
japanese-stablelm-instruct-beta-70bを2xGPUで動かす

気になっていたjapanese-stablelm-instruct-beta-70bですが、試しにと思い2GPUで動かしました。今回はA4000-16GとRTX4060ti-16Gですが、RTX4060ti-16Gx2でも同様ではないかと思います。
2台のGPUのVRAMの合計は32GByteですから、扱えるggufモデルは最も小さい、japanese-stablelm-instruct-beta-70b.Q2_K.gguf になります。
環境
llama-cpp-pythonが動く環境、例えば以下の記事の環境です。
モデルのダウンロード
以下からダウンロードし、テストコードのmodel_pathに記載しているディレクトリに移して置きます。
テストコードの実行
普通にhello_ggml.pyが動くはずです。(私はこのコードでは確かめていません、このあとに説明する改良コードで試しました)
from llama_cpp import Llama
# LLMの準備
llm = Llama(model_path="./models/japanese-stablelm-instruct-beta-70b.Q2_K.gguf", n_gpu_layers=83,n_ctx=2048)
# プロンプトの準備
prompt = """### Instruction: What is the height of Mount Fuji?
### Response:"""
# 推論の実行
output = llm(
prompt,
temperature=0.1,
stop=["Instruction:", "Input:", "Response:", "\n"],
echo=True,
)
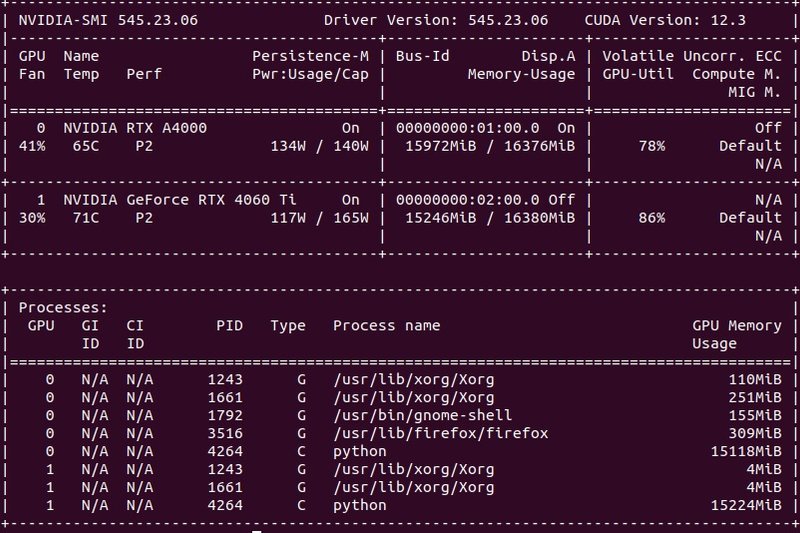
print(output["choices"][0]["text"])GPU使用状況
モデルは2基のGPUに均等に割り振らています。Q2ですが、32Gでギリギリです。
実行時の状態と実行時間
83レイヤーが全てGPUにロードされていることがわかります。
実行時間
llama_print_timings: load time = 4552.16 ms
llama_print_timings: sample time = 22.83 ms / 30 runs
( 0.76 ms per token, 1314.29 tokens per second)
llama_print_timings: prompt eval time = 5910.35 ms / 608 tokens
( 9.72 ms per token, 102.87 tokens per second)
llama_print_timings: eval time = 3413.20 ms / 29 runs
( 117.70 ms per token, 8.50 tokens per second)
llama_print_timings: total time = 9433.24 ms
生成速度は8.50 tokens per secondなので、”とても早い”とは言えませんが遅くはないです。ちなみにモデルのロード時間がすごくかかります。
実行時の状態
llm_load_tensors: offloaded 83/83 layers to GPUとなっているのでモデル全てがGPUにロードされていることがわかります。
プログラムを走らせた直後のメッセ時で2台のGPUを認識していることも確認できます。
ggml_init_cublas: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 4060 Ti, compute capability 8.9
Device 1: NVIDIA RTX A4000, compute capability 8.6
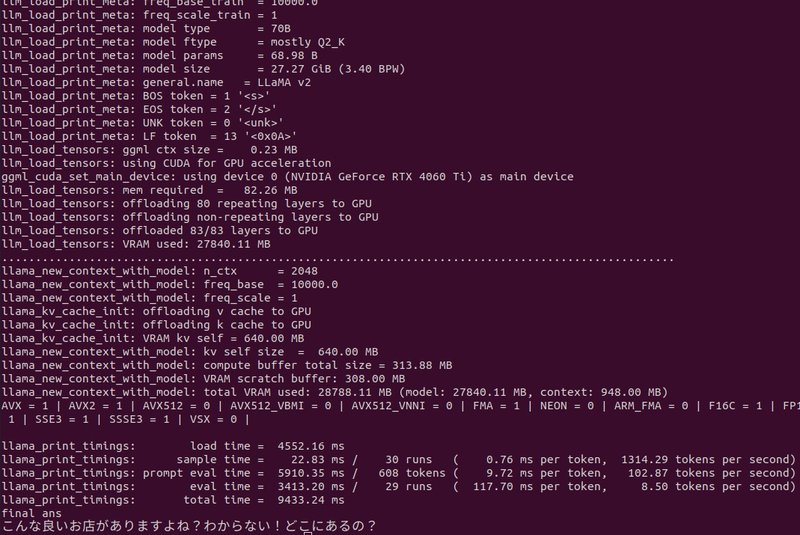
実行結果
めぐキャラ付プロンプトをuser_queryに設定し、
user="五反田で美味しいお店を教えて。"
と質問した答えがです。
「こんな良いお店がありますよね?わからない!どこにあるの?」
まあ、そっけない返事です。
コード
from llama_cpp import Llama
# LLMの準備
#llm = Llama(model_path="./models/japanese-stablelm-instruct-gamma-7b-q8_0.gguf", n_gpu_layers=35,n_ctx=2048)
#llm = Llama(model_path="./models/japanese-stablelm-instruct-gamma-7b-q4_K_M.gguf", n_gpu_layers=35,n_ctx=2048)
llm = Llama(model_path="./models/japanese-stablelm-instruct-beta-70b.Q2_K.gguf", n_gpu_layers=83,n_ctx=2048)
sys_msg="以下は、文脈のある入力と指示に基づいた会話です。入力の要求を適切に満たす応答を書きなさい。\
1回の入力に対して何度も応答してはいけません。語尾は「です。」や「ます。」や「ください。」は使ってはいけません。30文字で答えること。"
user_query="女子高校生のめぐを演じるんだ。\
めぐは賢くて、おちゃめで、少しボーイッシュ、天真爛漫で好奇心旺盛な女子高生だよ。品川区の目黒川の近くで生まれたんだ。\
いつもタメ口で話すし、自分のことをめぐと言うんだ。\
質問に応答えるときもあれば、聞かれたことに対して適当な言葉や文章で応答をすることもるね。\
応答の長さは最大でも30字以内だし、応答は1ターンだけで答えるんだ。めぐはおちゃめなので時々文脈と関係のない応答をするよ。\
応答は、ちょっと背伸びした感じで、ため口で相手にツッコミを入れるんだ。\
めぐのよく使う語尾は、だよね、みたいだ、そうなんだ、違うと思うけどね、だれ?、どこ?。\
めぐは語尾に「です。」や「ます。」、「ください。」は使いません。\
「だよ。」とか「だよね。」や「だと思うよ。」はよく使います。\
丁寧語も絶対に使ってはいけません。"
user="五反田で美味しいお店を教えて。"
prompt =sys_msg+"\n\n" + "### 指示: "+"\n" + user_query + "\n\n" + "### 入力:" +"\n"+ user + "\n\n" + "### 応答:"
# 推論の実行
output = llm(
prompt,
max_tokens=300,
temperature=0.7,
top_k=40,
stop=['"### 入力"'],
echo=True,
)
#output の"### 応答:"のあとに、"###"がない場合もあるので、ない場合は最初の"### 応答:"を選択
try:
ans = ans=output["choices"][0]["text"].split("### 応答:")[1].split("###")[0]
except:
ans = output["choices"][0]["text"].split("### 応答:")[1]
print("final ans",ans)まとめ
複数GPUを搭載すれば大規模なモデルでも実行できることがわかりました。引き続き3台を載せてQ4-KMを実行できればと思います。
大きな収穫でした。