
【SDWebUI】A1111のインストールと基本的な使い方!(txt2img編)

今からStable Diffusionで画像生成AIを始めたいという方に向けて、Stable Diffusion Web UI AUTOMATIC1111(以下A1111)の使い方をご紹介します。
※以前有料記事でしたが、既に出回っている情報が多いので無料公開にしました。
■プロフィール
自サークル「AI愛create」でAIコンテンツの販売・生成をしています。
クラウドソーシングなどで個人や他サークル様からの生成依頼を多数受注。
実際に生成した画像や経験したお仕事から有益となる情報を発信しています。
詳細はこちら(🔞コンテンツが含まれます)
➡️lit.link
メンバーシップ(月額500円)に加入して頂くと、300円以下の有料記事は読み放題です。
Stable Diffusionとは?
Stable Diffusionは、2022年に生まれたテキストから画像を生成する技術です。
このStable DiffusionをUIで簡単に操作できるようにしたのが、A1111のようなツールになります。
最近ではUIも幅広く登場しており、Forge、ComfyUI、Fooocus、SwarmUIなど種類はさまざまです。
今回はStable Diffusionが生まれてから、おそらく一番最初にUIとしてリリースされたA1111の使い方についてご紹介します。
A1111のインストール方法
A1111のインストール方法は2つあります。
①パッケージ版でインストール
②git・pythonでインストール
①パッケージ版でインストール
A1111にはワンクリックでインストールできるパッケージ版が配布されています。
以下のページからsd.webui.zip をダウンロードして、任意のフォルダに置いてください。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
日本語が含まれない場所の方がエラーリスクを軽減できます。
解凍したら中にあるupdate.batを起動してください。
アップデートが実行されるので終わったら画面は消してOKです。
次にrun.batを起動すれば、自動で必要なものがインストールされます。
終わるとUIが自動的に開くので、これでインストールは完了です。
2回目以降もrun.batで起動できます。
②手動インストール
予めgitとpythonを用意して手動でインストールする方法です。
・git for windowsのインストール
Git for Windowsは、オープンソースのバージョン管理システムであるGitをWindows環境で使用できるようにするためのツールです。
これによりGithubにあるツールをローカルで使用したりできます。
1.Gitのダウンロード
Git for Windowsの公式サイトにアクセスし、「Download」ボタンをクリックしてインストーラをダウンロードします。
2.インストーラの実行
ダウンロードしたインストーラ(Git-<version>-<bit>-setup.exe)をダブルクリックして実行してください。
3.インストールウィザードの設定
インストーラが起動したら手順に従ってインストールを進めます。
全てデフォルトのままNextで問題ありません。
4.インストールの完了
インストールが完了したら、「Finish」ボタンをクリックしてインストールウィザードを終了します。
pythonのインストール
pythonはオープンソースのプログラミング言語です。
pythonで書かれたコードを実行するためにインストールが必要になります。
1.pythonのダウンロード
Pythonの公式サイトにアクセスし、ページ下部にある「Windows installer (64-bit)」をダウンロードします。
A1111の推奨バージョンが3.10.6なのでそちらのリンクを貼っています。
githubのページにある「Python 3.10.6」というリンクからもダウンロード可能です。
https://github.com/AUTOMATIC1111/stable-diffusion-webui?tab=readme-ov-file#automatic-installation-on-windows
2.インストーラの実行
ダウンロードしたインストーラをダブルクリックして実行します。
3.インストールウィザードの設定
インストーラを起動したら「Add Python to PATH」にチェックを入れてください。
これにより、Pythonコマンドをコマンドプロンプトから直接実行できるようになります。
「Install Now」をクリックして進めれば、インストールは完了です。
gitとpythonがインストールできたらA1111をローカルにクローンします。
A1111をインストールしたいフォルダの空白で右クリック→ターミナルを開くを選択してください。
ターミナルが表示されるので、以下のコードを実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitそうするとstable-diffusion-webuiというフォルダができるので、中にあるwebui-user.batを起動します。
これで必要なものがインストールされ、終わるとUIが自動で開きます。
2回目以降もwebui-user.batで起動可能です。
インストール方法による主な違い
主な違いはpythonとgitがシステム全体で使えるかどうかです。
パッケージ版は、UIを使うためだけにpythonとgitがインストールされます。ですので、システム全体で使えるようにパスが通っていません。
一方でpython・gitを手動インストールする場合は、パスを通すオプションがあるので、最初からシステム全体で使えるように設定できます。
なお、パッケージ版でも別verのpythonをインストールしたり、手動でパスの設定をしたりはできるので、そこまで大きな違いはありません。
ただ出回っている情報は手動インストールしたA1111の解説が多く、データを置くパスなどがパッケージ版と若干異なります。
将来的にA1111以外のpythonツールを動かしたり、ターミナルの操作に慣れたりしたい方は、手動インストールの方がおすすめです。
A1111の基本的な使い方
とりあえず画像生成してみる
起動するとこんな画面が表示されます。

一番上のプルダウンはモデルを選択する場所です。
使用モデルによって生成できる画像の種類やテイストが大きく変わります。
最初なのでデフォルトで追加されるRunwayのSD1.5モデルをそのまま使ってみます。
その下の入力欄は生成する画像をテキストで制御できるものです。
基本は英単語をカンマで区切り、上のpromptには生成したいもの、下のnegative promptには生成したくないものを入力します。
例)
prompt:fish, in the sea, fantastic
negative prompt:low quality, normal quality, worst quality
negative promptに入れているのは、低クオリティの画像を避けるためのものです。

入力し終わったら、Generateボタンで画像生成ができます。
・生成した画像

生成した画像は以下のパスに保存されます。
stable-diffusion-webui\output・パッケージ版はこちら
sd.webui\webui\outputsプロンプトの基礎
プロンプトでは括弧や値を使うことで、要素の強弱やステップ数を指定することができます。
・丸括弧
赤という色を強調したい場合、(red)のように丸括弧で囲むとより強く反映させることができます。
括弧を増やすと効果が強くなります。例)((((red))))
倍率を数値で指定することも可能です。例)(red:1.2)
手入力ではなく、プロンプトを選択した状態でCtrl+上下キーでも値の増減ができます。
・この状態

・角括弧
丸括弧と逆で特定の要素を弱めることができます。
[red]
[[[[red]]]]
[red:1.2]
・プロンプトの切り替え
これはSTEPの中で使用するプロンプトを切り替えられるものです。
Sampling Stepsが20だと、20回の工程を経て画像を生成します。
[red:black:10]のように入力すると、STEP10まではred、STEP11からはbalckというような切り替えが可能です。
・AND
大文字のANDを使うと二つの要素を融合させることができます。
例えば「apple AND chair」と入力すると、りんごと椅子を融合したような画像が生成できます。
・BREAK
BREAKはプロンプトを区切って、他の要素と干渉させにくくするものです。
例えば髪色をblack hair、服の色をred clothesのようにした場合、お互いの色が混ざってしまう場合があります。
これを防ぐために「black hair, BREAK red clothes」のようにすることで、色の干渉を防ぐ効果が得られます。
なお、プロンプトは75トークンで1つのチャンクとしてカウントされます。
1トークンはプロンプト1つのことで、チャンクはプロンプトを分割して処理できる単位です。
75トークン以上になると自動的にチャンクが2つに分かれます。
プロンプト入力欄の右上を見ると、75を超えたタイミングで分母が増えているのがわかると思います。

このチャンクを任意の場所で分割できるのがBREAKです。
75トークンに届いていなくても、BREAKを使うとその時点で分母が増え、チャンクが2つになります。

一般的に似たカテゴリのプロンプトを1つのチャンクに入れて、分割する方が多い印象です。
例)人物像, BREAK 服装, BREAK ポーズ, BREAK 背景・シチュエーション
プロンプトの組み合わせや使い方は人それぞれなので、いろいろ試行錯誤してみてください。
各パラーメータの意味
txt2imgで設定できるパラーメータについて解説します。
・Sampling method
Sampling methodは、ノイズを除去するアルゴリズムを選べるものです。
それぞれどんな画像が生成できるか画像付で比較してくれている記事があったので、詳細はこちらをご確認ください。
・Sampling steps
Sampling stepsはノイズを除去する工程を何STEPで行うかです。
STEP数が多いと高クオリティで鮮明な画像になると言われていますが、その分処理が長くなります。
個人的には増やしてもそこまで差があるように感じられなかったので、20~30くらいで良いかなという印象です。

・Hires. fix
Hires. fixは高画質化処理ができる機能です。
チェックを入れて生成すると、画像を高画質化できます。
左:Hires. fixなし
右:Hires. fixあり

また高画質化する上で使用するアップスケーラーやステップ数を指定できます。
・Upscaler
Hires.fix処理に使用するアップスケーラーを選択できます。hires.fix使用時の結果に影響します。
・Hires steps
Hires.fixを何ステップで処理するかです。0だとSampling stepsと同じstep数になります。
・Denoising strength
ノイズを除去する強度です。強すぎると画像が破綻、または変化します。0.4~0.6辺りで使用している方が多い印象です。
・Upscale by
画像を何倍にアップスケールするかです。画像サイズが512×512でUpscale byを2にすると1024×1024で仕上がります。またResize width to、Resize height toのスライダーを動かすと任意のサイズを指定できます。
・Refiner
途中で使用するモデルを切り替えることができるものです。
チェックを入れるとON。
chackpointで切り替えるモデルを選択、Switch atで切り替えるタイミングを指定できます。

SDXLがリリースされたときに、ベースモデルで生成した画像をRefinerモデルで仕上げるという仕様だったため、この機能が実装されました。
ただ現在はSD1.5もSDXLもベースモデル単体で動かせるものがほとんどなので、あまり使う機会はないかもしれません。
一応ベースモデルに別モデルのテイストを入れるという使い方もできますが、そこまで大きな変化は得られなかったです。
画像はベースにAnyLoRA、Refinerにawpaintingを設定して、Switchごとに比較したもの。

もし別モデルの特徴を出したいのであれば、i2iなどで処理した方がしっかり反映されると思います。
・Width・Hight
Widthは画像の横幅、Hightは画像の縦幅です。
・Batch count
生成する画像枚数を指定できます。
2の場合、1枚ずつ処理して2枚生成します。
・Batch size
一度に生成する画像枚数を指定できます。
2の場合、一度の処理で2枚生成します。
・CFG Scale
生成される画像がプロンプトにどの程度従うかを制御できます。
使用プロンプト:1girl, shcool uniform, class room, smile, portrait, POV

・Seed
シード値はランダム性を制御するものです。
デフォルトの-1だと生成するごとにランダムの値が付き、それぞれ異なる画像が生成されます。
付与されたシード値を使って生成すると同じ画像を生成できます。
過去に生成した画像や、ネット上でメタデータが公開されている画像を再現するときに必要です。
モデル(checkpoint)の入れ方
モデルは画像生成の元となるデータです。
これにより生成できる画像の種類やテイストが大きく変わります。
主にCivitaiかHugging Faceを利用している方が多いです。
・Civitai
CivitaiはStable Diffusion関連のさまざまなデータが置いてあるサイトです。
サムネイルを見ながら探すことができるので、初心者の方はこちらの方がわかりやすいかもしれません。
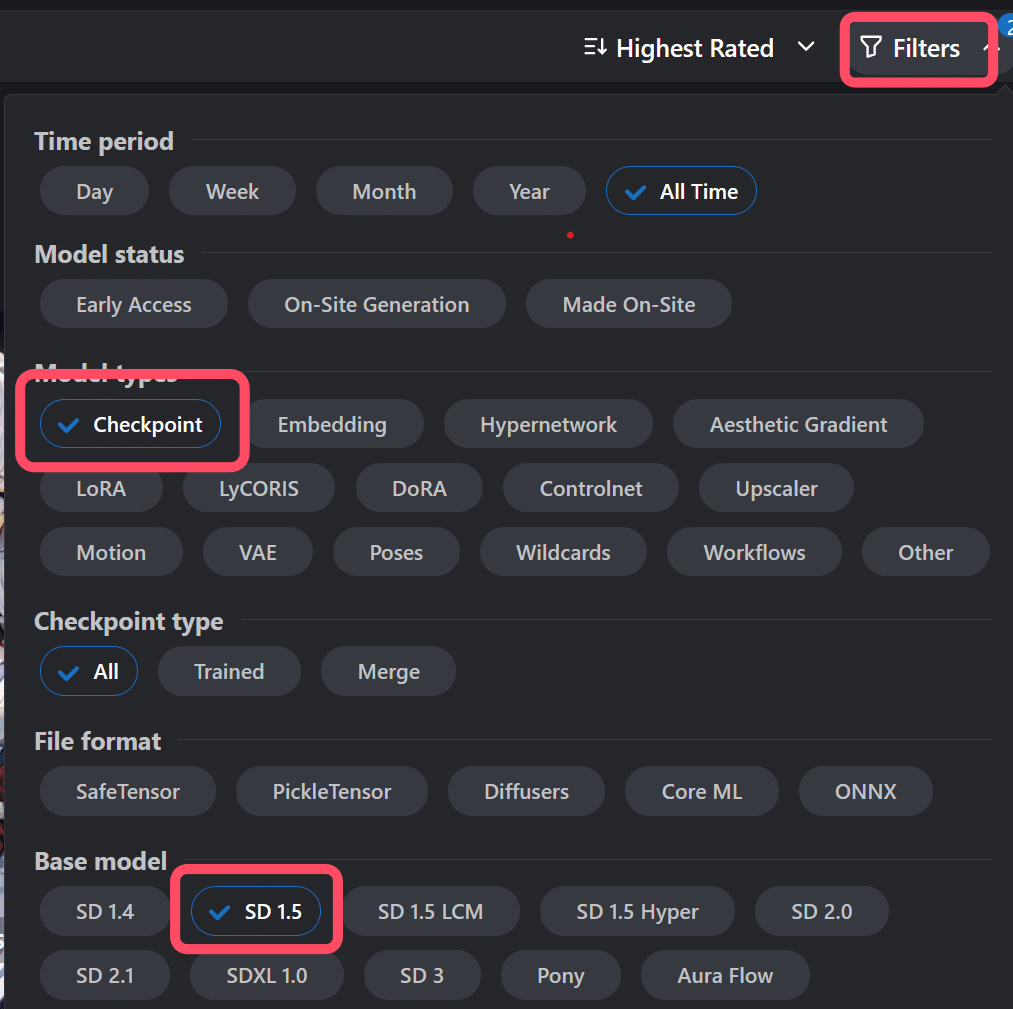
モデルはページ上部にあるModelsカテゴリで表示が可能。

右上のフィルターを使えば、バージョンに合わせてモデルが絞り込めます。
最初なのでデフォルト設定で使えるSD1.5のものがおすすめです。
使いたいモデルを見つけたらそのページを開き、ダウンロードボタンから落とせます。

なお、R18のイラストやモデルを閲覧するには会員登録が必要です。
右上のsign inからSNSアカウントなどでログインできます。
・Hugging Face
Hugging Faceも基本的に使い方は一緒です。
上部メニューのModelsから一覧が表示できます。

Stable Diffusionはテキストから画像を生成する技術なので、Computer VisionからText-to-Imageを選択すれば対応するモデルが右側に表示されます。
モデル名がわかっていればキーワードで絞込も可能です。


リアル系で有名なChilled remixなどは、Hugging Faceからダウンロードできます。
Files and versionsのページに移動して、モデル名「chilled_remix_v2.safetensors」の右側にある矢印ボタンからダウンロード可能です。

なお、Hugging FaceはサムネイルやCheckpointだけを表示するフィルターがないため、0から探すとどのファイルがどんなモデルか少しわかりにくいです。
ですので、Hugging Faceで直接探すよりは、モデルを紹介しているサイトなどを経由した方が見つけやすいかもしれません。
モデルは以下のパスに置いてください。どちらのサイトから落としても置く場所は一緒です。
stable-diffusion-webui\models\Stable-diffusion・パッケージ版
sd.webui\webui\models\Stable-diffusionUIを再起動、または更新ボタンで更新すると、モデルが使用できるようになります。

こちらの記事でも解説しているのでよかったら参考にしてください。
VAEの入れ方
VAEは変分オートエンコーダと呼ばれるもので、使用すると画像のモヤが消えたり、鮮明になったりする効果があります。
いくつか種類があり、使用するものによって効果はさまざまです。
モデルと同じようにCivitaiやHugging Faceで探すことができ、代表的なものだと「vae-ft-mse-840000-ema-pruned.safetensors」というものがあります。
VAEのデータは以下のパスに入れてください。
stable-diffusion-webui\models\VAE・パッケージ版
sd.webui\webui\models\VAEWeb UI上でVAEを切り替えたい場合は、Settingページで表示設定ができます。
左メニューの検索窓に「Quicksettings」と入力、Quicksettings listにVAEと入力してsd_vaeを選択します。

上部にあるApply Settingsで保存し、Reload UIで再起動してください。

そうするとCheckpointの横にVAE用のプルダウンメニューが表示されます。

ちなみにAutomaticは自動で最適なVAEが選ばれるという機能ではなく、Checkpointと名前と一致した場合にVAEが適応されるというものです。
任意のものを使用するならその都度選んで使ってください。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/12857
またモデルによってはVAEが埋め込まれているものもあるので、使用の有無であまり違いがでない場合もあります。
LoRAの入れ方
LoRAはLow-Rank Adaptationの略で、モデルに対して別途学習したポーズ・服装・テイスト・キャラクターなどを反映できる技術です。
これによりプロンプトだけだと再現が難しい画像を生成できます。
LoRAもCivitaiだと探すのが簡単です。
Modelsページからフィルターで絞り込めます。

例えばこちらのLoRAはピクセルアートが作れるものです。
LoRAデータをダウンロードしたら以下のパスに置きます。
stable-diffusion-webui\models\Lora・パッケージ版
sd.webui\webui\models\LoraUIでLoRAを使う場合は、LoRAタブからLoRAデータを選択して、LoRA用のpromptを入力してください。

またLoRAには基本トリガーワードというものが設定されています。
一緒に使用するとLoRAを呼び出せるというものです。
Civitaiではデータの詳細欄から確認できます。

LoRAとトリガーワードを入力して画像を生成すれば、LoRAを反映した画像が生成できます。
<lora:pixel_f2:1>, pixel
なお、LoRAによっては影響が強く、モデルのテイストが崩れてしまうこともあります。
その場合はLoRAの値(重み)を下げるなどして、調整してみてください。
<lora:pixel_f2:1>
↓
<lora:pixel_f2:0.7>Textual Inversion(embeddings)の入れ方
Textual Inversionも使い方はLoRAと同じです。
Textual Inversionの種類にもよりますが、低クオリティや人体の破綻を抑えるものが多く存在します。
またUI上だとTextual Inversionとなっていますが、データを入れるフォルダがembeddingsなので、embeddingやembeddingsと呼ばれることが多いです。
こちらもCivitaiのmodelsページで探せます。

データは以下のパスに置いてください。
stable-diffusion-webui\embeddings・パッケージ版
sd.webui\webui\embeddingsおそらくSD1.5で一番有名なのはEasyNegativeです。
https://civitai.com/models/7808/easynegative?modelVersionId=9208
これをネガティブプロンプトに入れるだけで、低品質や破綻した画像を抑え、自分で書く手間も省けます。
LoRAと同じでTextual Inversionタブからデータをクリックして、使用するためのプロンプトを入力します。
EasyNegativeはnegative用なのでネガティブプロンプトに入力で問題ありません。

品質系のプロンプトやhiresfixは使用せず、同じシード値・プロンプトでEasyNegativeの有無のみ比較したものです。
右:EasyNegativeあり
左:EasyNegativeなし

EasyNegativeの方はしっかり低品質の画像が抑えられていると思います。
ただembeddingsを入れると、一部の要素が生成しにくくなるということも多いです。
使用データにもよりますが、うまく生成できない場合はembeddingsを外してみるなど試行錯誤してみてください。
拡張機能の入れ方
拡張機能は名前の通りA1111を拡張できるものです。
表記を日本語にしたり、ランダム生成したりなど、いろいろ便利なツールを入れることができます。
・インストールする方法①
A1111で拡張機能のリストを表示し、そこからインストールが可能です。
Extensions→Available→Load from:ボタンでリストを表示できます。

下にあるHide extensions with tagsは非表示にする拡張機能の種類、Orderでは並び替えが可能です。
リストの中からインストールしたい拡張機能があったら、右側のinstallボタンを押します。
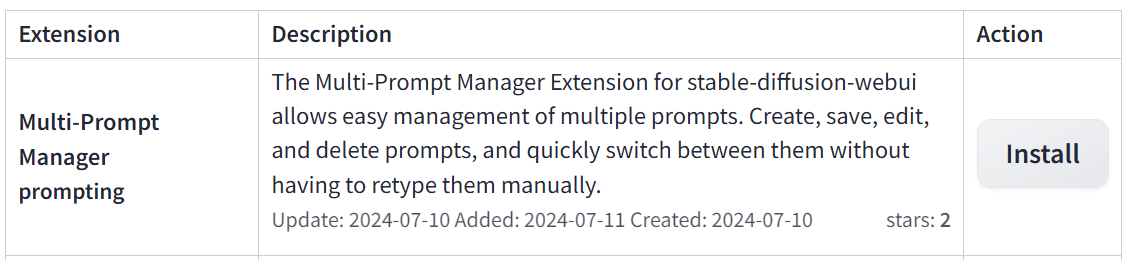
インストールが終わるとリスト上部に「~Use Installed tab to restart.」と表示されるので、Installedタブを開いて、Apply and restart UIをクリックします。

これでインストールは完了ですが、拡張機能によってはリスタートだと反映されないものがあるので、その場合はターミナルを消して再起動してみてください。
・インストールする方法②
GithubのURLから直接インストールが可能です。
一応リストは定期的に更新されるので、有名なものや新しいものは大体載っていると思いますが、たまに載っていない拡張機能もあります。
またリストから探すのが大変という方もいるので、そういった場合はURLから直接の方が便利です。
まずインストールしたい拡張機能を公開しているGithubのページを開き、URLをコピーします。

A1111のExtensions→Install from URL→URL for~にコピーしたURLを入力してInstallボタンをクリックしてください。

終わると「~Use Installed tab to restart.」と表示されるので、Installdタブに行きApply and restart UIでリスタート、または再起動します。
これでインストールは完了です。
A1111のアップデート、バージョンを切り替える方法
パッケージ版でインストールした方は、update.batを起動すれば自動でアップデートできます。
手動インストールした方は、A1111のフォルダでターミナルを開いてください。
アドレスバーにcmdと入力してEnter、または空白部分で右クリック→ターミナルを開くで開けます。
あとは以下のコマンドを実行するだけです。
git pullただアップデートによっては何らかの不具合が出てしまう可能性もあります。
その場合は、特定のVerに戻す必要があります。
パッケージ版でインストールした方は以下のパスでターミナルを開いてください。
sd.webui\webui特定のVerに戻す場合は、以下のコマンドを使用します。
git checkout <commit-hash><commit-hash>の部分はリリースページなどで確認できるコミットハッシュです。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases
例えば24年7月時点で1.9.4ですが、1.9.3にしたい場合は赤枠の英数字をコピーして、<commit-hash>と置き換えればOK。

これを実行してから起動すると、verが変わっているのが確認できます。

最新Verに戻したい場合は、以下のコードで戻せます。
git checkout master
git pull便利な機能や設定
起動オプションの設定
起動時にコマンドライン引数というオプションをつけると、UIの色を変えたり、使用してるGPUの性能に合わせたりすることができます。
コマンドライン引数はフォルダ内にあるwebui-user.batで設定可能です。
こちらを右クリックしてメモ帳などで開いてください。
set COMMANDLINE_ARGS=のところにコマンドライン引数を記入して保存すると、起動時にそれが反映されます。

例えばUIの色を黒にしたい場合は、「--theme dark」、VRAMの消費量を抑えたい場合は「--medvram」などがあります。
半角スペースで区切れば複数指定することも可能。

公式サイトに一覧が記載されているので、詳細はこちらをご確認ください。
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings#all-command-line-arguments
Clip Skipの表示
Clip SkipはCLIP(Contrastive Language-Image Pre-Training)モデルのレイヤーをスキップできる設定です。
SD1.5やSDXL、使用モデルによって推奨値が異なるため、表示しておいた方が切り替えるときに便利です。
VAEと同じ手順で、Setting→左メニューの検索窓に「Quicksettings」→Quicksettings listにclipと入力してCLIP_stop_at_last_layersを選択します。
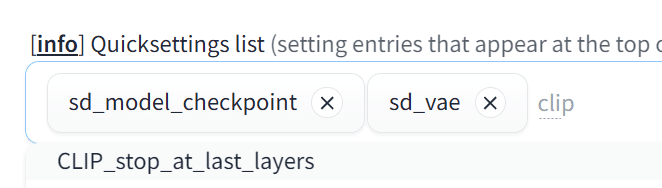
上部のApply Settingsで保存し、Reload UIで再起動すれば、UI上で調整できるようになります。

Style機能
style機能は名前をつけてプロンプトを保存できる機能です。
保存したプロンプトはプルダウンメニューに表示され、選択した状態で生成するとそのプロンプトが反映されます。
また入力欄に呼び出して再編集することも可能です。
まずgenerateボタン下のペンアイコンをクリックしてstyle編集画面を開きます。
保存したいプロンプトを直接記入、または現在使用しているプロンプトを取り込んでください。
取り込む場合は、編集画面右側のアイコンをクリックすれば取り込めます。

入力したら名前をつけて、下のSaveボタンで保存します。
UIに戻るとリストに保存したstyle名が表示されるので、それを選択した状態で生成すれば結果に反映されます。

もし登録したプロンプトを入力欄に呼び出して再編集したい場合は、styleを選択した状態で、一番右側にあるバインダーのアイコンをクリックしてください。
そうすると保存したプロンプトが入力欄に反映されます。
保存したstyleを削除したい場合は、編集画面から呼び出して、Deleteで削除できます。
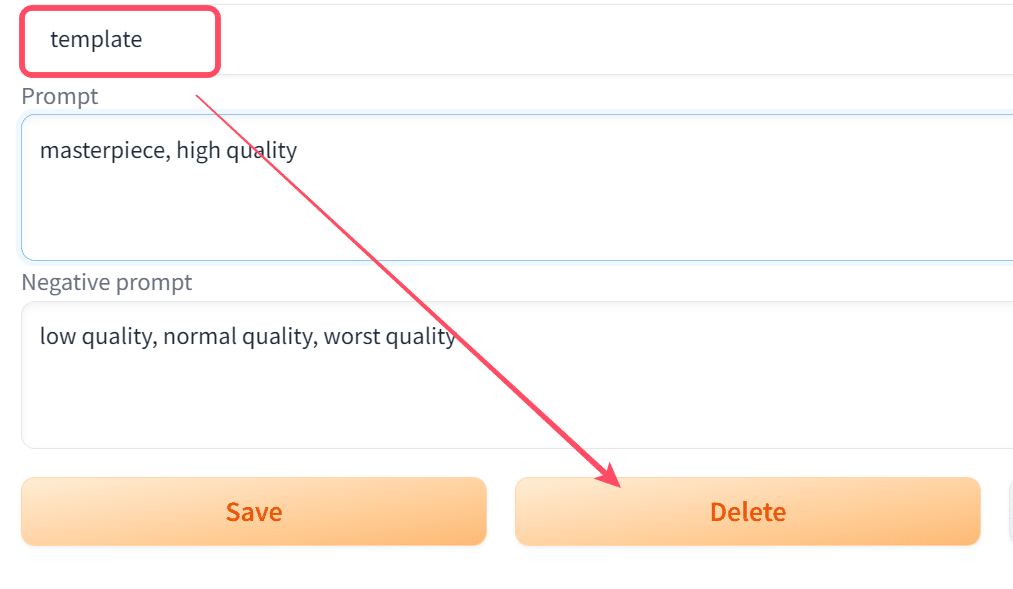
・おすすめの使い方
一般的にうまくいった組み合わせやシチュエーションなどを保存する方が多いと思いますが、SD1.5やSDXL、2D・3Dモデルなどに合わせてパラメータなどを登録しておき、切り替えることも可能です。
以下は2次元モデル用の設定例です。
プロンプト:品質系
ネガティブ:低品質除外・人体の破損を抑えるもの
パラメータ:定番な感じ
画像サイズ:アスペクト比9:16でhiresをon(720×1280)
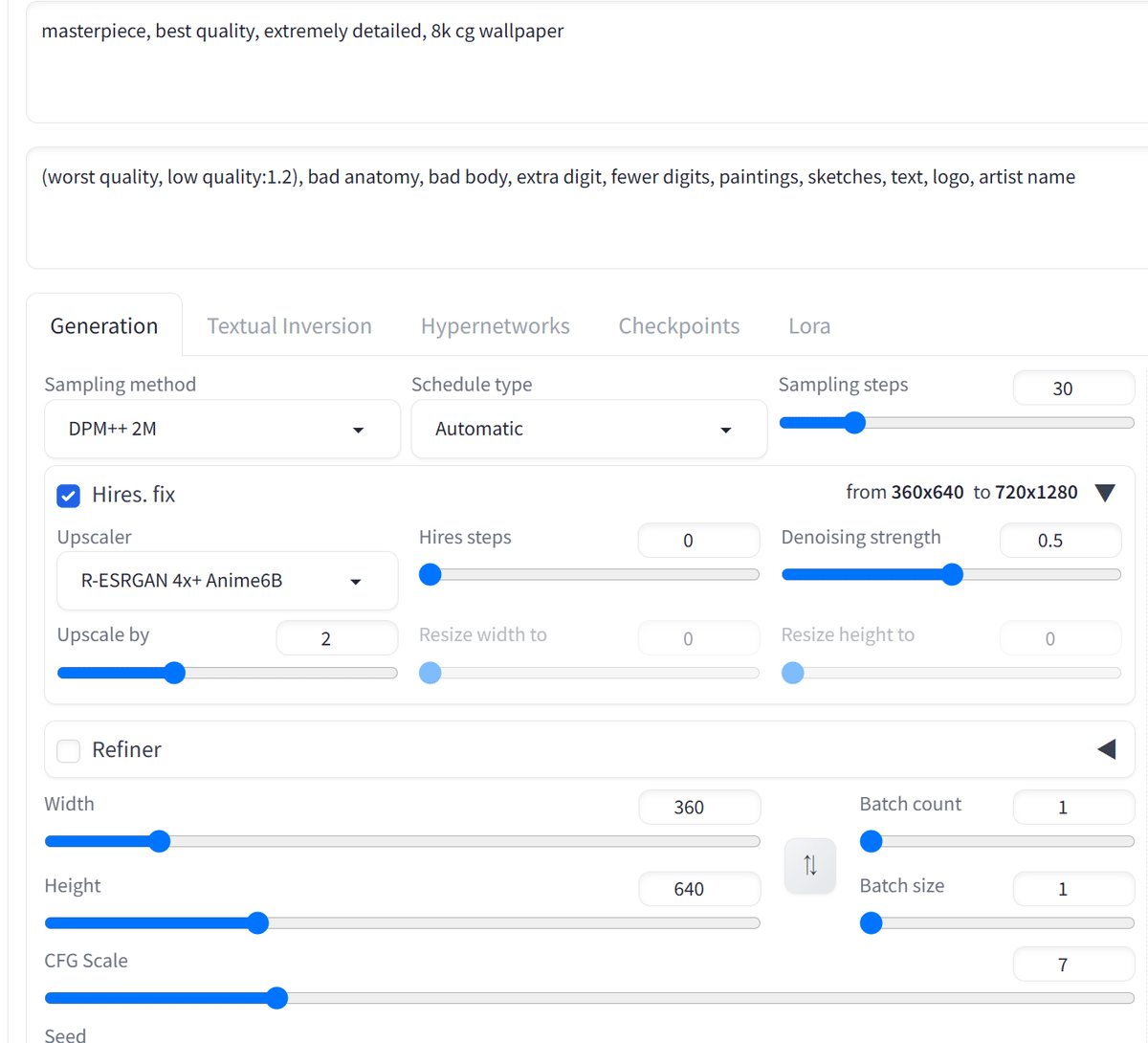
masterpiece, best quality, extremely detailed, 8k cg wallpaper
Negative prompt: (worst quality, low quality:1.2), bad anatomy, bad body, extra digit, fewer digits, paintings, sketches, text, logo, artist name
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Size: 360x640, Denoising strength: 0.5, Clip skip: 2, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6Bこれを全てプロンプト欄に記入して、名前をつけて保存します。
注意点としてプロンプト、ネガティブ、パラメータは改行で分けてください。

UIに戻り、プルダウンメニューから登録したプロンプトを呼び出します。

選択した状態でバインダーのアイコンをクリックします。

この状態で矢印のアイコンをクリックすると、プロンプト、ネガティブ、パラメータがそれぞれに分かれて反映されます。

使用するSDのバージョンやモデルによって、その都度手動でパラメータを変えるのは大変なので、予め登録しておくと便利です。
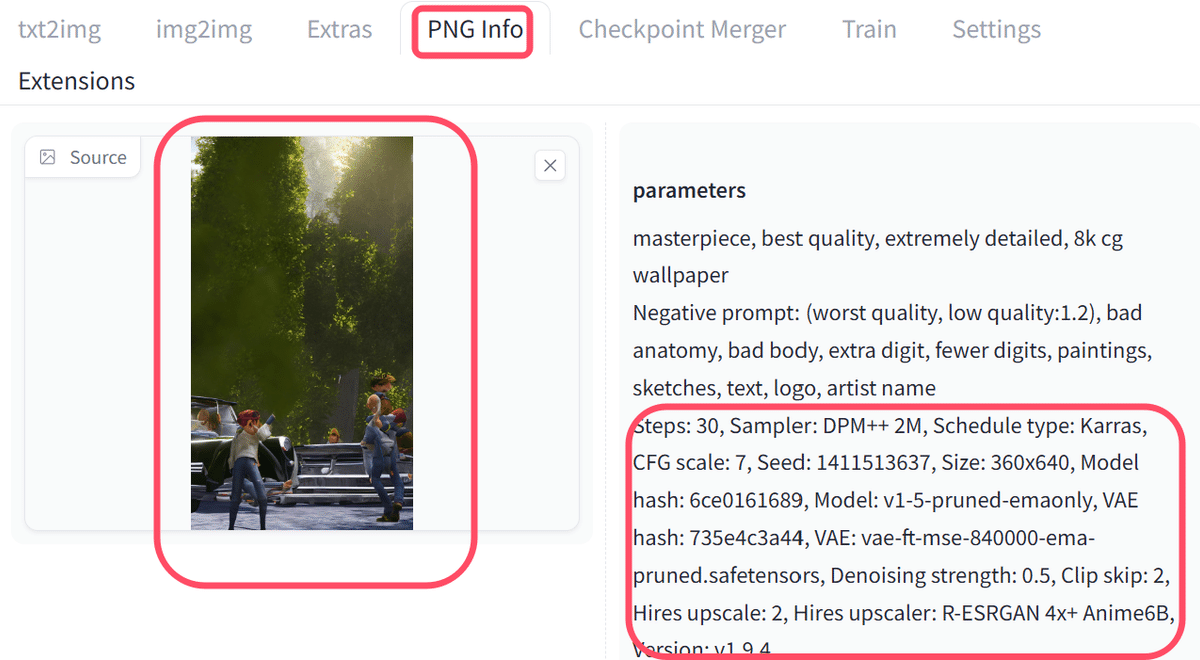
また一度生成した画像のパラメータを再現したい場合は、生成結果やPNG infoからコピペすると簡単です。
生成にしようしたパラーメータや設定がそのまま使えるので、コピペして保存しておけば呼び出すことができます。

prompt matrix
prompt matrixはプロンプトを「|(パイプライン)」で区切り、それぞれの組み合わせをマトリックス図で生成できるものです。
まずUIの下にあるscriptのプルダウンメニューからprompt matrixを選びます。

次に生成したいプロンプトを入力します。
例えばプロンプトに「flower|red|rain」のように入力すると、以下4通りの画像生成が可能です。
flower
flower, red
flower, rain
flower, red, rain

・オプション
・Put variable parts at start of prompt
チェックを入れると最初のプロンプトが末尾に来ます。
上記の例だと2番目はflower, redという順で書かれていますが、チェックを入れるとred, flowerになるということです。
順番によって結果が変わることがあるので、そういった検証をしたい方向けのものになります。
・Use different seed for each picture
チェックを入れると全ての画像を異なるシード値で生成します。
通常は全て同じシード値で生成されます。
・Select prompt(positive・negative)
どちらに入力されたプロンプトで生成するか
・Select joining char
パイプラインをカンマ・スペースどちらで区切るかです。
カンマだとred, flowerは「赤」と「花」です。
スペースだとred flowerで「赤い花」となります。
若干意味合いが異なるので、結果も変わります。
Prompts from file or textbox
こちらもscirptにある機能です。
Prompts from file or textboxは行ごとにプロンプトを実行できます。
直接入力、またはテキストファイルから取り込むことが可能です。
Prompts from file or textboxの入力欄に、生成したいものを行ごとに入力します。
1girl, bed room
1girl, night city
1girl, forest

そうすると上から順にプロンプトが実行され、それぞれの画像が生成可能です。

テキストファイルから取り込む場合は、生成したいプロンプトを行ごとに書いて保存します。

そのテキストファイルをUIにD&D、またはアップロードすれば取り込むことが可能です。

なお、上の書き方だと1girlが全行に入っています。
このように変動しないプロンプトは通常の入力欄に書いて、変動するものと分けた方がスッキリして無駄も少ないです。
例)
変動しない品質・人物はプロンプト
変動させる背景をPrompts from file or textboxへ
・プロンプト入力欄
masterpiece, high quality, 1girl, school uniform
・Prompts from file or textbox
class room
forest
mountain
park
またBatch countを増やすと、それぞれの行を指定した枚数生成できます。
予め生成するシーンやポーズなどが決まっており、それを量産したい場合は、Prompts from file or textboxを使うと作業が楽です。
なお、dynamic-promptsという拡張機能でもCombinatorial generationを使えば同じようなことができ、ランダム入力も可能です。
合わせて使えばより多様な画像が連続で生成できるので、よかったら使ってみてください。
https://github.com/adieyal/sd-dynamic-prompts
・使い方
・オプション
Iterate seed every line - 行ごとに異なるシード値
Use same random seed for all lines - 全行同じシード値
Insert prompts at the(start or end) - Prompts from file or textboxのプロンプトを先頭・末尾どちらに入れるか
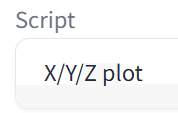
X/Y/Z plot
X/Y/Z plotはさまざまなパラメータをマトリックス図で比較できる機能です。
上の「各パラーメータの意味」の見出しで紹介したような画像が作れます。
まずはscriptからX/Y/Z plotを選択します。
次に比較したい要素を選びます。
例えばstep数による違いを検証したい場合は、X typeでStepsを選び、X valuesに比較したい値をカンマ区切りで入力します。
10~50までの値をそれぞれ比較したい場合は「10,20,30,40,50」と書きます。

あとは生成したいプロンプト書いて実行すれば、ステップごとの画像を比較できます。

またY軸で別の要素を指定することも可能です。
XはそのままでY typeにclip skip、Y valuesに値を入力します。

そうするとX・Y軸それぞれの値でどのような画像が生成できるか、マトリックス図で比較できます。

Z軸はXYを包括するような形で比較ができます。
Z軸に異なるCheckpointを指定すると、それぞれ指定したモデルでXYのマトリックス図を生成してくれます。

X/Y/Z plotは拡張機能のパラメータなどにも対応しているので、値の変化やモデルによる違いを確認するときに便利です。
また値の入力方法もさまざまで、範囲内で指定した枚数を生成、範囲内で値を増減させて生成などの指定もできます。
・Simple ranges:
1-5 = 1, 2, 3, 4, 5
・Ranges with increment in bracket:
1-5 (+2) = 1, 3, 5
10-5 (-3) = 10, 7
1-3 (+0.5) = 1, 1.5, 2, 2.5, 3
・Ranges with the count in square brackets:
1-10 [5] = 1, 3, 5, 7, 10
0.0-1.0 [6] = 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
理想の画像を探したり、検証したりしたい方はぜひ使ってみてください。
以上A1111のtxt2imgについて、基本的な使い方をご紹介しました。
当サークルではこのようなAIに関するさまざまな情報を発信しています。
メンバーシップに加入して頂くと一部の有料記事は読み放題です。
AI技術の向上、マネタイズ方法などに興味がある方は、ぜひご検討ください。
いいなと思ったら応援しよう!
