
オジサンでもできる!画像と言語のAIでビジネスハッカソンした(2)

「つくる人をつくる」をビジョンに活動している AICU(アイキュー)社の社内ビジネスハッカソン、後編です。
▶AICU社で人気!VIP向け生成AIワークショップ
前回の続き:Japanese Stable VLMとJapanese Stable CLIPの違い
最近 Stability AI からオープンにリリースされた画像言語モデルには、「Japanese Stable VLM」(以下略称JSVLM)と「Japanese Stable CLIP」(以下略称JSCLIP)があります。その違いは以下の通りです。
Japanese Stable VLM [JSVLM]:一つの画像から、それを適切に表現する「日本語の説明」が欲しいときに使う。
Japanese Stable CLIP [JSCLIP]:数多くの画像から、日本語の指示で一つを選択するときに使う。
実際のユースケースを考えながら実験して比べてみることで、いろいろわかることがありました。
JSCLIP は 速くて軽い。
ただし事前にクラス指定が必要。
Google Colab を使った実験コードと初心者向けの入門解説は前編にて。
ソースコードはこちらです(Stability AI公式版)
https://colab.research.google.com/github/Stability-AI/model-demo-notebooks/blob/main/japanese_stable_clip.ipynb
VRAMは2.2GBぐらいで動いているので特に強めのGPUは必要ないかもしれません。

公式のJSCLIPのサンプルでは以下のようにカテゴリーを設定されています。

この「配達員, 営業, 消防士, 救急隊員, 自衛隊, スポーツ選手, 警察官」の部分を検索したい日本語テキストにすることで、それぞれの画像にどれぐらいの可能性が含まれているか、横断的に調査することができます。
これを画像分類用語では「クラス(class)」と言います。画像分類(classification)のことですね。
なのでデフォルト状態で実行すると、こんな感じに「スポーツ選手」になってしまいます。

これを変更し、{ニュース、アニメ、写真、英語、ポスター}などを加えてスクリプトを再起動します。具体的には
Prepare for the demo のカテゴリーを修正して保存(Ctrl+S)、この「Preparation for demo」セルの動作とその下の「Launch the demo」セルの動作を止めて、再度▶を押して実行します。続いて、「Launch the demo」▶を押して、表示されるGradioのURLに行き、WebUIから操作します。

ニュースとアニメであることが判定されました。あってますね!

⑥画像内の言語を分類する
日本語に詳しいCLIPを使って、画像内のテキストが何語で書かれているのかを推論させることができそうです。
一般的な画像分類のタスクでは、クラスの数が多すぎると精度や速度に影響がありますので、少しでも精度を上げるためにクラスを「英語」と「日本語」の2択にしてみます。



⑦ニュース画像分析によるSNS運用の知能化
前回紹介したVLMを使うと未知の画像に対して、事前学習なしに分類を行うことができますが。VSCLIPのこの機能を用いると、さらに目的の画像だけを高速に分類して検知することができそうです。
例えば 弊社AICU社のX(Twitter)@AICUai はPRTIMES社からのニュースリリースから「生成AI」に関係のあるニュースを取得してデータベースを構築し、日本企業での生成AIでのビジネス活用事例を海外に紹介するツイートを自動生成しています。日本の最新ニュースをリリースから即時に海外発信できています。
しかしニュースのサムネイル画像が配信すべき画像なのかどうか?IT関係の画像が含まれているか?海外向けに翻訳すべき画像はどれか?どれぐらい日本語が含まれているか?といった判定はまだ行っていません。この分類にVSCLIPを利用できるかもしれませんね。
これはそのうち実装してみたいと思います。
⑧コンテンツ生成と編集
JSCLIPを他のモデルと組み合わせることで、日本語のテキストから画像を生成する text-to-image タスクや、画像からテキストを生成するimage-to-textタスクに拡張することが可能です。実際、Stable Diffusionの内部ではCLIPが使用されているようです。
■日本特化の商用利用可能 text-to-image モデル「Japanese Stable Diffusion XL」をリリースしました(Stability AI Japan)
https://ja.stability.ai/blog/japanese-stable-diffusion-xl
■日本特化型画像生成AI「JSDXL」で和風画像の魅力を探求してみた!(窓の杜「生成AIストリーム」)
https://forest.watch.impress.co.jp/docs/serial/aistream/1549760.html
⑨メディア分析
対話的なJSVLMと異なり、存在する画像のもっともらしさを出力することができるのもJSCLIPの特徴です。
クラスを「男」「女」にしてみました。

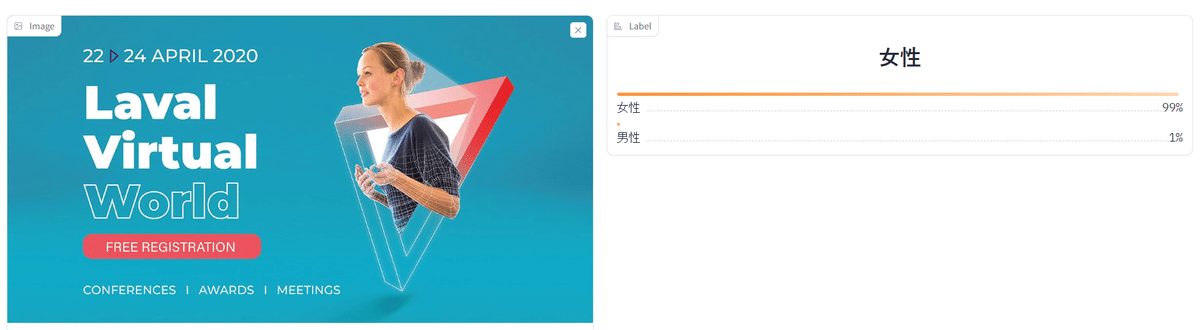

同じ広告ですが「男/女」というクラスで分類ができました。他にも「男性向け」というキーワードでも実験してみたのですがなかなか興味深いです。つまり特定の性別向けの広告も出来ますし、ジェンダーに配慮した、ジェンダーニュートラルな広告を評価する手法としても可能性がありそうです。
これに先程の⑥で実験した言語分析を組み合わせたり、画像とテキストの両方を組み合わせたデータを分析し、より横断的に多くの情報を抽出することができます。これは、市場調査、メディア分析、教育研究などに有用ではないでしょうか。例えばAmazonの書棚に置かれている書籍のタイトルと、カバー画像を指定のキーワードで分類し、売れ行き順に調査してみたり、年代ごとのデザインモチーフを分析してみたり…。もちろん書籍だけではありません。社内の資料の検索や、⑦で提案したSNSをへの投稿画像の生成や、キュレーションにも使えそうです。
⑩障害者支援
高速で軽量なJSCLIPとJSVLMを並列して使用し、視覚障害者のための支援ツールとしてインクルーシブなツールをつくれるかもしれません。例えば、「車」や「信号」といった安全に関係する情報を優先して判定させ、特に注目して状況を分析してみたい状況でJSVLMを使って画像に含まれる情報を日本語のテキストで説明したり、音声で説明したりすることができます。これを店舗で活躍するサービスロボットに実装することで、障害者支援だけでなく、さらに幅広い方々への用途が生まれます。さらに多様なモダリティを活用すると、ファインチューニングされた点字のための画像を、実画像から点字ディスプレイに変換して表示するようなツールがつくれるかもしれません。このような研究は視覚障害者だけでなく、弱視者やお年寄りといったより幅広い方々にアクセスしやすいコンテンツ、つまり「視覚を使えない方が向けに指で読むテレビ」といった応用を提供することができます。近いコンセプトでの筑波大学・落合陽一らの研究が最近の国際会議「SIGGRAPH2023」で発表されていましたので紹介します。
Text to Haptics: Method and Case Studies of Designing Tactile Graphics for Inclusive Tactile Picture Books by Digital Fabrication and Generative AI
このケーススタディでは、コンピュータグラフィックスコミュニティにおける包括性のための生成AIと触覚グラフィックスとの可能性を探求します。触覚グラフィックスの設計に生成AIを使用することで、出版社や触覚グラフィックスデザイナーによって使用されるプロセスをサポートすることが可能になりました。さらに、3Dプリンターを用いたデジタルファブリケーション技術によって、透明シート上に触覚グラフィックスを印刷するというアイデアは、視覚障害者と視覚を持つ人々が一冊の絵本で一緒に読んで楽しむことができる包括的な触覚絵本の創造を可能にします。
https://digitalnature.slis.tsukuba.ac.jp/2023/08/dng-in-siggraph-2023/
まとめ
以上、2回に渡ってStability AIがリリースした2つの画像言語モデル、JSVLMとJSCLIPについて、その違いを比較しながら10個のビジネスアイデアとともに想定されるユースケースをご紹介しました。これらのモデルは日本語対応していることが特徴で、それぞれ異なる特性と機能を持ち、多様なタスクに活用できる「宝の山」であることが感じられたようであれば幸いです。
しかも、Stability AI社は日本での開発チームを持ち、非常に速いペースでオープンな「画像-言語モデル」を公開しています。もちろん上記のアイディアに限らずですし、実際に作ってみるといろいろな難度の高い課題も発見されると思います。
Keywords
References
※本記事は Stability AI社の協力に基づきAICU社が製作しております。
AICU(アイキュー)は「つくる人をつくる・わかるAIを届ける」をビジョンとしている、デジタルハリウッド大学発の米国スタートアップ企業です。生成AIに関する国際的なニュース・調査・社会理解のための情報発信、生成AIのクリエイティブな使い方TIPS、優しい用語集や書籍開発、エンターテイメント分野や、Stability AI社などの生成AIにおける世界トップ企業とのコラボレーションによる、プロフェッショナルビジネスへの応用ツール開発、社内展開ワークショップ、AI活用ハッカソンなどを展開しております。共同研究・受託開発・インターンなどお問い合わせやご相談はお気軽に X@AICUai までどうぞ。
この記事が気に入ったらサポートをしてみませんか?