AIでマスクの装着の有無を判定する

どうもこんにちは。
皆様いかがお過ごしでしょうか?
私は眠れぬ毎日を過ごしています。
最近では、スーパーやショッピングモールなど、マスク着用を義務化している商業施設が多くなりましたね。
入店に際して、体温はサーモセンサーやwebカメラを利用してチェックしていますが、マスクの着用に関してはチェックをあまりしていないように見受けられます。
そこで、「入店時にマスクをつけているかどうかを判定するAIがあればいいのでは?」と考え、ITに関しては全くのド素人の私ですが「マスク着用判定AIアプリケーション」を作ってみました。
とはいえ、画像ファイルでの判定なので、webカメラを利用したようなリアルタイムに判定するようなアプリケーションではなく、シンプルな webアプリケーションになりますのでご了承ください。
1・実行環境
実行環境はこちらです。
・python 3.8.5(anacondaをインストール)
・Flask 2.0.0
・Google Colab
・Visual Studio Code
2・ディレクトリ構成図
「マスク着用判定AIアプリケーション」をローカル環境で実行する際のディレクトリ構成図としては以下のようになります
mask_app/
├ static/
│ └ stylesheet.css/
├ templates/
│ └ index.html/
├ uploads/
├ mask.py
└ model.h5
最終的に、このmask_appディレクトリに requirements.txt、runtime.txt、Procfileを加えて、herokuにアップロードすることが目標ですが、まずはローカル環境での動作を目指していきたいと思います。
3・学習モデルを作るための準備をする
始めに、学習モデルを作るための準備をします。
学習モデルとは、ディレクトリ構成図でいうところの「model.h5」に当たるファイルを作る作業で、webアプリケーションにおける「頭脳」の部分になります。
学習モデルを作るためのディレクトリ構成図は以下のようになります。
cleansing/
├ image/
│ └ マスクあり画像ファイル(1.jpg、2.jpg、・・・)
├ image02/
│ └ マスクなし画像ファイル(1.jpg、2.jpg、・・・)
├ results/
├ results_02/
├ cleansing.py
└ cleansing02.py
学習モデルを作るにあたり、私が取った手法は、データの水増しと転移学習です。
その理由としましては、転移学習をしないと学習モデルの判定の精度がなかなか上がらないという過去の学習経験があったからです。
そういうわけで始めていきますが、まず最初に学習モデルを作るための画像データの収集をする必要がありますね。
「マスク着用判定AIアプリケーション」なので、マスクをつけている人物の画像と、マスクをつけていない人物の画像を入手していきます。
作成した cleansing/image フォルダの中に、「マスクあり」画像データを入れていきます。
データ収集にあたり、フリー画像検索サイトのぱくたそさんを利用させて頂きました。
URLはこちらになります。
(ぱくたそ : https://www.pakutaso.com/)
「マスク」と検索すると色々な画像が出てきました。

こちらは「マスクあり」の画像です(見れば分かるって)。
「マスクあり」画像をランダムに選び、cleansing/image フォルダに入れていきます。
私は20枚ほど入れました。
そして、1.jpg、2.jpg、・・・というように、単純に数字だけをファイル名として書き換えていきました。
次に「マスクなし」と検索…ではなく、せっかくなので「美人」と検索しました。

他の検索方法でも「マスクなし」画像は入手できますので、そこは自由に選んで頂いて大丈夫です。
というわけで、これで「マスクなし」画像を入手することができたので、こちらの画像は cleansing/image02 フォルダに20枚ほど選んで入れていきます。
こちらのデータも 1.jpg、2.jpg、・・・というように、単純に数字だけをファイル名にして書き換えていきました。
これでimageフォルダに「マスクあり」画像、さらにimage02フォルダに「マスクなし」画像を入れることができました。
4・画像を水増しする
次は、その集めた画像を水増しします。
水増しのためのプログラムは二つ用意しています。
まずは cleansing.py の方からです。
エディタは Visual Studio Code です。
import tensorflow
from tensorflow import keras
from PIL import Image
from keras.preprocessing.image import ImageDataGenerator
import os必要なライブラリをインポートしています。
インポートが終われば次のコードです。
datagen = ImageDataGenerator(featurewise_center=True,featurewise_std_normalization=True,rescale=1./255,rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
vertical_flip=False,channel_shift_range=180,fill_mode='nearest')keras の Image Data Generator で画像の前処理を行います。
引数の width_shift_range とか height_shift_range などは画像を平行もしくは垂直に移動させて変化をつけるためのものです。=0.2 という数値は画像データの幅に対する割合になります。
少しずつ変化を加えた画像をループで生成していくためのコード、ということになります。
keras の Image Data Generator については詳しく知りたい方はこちらを参照してください。
(ImageDataGeneratorクラス : https://keras.io/ja/preprocessing/image/)
results フォルダに、加工した画像データを入れていきます。
img = keras.preprocessing.image.load_img("image/1.jpg")
x = keras.preprocessing.image.img_to_array(img)
x = x.reshape((1,) + x.shape)
for d,i in zip(datagen.flow(x,batch_size=1),range(200)):
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save('results/{}b6.jpg'.format(i))
img = keras.preprocessing.image.load_img("image/2.jpg")
x = keras.preprocessing.image.img_to_array(img)
x = x.reshape((1,) + x.shape)
for d,i in zip(datagen.flow(x,batch_size=1),range(200)):
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save('results/{}b7.jpg'.format(i))
img = keras.preprocessing.image.load_img("image/3.jpg")
x = keras.preprocessing.image.img_to_array(img)
x = x.reshape((1,) + x.shape)
for d,i in zip(datagen.flow(x,batch_size=1),range(200)):
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save('results/{}b8.jpg'.format(i))
img = keras.preprocessing.image.load_img("image/4.jpg")
x = keras.preprocessing.image.img_to_array(img)
x = x.reshape((1,) + x.shape)
for d,i in zip(datagen.flow(x,batch_size=1),range(200)):
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save('results/{}b9.jpg'.format(i))
img = keras.preprocessing.image.load_img("image/5.jpg")
x = keras.preprocessing.image.img_to_array(img)
x = x.reshape((1,) + x.shape)
for d,i in zip(datagen.flow(x,batch_size=1),range(200)):
img = keras.preprocessing.image.array_to_img(d[0], scale=True)
img.save('results/{}b10.jpg'.format(i))一見すると長いコードに見えますが、よく見るとほとんど同じコードを5回ほど繰り返しているだけですね。
image フォルダに入れておいた、1.jpg、2.jpg、・・・などのファイルをfor文で読み込んでそれぞれ200枚ずつ加工したデータを results フォルダに保存するコードになっています。
上記のコードでは "1.jpg"から数えて"5.jpg" まであるので、このコードで合計1000枚の画像データが水増しできますね。
次に私は、6.jpg、7.jpg、・・・というようにプログラム上のファイル名を書き替えて水増し画像を results フォルダに保存していきました。
今度は cleansing02.py の方になります。
ちなみに cleansing02.py のプログラムの内容はAIdemyさんの講座での学習内容を参考にさせていただいております。ありがとうございます。
まずは必要なライブラリをインポートします。
import os
import numpy as np
import matplotlib.pyplot as plt
import cv2次に scratch_image という関数を定義していきます。
やや長めのコードになりますが、コメントが随所に挿入されている影響で、動作に関する部分はそれほど長くないです。
def scratch_image(img, flip=True, thr=True, filt=True, resize=True, erode=True,bitwise=True,cvt=True,laplacian=True,sobel=True,canny=True):
# 水増しの手法を配列にまとめる
methods = [flip, thr, filt, resize, erode,bitwise,cvt,laplacian,sobel,canny]
# flip は画像の左右反転
# thr は閾値処理
# filt はぼかし
# resizeはモザイク
# erode は縮小をするorしないを指定している
# imgの型はOpenCVのcv2.read()によって読み込まれた画像データの型
# 水増しした画像データを配列にまとめて返す
# 画像のサイズを習得、ぼかしに使うフィルターの作成
img_size = img.shape
filter1 = np.ones((3, 3))
# オリジナルの画像データを配列に格納
images = [img]
# 手法に用いる関数
scratch = np.array([
#反転 : 左右で反転
lambda x: cv2.flip(x,1),
#閾値処理 : 閾値100, しきい値より大きい値はそのまま、小さい値は0にする
lambda x: cv2.threshold(x,100,255,cv2.THRESH_TOZERO)[1],
#ぼかし : 自分自身のまわりの 5×5 個のピクセルを用いる
lambda x: cv2.GaussianBlur(x, (5, 5), 0),
#モザイク : 解像度を 1/5 にする
lambda x: cv2.resize(x,(img_size[1]//5,img_size[0]//5)),
#収縮 : 自身を囲む8ピクセルを用いる
lambda x: cv2.erode(x,filter1),
#画像の色を反転する
lambda x: cv2.bitwise_not(x),
# 画像の輪郭を表示する
lambda x: cv2.Laplacian(x,-1),
# 画像の輪郭を表示する2
lambda x: cv2.Sobel(x,-1,0,1),
# グレースケールで表示する
lambda x: cv2.cvtColor(x,cv2.COLOR_RGB2GRAY),
# 画像の輪郭を表示する3
lambda x: cv2.Canny(x,10.0,200.0)
])
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
doubling_images = lambda f, imag: (imag + [f(i) for i in imag])
for func in scratch[methods]:
images = doubling_images(func,images)
return images
cv2 と lambda 式で水増しデータを生成するコードを定義しています。
cv2 も画像データの前処理でとても役に立つライブラリです。
左右の反転やぼかし、または画像の色の反転の処理など、keras の Image Data Generator では行わなかった処理で画像データを生成しています。
定義ができたら、実行するためのコードを作ります。
# 画像の読み込み
img = cv2.imread("./1.jpg")
# 画像の水増し
scratch_images = scratch_image(img)
for num, im in enumerate(scratch_images):
# まず保存先のディレクトリ"results/"を指定、番号を付けて保存
cv2.imwrite("results/" + str(num) + "aaa.jpg" ,im) cleansing02.py では、一つの画像データから1000枚分の画像データを水増しして results フォルダに保存しています。
私は、4つの画像データから、合計4000枚の画像データを水増ししました。
合計して results フォルダには8000枚の水増しデータができました(水増しの元データを含めると8020枚の画像データを準備したことになりますね)。
ちなみに、保存の際には、ファイル名が被らないように、アルファベットを挿入するなど変化を加えています。
保存する際にファイル名が被ると、どんどん上書きされてしまうためです。
cv2.imwrite("results/" + str(num) + "aaa.jpg" ,im)
↑
この部分ですね。
ここまでの作業は、「マスクあり」画像のみの作業です。
そのため、今度は「マスクなし」画像での作業も行う必要があります。
作業工程は同じなのですが、フォルダ名の変更にだけ注意してください。
cleansing/image → cleansing/image02
cleansing/results → cleansing/results_02
この変更箇所が cleansing.py と cleansing02.py の中に何か所かあるので、一つ一つ変えていきます。
それさえできれば、後は実行するだけです。
5・画像ファイルをGoogle ドライブへ移動する
次の作業ですが、水増しした画像データを入れた results フォルダと results_02 フォルダをGoogleドライブに移動します。
移動はドラッグアンドドロップで出来ますが、合計で約16000枚もの画像データになると、さすがに一瞬でというわけにはいかないので、少し時間がかかりますが宜しくお願い致します。
6・ディープラーニングで学習モデルを作る
そして、いよいよ学習モデルを作っていきます。
学習モデルの作成には Google Colab を使います。
Google Colab を使うのは GPU を利用するためなのでハードウェアアクセラレータを GPU に変えていきましょう。
まずは Google Colab を開きます。
ちなみ、「Google Colab とは?」という方は下記を参照すると参考になると思います。
それでは Google Colab の画面に戻ります。
この画面の上にある「ランタイム」タブをクリックすると、「ランタイムのタイプの変更」という項目が表示されます。
それをクリックすると次の画面になりますので…
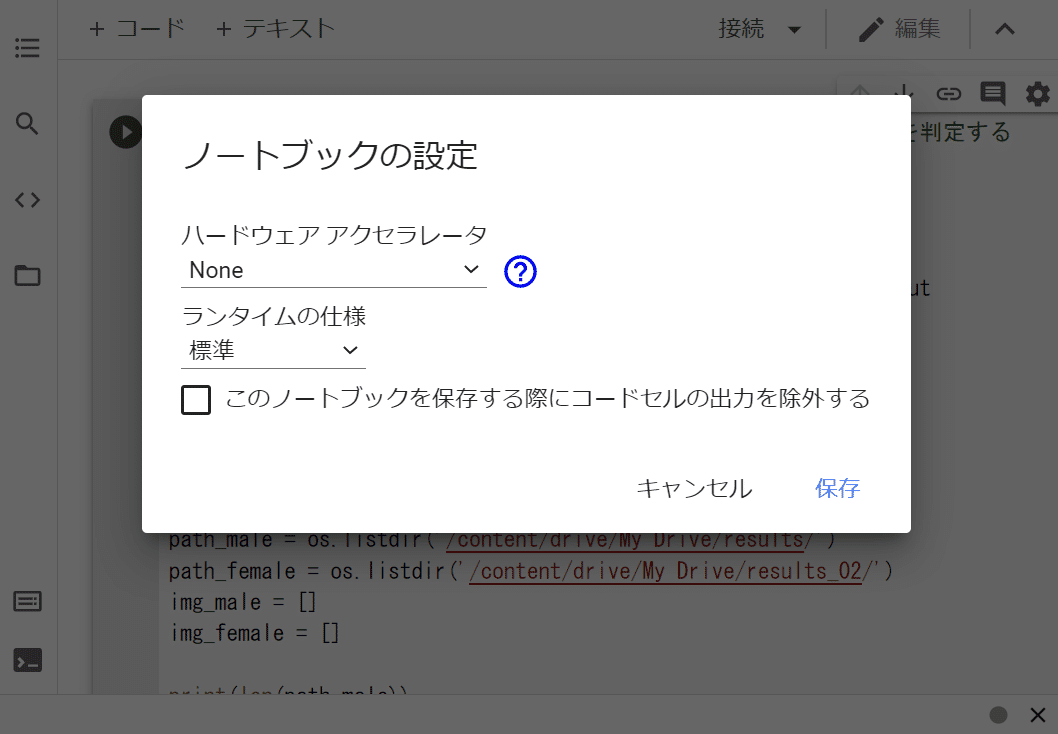
「ハードウェア アクセラレータ」をクリックして…

「GPU」に変更して保存をします。
GPUはディープラーニングの学習において実行速度を速めると言われていますね。
では、コードの方に戻ります。
まずは必要なライブラリをインポートします。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from google.colab import drive転移学習をするので、VGG16をインポートしています。
そして、Google ドライブからの読み込みをするので、このコードを入れます。
drive.mount('/content/drive')これで Google ドライブからの読み込みができます。
mask = os.listdir('/content/drive/My Drive/results/')
no_mask = os.listdir('/content/drive/My Drive/results_02/')mask という変数に results フォルダの「マスクあり」画像の水増しデータを格納します。
no_mask には results_02 フォルダの「マスクなし」画像の水増しデータを格納します。
img_mask = []
img_no_mask = []
for i in range(len(mask)):
img = cv2.imread('/content/drive/My Drive/results/' + mask[i])
img = cv2.resize(img, (50,50))
img_mask.append(img)
for i in range(len(no_mask)):
img = cv2.imread('/content/drive/My Drive/results_02/' + no_mask[i])
img = cv2.resize(img, (50,50))
img_no_mask.append(img)水増しデータをfor文で取り出していき、cv2.resizeで画像データのサイズを変えていきます。それらをappendでリストに格納しています。
このデータの読み込みに、かなりの時間を要しました。
その時間を有効に活用しようと考え、別の作業をし始めたので正確な時間を計ってはいないのですが、2時間はかかったと思います(あまりに長いので、気にすることをやめました)。
さて、続きですが…
X = np.array(img_mask + img_no_mask)
y = np.array([0]*len(img_mask) + [1]*len(img_no_mask))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)水増しした画像データを numpy で数値に変換し、二次元のデータ配列にします。
XとYに格納したら、データを学習用と検証用に分割していきます。
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(2, activation='softmax'))ここで転移学習をするために、vgg16のインスタンスの生成を行います。
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False #lr =1e-4 ,momentum=0.9 >>> # error `momentum` must be between [0, 1].
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=0.0001, momentum=0.9),
metrics=['accuracy'])
model.fit(X_train, y_train, batch_size=256, epochs=100) vgg16のインスタンスと学習モデルとの連結を行っていきます。
余談ですが、momentumの値を変更したところ、0~1の間にしなさい、というエラーメッセージが出ました。
lr(leaning-rate : 学習率)の値を変更してみましたが、あまり大勢に影響がないと思い、0.0001で固定しました。
batch_size は、2のべき乗の数値が良い、ということで、256に設定しました。
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
model.save('model.h5')実行したところ、最終的に…
Test loss: 0.08031904697418213
Test accuracy: 0.9755147695541382
という数値になりました。
これでひとまず AI の「頭脳」である model.h5 ファイルを作ることができました。
7・web アプリケーションを作る
次にwebアプリケーションの開発に進みます。
基本的には講座を受講させて頂いたAIdemyさんの学習内容を踏襲させて頂きました(これまでの内容もかなり踏襲させて頂いてますが…)。
もう一度、ディレクトリ構成図を見てみましょう。
mask_app/
├ static/
│ └ stylesheet.css/
├ templates/
│ └ index.html/
├ uploads/
├ mask.py
└ model.h5
こんな感じですね。
8・HTML をコーディングする
まずは templates フォルダ下の index.html からコーディングします。
これは webアプリケーションの「顔」とも言える部分ですね。
<!DOCTYPE html>
<html lang='ja'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content="device-width, initial-scale=1.0">
<meta http-equiv='X-UA-Compatible' content="ie=edge">
<title>SKY_RISE</title>
<link rel='stylesheet' type='text/css' href="./static/stylesheet.css">
</head>
<body class='top'>
<div class='main'>
<h1>マスクをつけていますか?<br>皆さん敏感になってますよ!<br>AIに判定してもらいましょう!</h1>
<p>画像を送ってくれれば確認します</p>
<form method='POST' enctype="multipart/form-data">
<input class='file_choose' type="file" name="file">
<input class='btn' value="CLICK!" type="submit">
</form>
<div class='answer'>{{answer}}</div>
<div class='up_image'>
<img src='{{filename}}'>
</div>
</div>
</body>
</html>とてもシンプルな構造となっていますが、半年前まで「html?何それ」という状態だった私の、これが今の限界です。
AIdemyさんで学習したことと少し異なっている部分としては、判定された画像を表示したいと思ったので…
<div class='up_image'>
<img src='{{filename}}'>
</div>を付け加えたことです。
html 初心者としては、「どうすれば画像を表示できるのか?」という部分で窮地に立たされました。
チューターさんに質問してみようかとも思いましたが、「まずは自分で調べてみて、それでどうしても分からなかったら質問しよう」というスタンスで学習を進めていくことに決めていたため、自分であーでもないこーでもないと調べて、何とかその答えを見つけることができました。
実は、これだけの作業でかなり時間がかかりました。
ちなみに、この学習方法が良いかどうかは分かりません。
素人なんだから、「分からないことはプロフェッショナルにどんどん質問した方が良い」という考え方も、もちろんあると思います。
私の学習方法は、おそらく効率性に反しています。時間がかかる作業を自らに強いているわけですから。
効率性を重視する現代では、効率が悪い作業を悪とみなす風潮もあります。それに照らし合わせれば、私の方法論は悪です。
これは私の考えですが、自分が納得できる、そして自分に合った学習方法を、それぞれが見つけていくことが最善だと私は思っています。
効率性を重視するか。自分で仮説を立てて調べていくか。もしくはどちらの方法も活用するか。または、別の方法を見つけていくか。環境や状況に合わせて判断していくことが最善ではないかと思っています。
9・CSS をコーディングする
次に static フォルダ下の stylesheet.css です。
これは、html というwebアプリケーションの顔を彩る「メイク」みたいなものですね。
body.top { background-image: repeating-linear-gradient(0deg, transparent,transparent 4px,rgba(255,255,255,.4) 4px,rgba(255,255,255,.4) 6px), url(new_neruneru.jpg);
height: 100vh;
background-size: cover;
background-repeat: no-repeat;
background-position: center center;
background-attachment: fixed;
background-color: lightblue;
vertical-align: -50%; }
h1 { text-align: center;
color: white;
text-shadow: 1px 2px 3px black;
vertical-align: -50%;
font-family: 'Dancing Script', cursive;
font-size: 2.5rem;
margin-bottom: 2rem;
}
p {
text-align: center;
color: white;
text-shadow: 1px 2px 3px black;
vertical-align: -50%;
}
.answer {
color: white;
margin: 70px 0px 30px 0px;
text-align: center;
vertical-align: -50%; }
form {
text-align: center;
vertical-align: -50%;
}
p { font-family: wanpaku-rera, sans-serif;
font-style: normal;
font-weight: 100;
font-size: 2.5rem;
margin-bottom: 2rem; }
img { display: block;
margin-left: auto;
margin-right: auto } css でコーディングしたかったこととしては、文字や画像などを中央に持ってくることと、背景の画像との兼ね合いから文字を白にすること、でした。その方が見栄えが良いと思ったからです。
css に関しても、初心者としては、調べてコーディングして実行して確認して、調べてコーディングして実行して確認して、という作業を繰り返しました。
その作業も、全くもって非効率なため、現代の優れた方々からはお叱りを頂きそうです。
さらに、html や css というものは webデザインと言われている領域なので、当然のことながら美的感覚を問われる作業であり、アートに関して造詣が深くもなく、ましてやデザインのセンスが皆無な私としては、新たなジャンルへの挑戦、ということになりました。
やることが増える、ということは、ある意味では重荷にもなりますが、考え方によっては楽しみだったり刺激だったりにも変わります。
新たな課題や義務を、楽しみや刺激だと思えるように感性を整えていく必要があると思いました。
そして、この背景画面では、再びぱくたそさんから画像を拝借しました。
背景として利用する際に少し加工しましたが、元画像はこれですね。

ぱくたそさん、ありがとうございます。
10・flask を使って実装する
続いては、webアプリケーションを動作させるための「神経回路」であるflaskを使う mask.app の実装に入ります。
まずは必要なライブラリをインポートします。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
from flask import send_from_directoryflask のインポートが二か所に分かれていますが、これは後で思い出して付け加えたためです。なので一行にまとめても問題ありません。
学習モデルを判定するために、numpy をインポートしています。
classes = {0: 'つけている', 1: 'つけていない'}
image_size = 50
app = Flask(__name__)
UPLOAD_FOLDER = 'uploads'
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS画像ファイルを判定するので、その拡張子である png や jpg などを取得するための定義をします。
allowed_file で、「". " の後に png や jpg などの拡張子かどうか検閲しますよ」と定義しているわけですね。
model = load_model('./model.h5')このコードで、作成した学習モデルを読み込み、model という変数に格納します。
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
# 受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, color_mode='rgb', target_size=(
image_size, image_size))
img = image.img_to_array(img)
data = np.array([img])
# 変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "あなたはマスクを" + classes[predicted] + "ようです"
return render_template("index.html", answer=pred_answer, filename=filepath)
return render_template("index.html", answer="")やや長めのコードになりましたが…
要するに、ファイルが画像ファイルかどうかを選別し、そして入力した画像ファイルを学習モデルである model.h5 ファイルに渡して予測をしてもらう、という流れになっています。
入力した画像ファイルを numpy で二次元データに変換します。
二次元データに変換してから学習モデルに渡して予測をしてもらう、というのが、AIの画像判定の仕組みになります。
そして、次のコードで mask.app の締めくくりとなります。
@app.route('/uploads/<filename>')
def send_file(filename):
return send_from_directory(UPLOAD_FOLDER, filename)
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host='0.0.0.0', port=port)判定された画像ファイルを web ブラウザ上に表示するコードです。
このコードを調べ上げるまでに結構な時間を費やしましたが、自分で調べたことで満足感がありました。
何事でもそうだと思いますが、学習の過程で満足感を得られることは大事だと思いました。
ここまでの工程で、ローカル環境での webアプリケーションの実装は完了です。
11・webアプリケーションをwebブラウザに表示する
さっそくコマンドプロンプトで、 mask_app ディレクトリに移動して、pythonでmask.py を実行してみましょう。
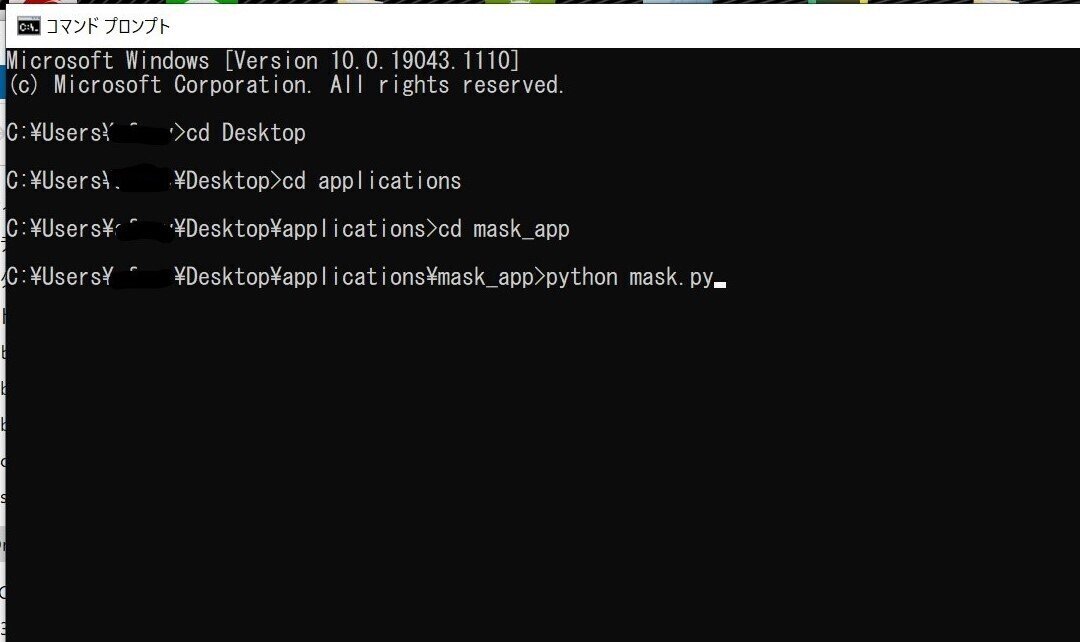
そして、コマンドプロントの下に出る
をコピペします。

この部分ですね。
画面のこのURL上のどこでもいいのでダブルクリックをすると、URL部分だけを選択しますので、それをコピーして、web ブラウザの検索タブに張り付けて検索します。
すると…

無事に表示されましたね。
次に、画像判定をするために、 mask_app/uploads フォルダに画像を入れます。
ぱくたそさんから以下の画像を拝借しました。




「マスクあり」画像を2枚と、「マスクなし」画像を2枚ですね。
では、一枚ずつアップロードしていきましょう。
「ファイルを選択」ボタンから選択していきます。
まずは、「マスクあり」画像から。


マスクをつけている画像の上に「あなたはマスクをつけているようです」の白文字が出ました。
ちゃんと判定できていますね。
白文字が小さいうえに背景色と被ってしまい、見えづらくてすいません。
次は、マスクをしていない方の画像です。


マスクをつけていない画像には「あなたはマスクをつけていないようです」の白文字がでました。
判定もうまくいっていますね。
こちらも白文字が小さいうえに背景色と被ってしまい、見えづらくてすいません。
顔の向きが正面でないとうまく判定されないのでは?という危惧もありましたが、とりあえずはうまくいきました。
herokuにアップロードしたURLがこちらです。
https://aferventus04.herokuapp.com/
12・振り返ってみて思うことと、これから先のこと
素人ながら、なんとか作ることができました。
苦労しましたが、その分、達成感がありますね。
この作業を経て、 html や css のことについて、もっともっと学ばないといけない、という課題も見つかりました。
格好いい web サイトなどを見つけて、作ってみたい webデザインをイメージしていきたいと思います。
同時に、flask についても学んで、html を機能的に動かすことができれば良いと思っています。
当初は、GAN(敵対的生成ネットワーク)を学ぼうと思っていましたが、まずはflaskを学んでアプリケーションの実装についての知識を得てからGANを学んでいこうと考えています。
やりたいことや、やるべきことが、どんどん出てくると、もっともっと成長していけるのではないかと思っています。
いくつになっても、毎日学ぶ姿勢をもって、生きていきたいと思います。
拙い解説にお付き合い頂きまして、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?