
日本語生成AIのベンチマーク

はじめに
領域特化すれば生成AIの精度を上げることが可能と思われます。昨年の春には領域特化生成AIについて聞かれて OpenAIのSam Altmanはまだその時期ではないと言っていました。日本語特化の大規模言語モデルは領域特化生成AIのひとつです。多くの日本企業が日本語特化大規模言語モデルにとりくんでいます。今回は日本語大規模言語モデルの精度を計るベンチマークについてお話しします。
日本語生成AI
生成AIが話題になるとともに日本企業の日本語特化生成AIの取り組みも活発化しています。
同じベンチマークで計ってくれればいいのですが、そうはいかないようです。
主なベンチマーク
ベンチマークとは
ベンチマークとはもともと測量の用語で、建築物の高低差や位置の基準点や水準点を表す言葉です。IT業界ではもっぱらハードウェアの速度をソフトウェアで計るときに、そのソフトウェアや計った結果の指標として使います。Geekbench, PCMarkなどはスマートフォンの性能を計る指標です。
各社報道発表の状況
調べてみると各社それぞれに別のベンチマークを使っているようです。
NTT tuzumi: RAKUDA
NEC: JGLUE
カラクリ: Japanese MT-bench
リコー: LLM-jp-eval
ELYZA: ELYZA Task 100
ELYZAは自社提供のベンチマークってどうよ、とは思います。しかし、意外に多様なタスクに基づいて、日本語のみならずタスク処理能力を計るベンチマークはないようです。これはこれで合理的なアプローチのようです。
日本語生成AIベンチマーク
今のところ以下のようなベンチマークが利用可能なようです。
JGLUE: 早稲田大学とYahoo! Japanが作ったベンチマーク
Rakuda: YuzuAIという有志グループが考案・運用しているベンチマーク(評価はGPT-4が行う)
Japanese MT-Bench: MT-Benchは英語のみなのでStability AIが提供している日本語版
LLM-jp-eval 国立情報学研究所のLLM-jp勉強会が提供するベンチマーク
ELYZA-task-100 東大松尾研発ベンチャーELYZAが提供するベンチマーク
ベンチマーク結果の具体例
Nejumi LLMリーダーボード Neo (2024年3月16日)[一部抜粋]はこんな感じです。
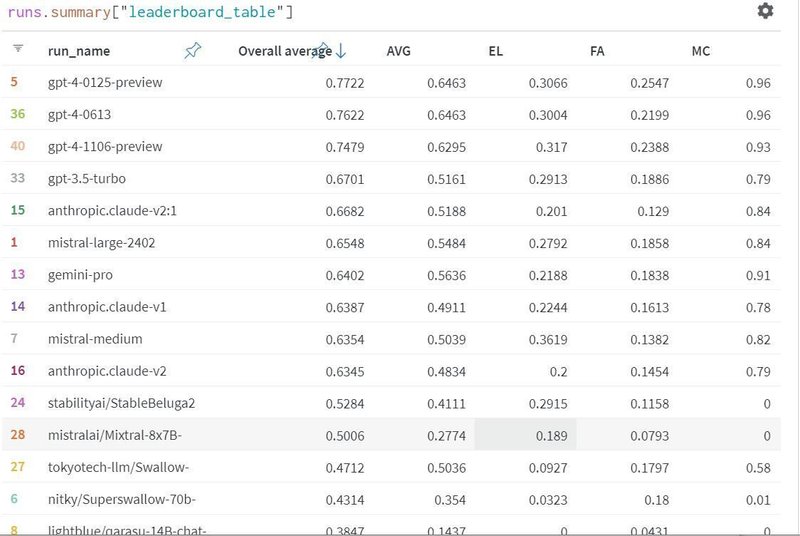
GPT4はOpenAI、ClaudeはAnthropicが開発しました。 MistralはMistral社が開発したOSSです。StableBeluga2とSwallowはLlama2ベースです。qarasuはAlibaba Cloud社が開発したQwenがベースです。
以前のNejumi LLM リーダボードはこちら(メンテ終了しています)。
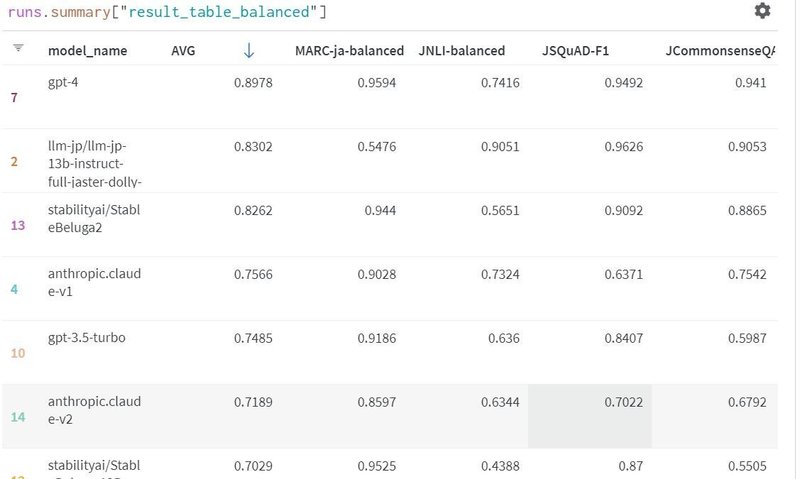
llm-jpはLLM-jp勉強会が開発したものです。
Newに移行した経緯は「LLMリーダーボード運営から学んだ2023年の振り返り」に書いてあります。「LLM-jpモデルがファインチューニングにおいて、明示的にJGLUE(の学習用)データを使って学習しており、テスト用のデータは見ていないので厳密にはリーケージではないものの、前述の形式違反などの問題は極めて低い確率に抑えられている」ということで有利になっていたようです。
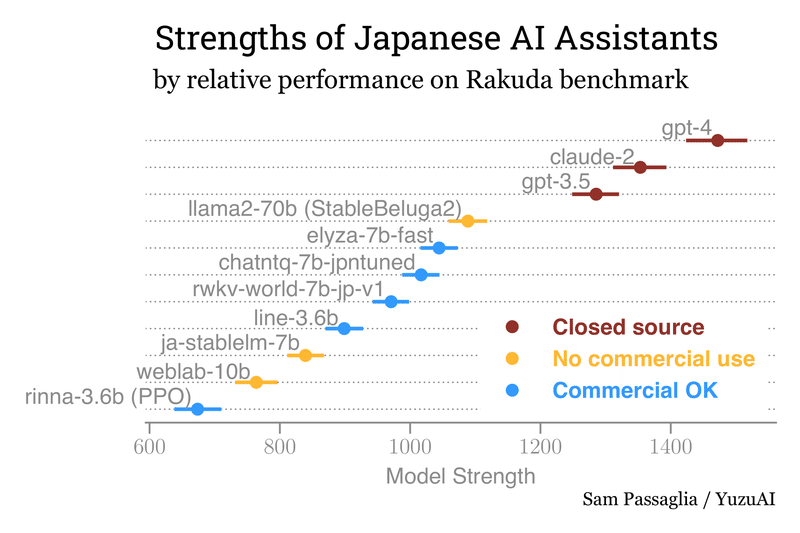
とあるJapanese MT-benchの結果はこちら(「MT-Benchによる各種LLMの日本語運用能力評価まとめ(23/10/31更新)」)

rinnaはEleutherAI/gpt-neoxベースなのでもとをたどればNvidiaのMegatronベースです。Xwinはアラインメント学習でLlama2を改善した中国系のOSSです。
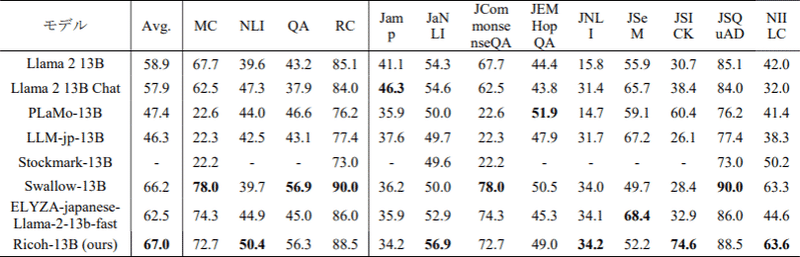
LLM-jpリーダーボード[一部抜粋]はこちら
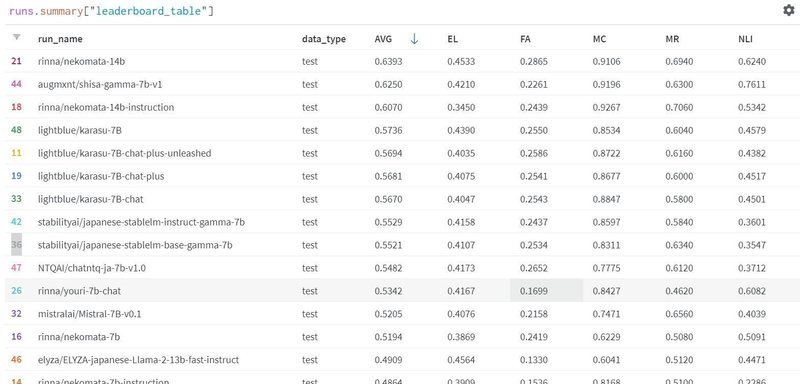
この平均はいろいろなスコアの単純平均なので学術的な意味はそれほどありません。あくまで参考値です。nekomataはQwen(前述)ベースです。shisaはMistralベースのOSSです。karasuはshisaを改良したものです。japanese-stablelmはLlama2ベースのOSSです。chatntqはjapanese-stablelmをベースにしています。このあと、最近、dollyというのが出てきてますが、これはdatabricks社がEleutherAIのPythiaをベースに作成したものです。
こうやってぱらぱらみていると日本語モデルも2分されています:
スクラッチから作るもの
既存の海外モデル(Llama2, Mistral, japanese-stablelm)をチューンしたもの
既存モデルをチューンするのはお手軽アプローチかと思っていました。ベンチマークの内容を調べてみると、推論能力を維持しながら日本語テーストの理解を改善するという上ではむしろビジネス利用する上ではこちらのほうが王道なのかなと思いました。
日本語生成AIベンチマークの課題
JGLUEは有名ですが、調べてみると構成はこんな感じです:
文章分類タスク:MARC-ja / JCoLA (MARC-jaは文のポジティブ/ネガティブを判別)
文ペア分類タスク:JSTS / JNLI (JNLIは文が含意/矛盾/中立を判別
質問応答タスク:JSQuAD / JCommonsenseQA (前者は情報あり、後者は情報なしで常識を使って質問に答える)
MARC-ja / JNLI / JSQuAD / JCommonsenseQAをStability-AIのlm-evaluation-harnessを用いて実行しています。
これは日本語のニュアンスを理解するというタスクを指向しています。一般的なビジネスアプリケーションに必要な推論力とかは計っていません。作っている人が日本語処理の人だから当然といえば当然かもしれません。
GPT-4をしのぐ日本語特化大規模言語モデルとかができても、通常業務にGPT-4の代わりに使うのは熟慮が必要かと思います。
おわりに
数学や論理や常識など異なるベンチマークの加重平均をとる学術的な方法はありません。総合力を計るベンチマーク値はあくまで参考です。数値の分散が大きい指標で相対的に優位なモデルが、平均値で上位になることが予想されるからです。総合的に認知能力を比較する方法はないということを前提に判断しなければならないことがわかりました。
今週、Grokも出たのでますますどのモデルを選択すればいいかの悩みは深くなりそうです。
参考文献
日本語特化大規模言語モデルの難しさ https://note.com/ai300lab/n/n449e682c20c9 2024年
NTT、独自のAIモデル「tsuzumi」 日本語性能はGPT-3.5超えhttps://ascii.jp/elem/000/004/166/4166954/ 2023年
「日本語の性能なら負けない」、NECが参入するコンパクト生成AIの勝ち筋 https://xtech.nikkei.com/atcl/nxt/column/18/02423/072100045/ 2023年
カラクリ、700億パラメーターの国産LLMモデルが最高性能を獲得 https://prtimes.jp/main/html/rd/p/000000070.000025663.html 2024年
日本語精度が高い130億パラメータの大規模言語モデル(LLM)を開発 https://jp.ricoh.com/release/2024/0131_1 2024年
ELYZA、商用利用可能な130億パラメータの日本語LLM「ELYZA-japanese-Llama-2-13b」を公開自社ベンチマークで1750億パラメータのGPT-3の性能を上回る https://it.impress.co.jp/articles/-/25789
日本語LLMのベンチマーク:「JGLUE」と「Rakuda Benchmark」 https://note.com/bakushu/n/n545a97ea43d1 2023年
LLMリーダーボード運営から学んだ2023年の振り返り https://note.com/wandb_jp/n/n6a40364a4fc1 2023年
The Rakuda Ranking of Japanese AI https://yuzuai.jp/benchmark
MT-Benchによる各種LLMの日本語運用能力評価まとめ(23/10/31更新) https://note.com/shi3zblog/n/ne4f3b3cfb6ed
日本語精度が高い130億パラメータの大規模言語モデル(LLM)を開発 https://jp.ricoh.com/release/2024/0131_1
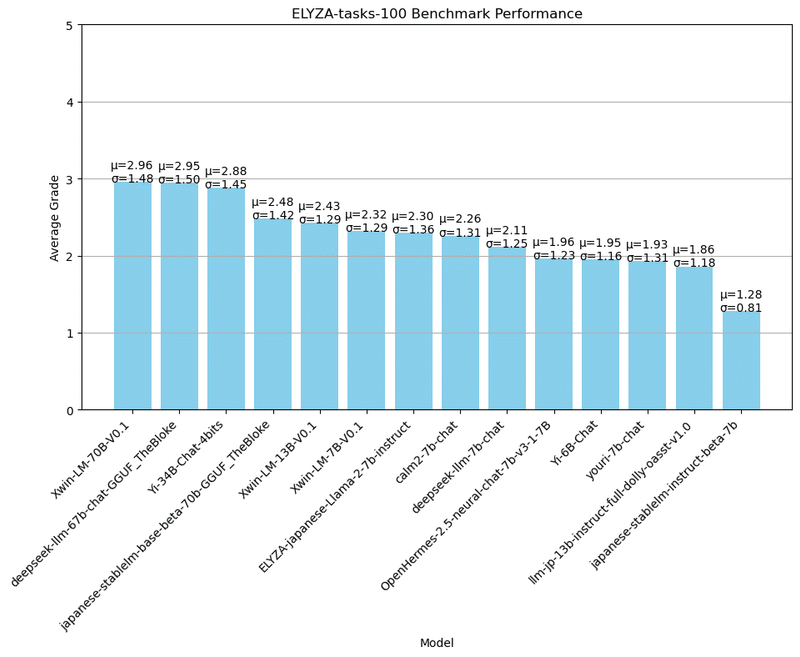
ELYZA-tasks-100 でLLM14個の日本語性能を横断評価してみた https://qiita.com/wayama_ryousuke/items/105a164e5c80c150caf1
この記事が気に入ったらサポートをしてみませんか?