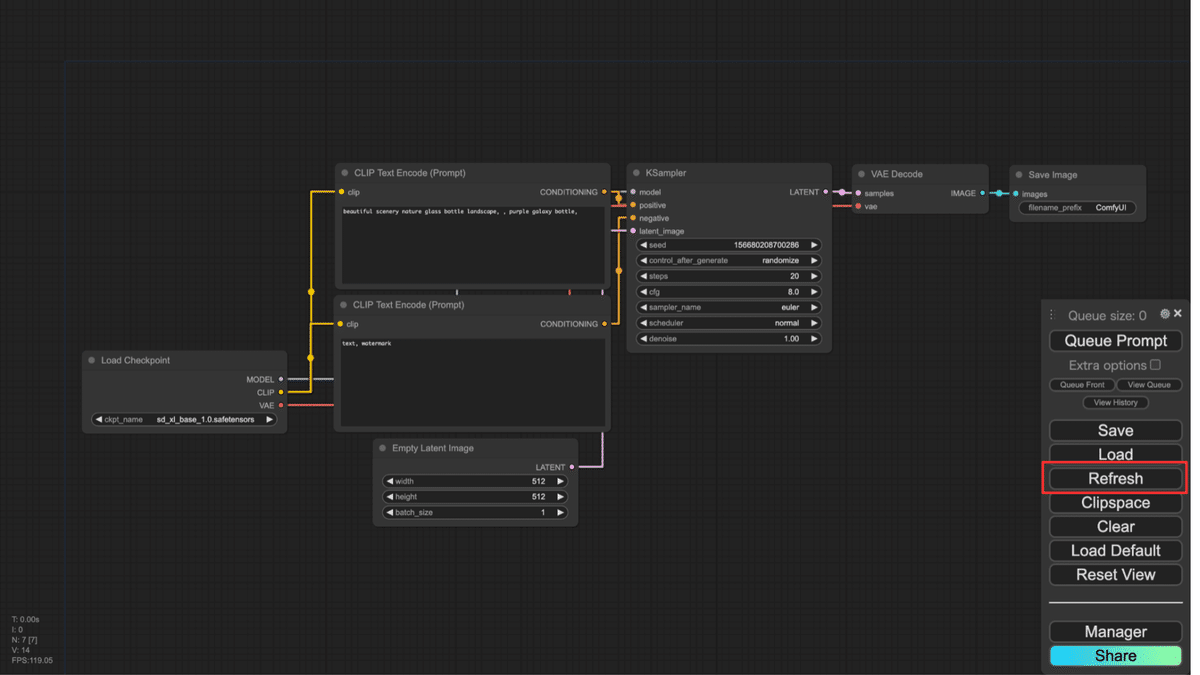
Load Checkpointでsd_xl_base_1.0.safetensorsを設定できるようになります。

2. プロンプトと画像サイズ、シードの基本をおさらいしよう
プロンプトとは、AIモデルに画像を生成させるための指示文のことです。人間が言葉でAIに指示を出すための手段とも言えます。例えば、「夕焼けのビーチで遊ぶ子供たち」というプロンプトを入力すると、SDXLはそのような画像を生成しようとします。プロンプトが具体的であればあるほど、思い通りの画像が生成されやすくなります。
プロンプト例
A photo of a cat wearing a Santa hat, sitting on a Christmas presentこのプロンプトは、クリスマスのプレゼントの上に座っている、サンタの帽子をかぶった猫の写真を生成するようにSDXLに指示します。「Santa hat」や「Christmas present」といった具体的な単語を追加することで、よりクリスマスらしい画像が生成されやすくなります。

画像サイズとシードを固定して実験
[TIPS] SD1.5系からSDXLに切り替えたときは、「Empty Latent Image」を[512, 512]から[1024, 1024]に切り替えるのを忘れずに。SDXLは1024x1024に最適化されているので、生成するLatent画像のサイズが小さいと本来の能力が発揮されません。
なお 1024x1024=1,048,576で必要なピクセル幅で割れば高さが求められますが、例外もあります。特に注意したいのは「16:9」で、割り算するとwidth:1365, height:768が最適…と思いきや、実はSDXL自体がこのサイズで学習をしておらず、推奨の16:9設定は「"1.75": (1344, 768)」、もしくは「"1.91": (1344, 704)」(nearly 16:9)となります。

実験のためにseedを1234, control_before_generateをfixedにして実験してみます。
1368x768 (seed:1234)

1344x768 (seed:1234)

1344x704 (seed:1234)

あんまりわかりやすい違いはありませんが、実用的には以下のようにおぼえておくと良いかもしれませんね!
■ComfyUI SDXLでのHDTV(16:9)最適画像サイズ
1368x768: 非推奨 (AS比1.77) 最適解像度より2,048ピクセル多い
1344x768: 学習済 (AS比1.75) 最適解像度より16,384ピクセル少ない
1344x704: 学習済 (AS比1.91) 最適解像度より102,400 ピクセル少ない。noteカバーアートにぴったりサイズ

AICU mediaでの実験によると、Google ColabのT4 GPU, RAM13GB, GPU RAM 15GB環境でのSDXLにおいて、1344x768、1344x704が平均23秒/生成(1.15s/it)であるところ、1368x768は28秒/生成(1.27s/it)というところです。なおs/itという単位はiterationといって、1ステップあたりの処理時間であるようです。この場合の設定はstep=20なので、ちょうど計算があいます。
生成時間が気になるひとは、ぜひログを見てみてください!

3. 基本的なプロンプトの書き方
SDXLのプロンプトは、基本的に英語で記述します。シンプルな英語で記述しても高品質な画像が生成されますが、より詳細な指示を与えることで、より思い通りの画像を生成できます。
3.1 プロンプトの構成要素
プロンプトは、以下の要素を組み合わせて文章形式で記述します。
芸術スタイル: 画像の雰囲気や画風(例:写真、絵画、アニメなど)
例1: oil painting(油絵)
例2: Pencil drawing(鉛筆画)
例3: Concept art(コンセプトアート)
主題: 描写したいもの(例:猫、風景、人物など)
例1: Lion(ライオン)
例2: Panda(パンダ)
例3: A warrior with a sword(剣を持った戦士)
色とトーン: 画像の全体的な色彩や雰囲気を指定
例1: Vibrant colors(鮮やかな色彩)
例2: Monochrome(モノクロ)
例3: Warm tones(暖かい色調)
ディテールと複雑さ: 画像の細部の精密さや全体的な複雑度を指定
例1: Highly detailed(非常に詳細)
例2: Intricate patterns(複雑な模様)
例3: Minimalist(ミニマリスト)
技術的特性: 画像の技術的な側面や品質に関する指定
例1: High resolution(高解像度)
例2: Photorealistic(写真のようにリアル)
例3: 8K(8K解像度)
プロンプト例
以下にこの構成に従って作成したプロンプトと生成画像を示します。
oil painting, majestic lion, golden sunset hues, Highly detailed, photorealistic, 8K
これらの要素を組み合わせて、より複雑なプロンプトを作成できます。
3.2 単語の区切りと記号
単語は空白で区切ります。
`,`などの記号は、単語区切りとなる場合があります。
プロンプト例
A cat, black and white, sleeping on a red, fluffy rug
3.3 コメント
プロンプトにコメントを追加したい場合は、C言語のような記法が使えます。`//` で行末まで、`/* */` で囲まれた部分がコメントになります。
プロンプト例
A portrait of a man with a beard // ひげを生やした男性の肖像画
/* 年齢は30代くらい */ wearing a suit, photorealistic style

4. プロンプトの強調
特定の単語やフレーズを強調したい場合は、括弧で囲みます。
(単語): 1.1倍強調
例: A portrait of a woman with (green) eyes
((単語)): 1.21倍強調
例: A portrait of a woman with ((long)) blonde hair
(単語:数値): 数値で任意の倍率を指定
例: A landscape with a (bright:1.5) blue sky
プロンプト例
A fantasy landscape with a (red:1.5) castle on a hill, overlooking a vast forestこの例では、「red」が強調され、より赤が強調された描画がされやすくなります。以下の画像は、強調前と強調後の比較画像です。両方とも同じシード値を利用して生成しています。強調後は、全体的に赤くなっており、赤が強調されていることが分かります。


5. ComfyUIでのプロンプト入力
ComfyUIでは、CLIPTextEncodeノードでプロンプトを入力します。このノードは、プロンプトをSDXLが理解できる形式に変換する役割を果たします。
ComfyUIでのSDXL環境では、ポジティブプロンプトとネガティブプロンプトの両方を同じCLIPTextEncodeノードで指定できます。
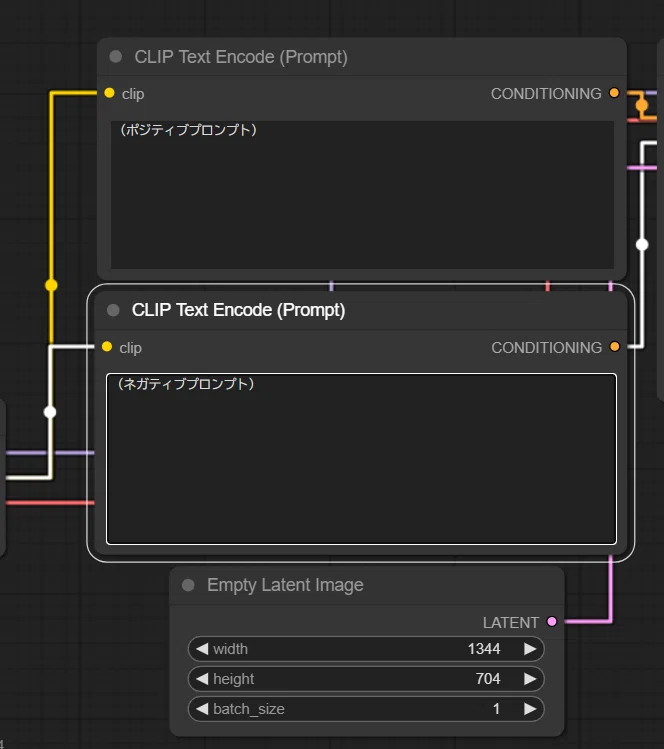
ポジティブプロンプト: 生成したい画像の特徴を記述します。
ネガティブプロンプト: 生成したくない画像の特徴を記述します。
それぞれのプロンプト用にCLIPTextEncodeノードを用意し、KSamplerノードの対応する入力に接続します。詳細は、以下の記事をご覧ください。
6. embeddingでの品質向上
embedding(エンベッディング)は、特定の概念やオブジェクトを表現する埋め込みベクトルを学習したファイルで、非常に小さなファイルなのですが、これをComfyUIで読み込むことで、画像生成の際に特定のスタイルや要素を反映させたり、ネガティブプロンプトを簡略化することができます。
例えば、ネガティブプロンプトをまとめたembeddingを使うと、たくさんのネガティブプロンプトを指定する必要がなくなります。
使用方法
冒頭で紹介した通り、ComfyUI Manager → Model Manager →検索窓に入れる方法でインストールできるものはそちらの方法がオススメです。例えばSD1.5でよく使われる「EasyNegative」は簡単にインストールできます。

今回は、「negativeXL_D」というSDXLで人気の複数のネガティブプロンプトが埋め込まれているembeddingを使用します。ComfyU Manager経由でのインストールではない方法を紹介します。
negativeXL_D.safetensorsをダウンロードし、ComfyUI/models/embeddingsフォルダに格納してください。
このリンクからいったんPC/Macのストレージにダウンロードし、Google ColabかGoogle Driveを使って、アップロードします。
メニューの「Refresh」すると反映されます。「Restart Required」と表示された場合は、ComfyUI Managerからの再起動で問題なく利用できますが、それ以外の問題が起きた場合は、念の為Google Colabを再起動しましょう。
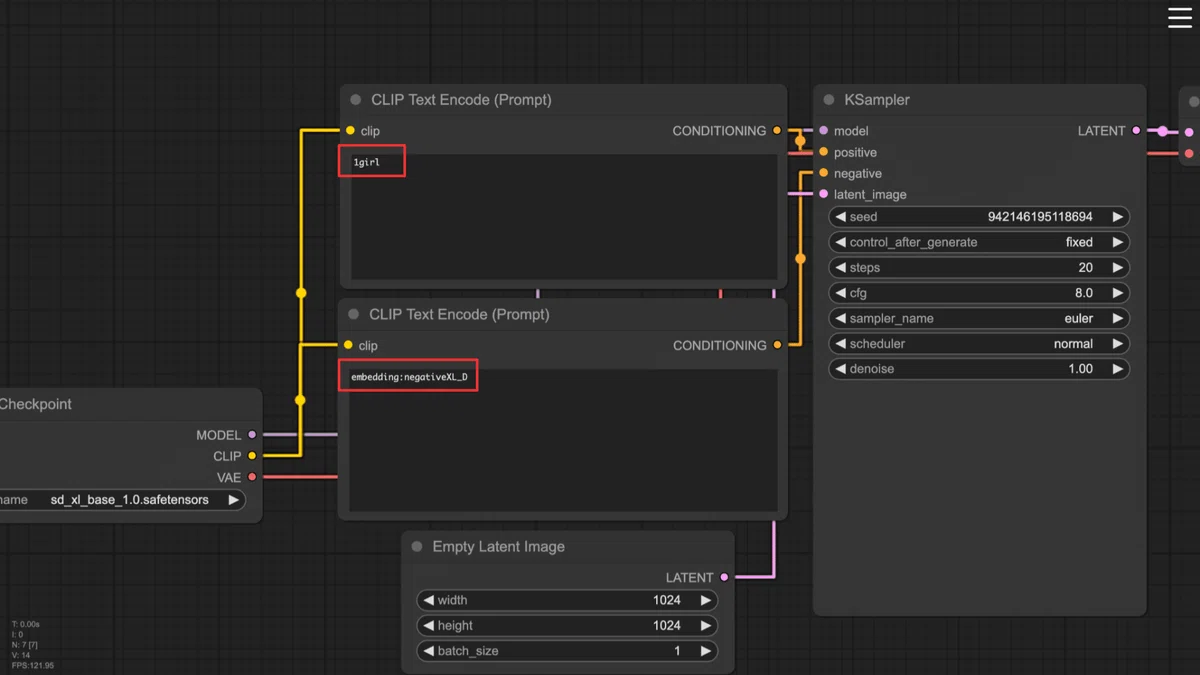
embeddingを使用するには、プロンプトに「embedding:[embeddingの名前]」を含めます。今回の場合は、ネガティブプロンプトに「embedding:negativeXL_D」を含めます。ポジティブプロンプトは「1girl」のみとします。
以下が生成結果です。embeddingありの場合は、リアル調で細部がはっきり描かれています。

1344x704 (seed:3) "1girl"のみ

1344x704 (seed:3) "1girl" + ネガティブプロンプトに「embeddings:EasyNegative」を指定

1344x704 (seed:3) "1girl" + ネガティブプロンプトに「embeddings:negativeXL_D」を指定

1344x704 (seed:3) "1girl" + ネガティブプロンプトに「embeddings:EasyNegative, embeddings:negativeXL_D」を指定

EasyNegativeとnegativeXL_Dは同じ作者・rqdwdw 氏によるembeddingsであり、近い特性を持っていますが、混ぜて使うことは必ずしも良い結果を産まないようです。¥
AUTOMATIC1111では「Textual Inversion」という機能で扱われていたembeddingですが、かつてのテクニックもモデルさえ同じであればそのまま使うことができます。 embedding、negative XLについての混合実験についてはこちらの記事もご参照ください。
中間まとめ
この記事では、ComfyUIでSDXLのプロンプトを記述する基本的な方法をまとめました続いて、応用的なテクニックを紹介していきます。
<次回に続きます!>
X(Twitter)@AICUai もフォローよろしくお願いいたします!
SDXLによる画像生成AIについてしっかり学びたいひとはこちらの書籍「画像生成AI Stable Diffusionスタートガイド」(通称「#SD黄色本」)がオススメです。
画像生成AI「ComfyUI」マスターPlan
画像生成AI「Stable Diffusion」特に「ComfyUI」を中心としたプロ向け映像制作・次世代の画像生成を学びたい方に向けたプランです。最新・実用的な記事を優先して、ゼロから学ぶ「ComfyUI」マガジンからまとめて購読できます。 メンバーシップ掲示板を使った質問も歓迎です。
メンバー限定の会員証が発行されます
活動期間に応じたバッジを表示
メンバー限定掲示板を閲覧できます
メンバー特典記事を閲覧できます
メンバー特典マガジンを閲覧できます
動画資料やworkflowといった資料への優先アクセスも予定
ゼロから学ぶ「ComfyUI」マガジン
マガジン単体の販売は1件あたり500円を予定しております。
2件以上読むのであればメンバーシップ参加のほうがお得です!というのもメンバーシップ参加者にはもれなく「AICU Creator Union」へのDiscordリンクをお伝えし、メンバーオンリー掲示板の利用が可能になります。
もちろん、初月は無料でお試しいただけます!
毎日新鮮で確かな情報が配信されるAICUメンバーシップ。
退会率はとても低く、みなさまにご満足いただいております。
✨️オトクなメンバーシップについての詳細はこちら
ここから先は

応援してくださる皆様へ!💖 いただいたサポートは、より良いコンテンツ制作、ライターさんの謝礼に役立てさせていただきます!