
AIを利用したイラスト作成!意外と直感的に使いやすいSegmentation

こんにちは、一般イラストレーターです。StableDiffusion関連の新しい動きがあまり無いようですが、如何お過ごしでしょか?openposeの精度向上したDW openposeが登場したくらいですかね。
さて前回の更新で一年間毎月更新を達成しましたのでもうそろそろ良いかと思ったんですが、なんか複雑で面倒そうで放置してたcontrol netのsegmentationを試してみたところ、意外と直感的に塗れて結構使い易かったのでご紹介します。segmentationは画像に含まれる要素を物体ごとに分割し、色によって塗り分け&生成をする機能です。複雑そうですが、感覚としてはscribble並にざっくり扱えて、なおかつ物体同士の区別はlineart並にハッキリできる感じでした。
あと前回の更新で「いやー、最近AI全然使ってないっすわー」と言いましたが、AI着色物を一旦グレースケール化してグリザイユ技法で彩色する手法が品質的に満足できるレベルと分かり、最近は割と活用しておりますのでそれも後ほどサラッと紹介しようと思います。
↓segmentationの色見本はこちら。
openposeやdepthのベース画像作成がそうであるように、segmentationの色は数式のように厳密に決まっている訳ではありません。私は上記ページの色見本からスポイトで色を取って描いていますが、目見当で色を塗ってしまっても問題ないです。とりあえず最初は「wall」を意味する灰色をバックに、「person」を意味する深紅色で人間っぽいシルエットをクッソ適当に描いて試すのをオススメします。では私もなんか描いてみよう。
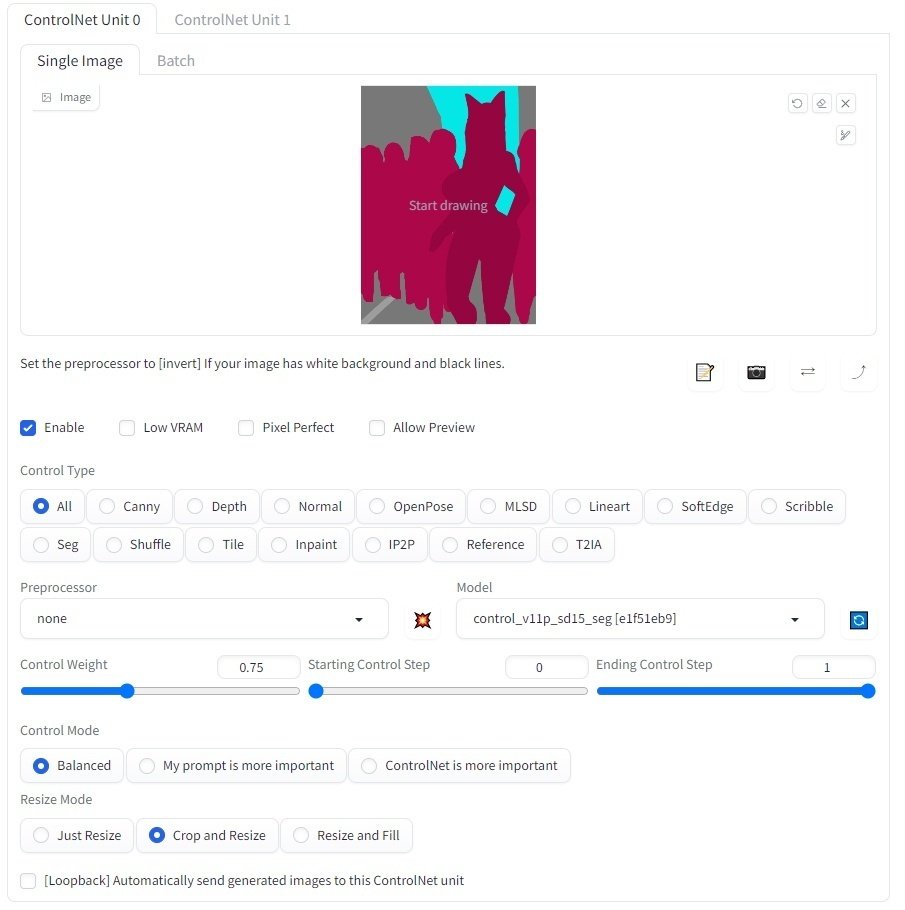
segmentation用のベース画像が描けたらcontrolnetにセットします。専用に描いた画像をセットしているのでPreprocessorはnoneでOKです。Modelにcontrol_v11p_sd15_segなどのsegmentationモデルをセット。描いたベース画像がクッソ適当ですので、ControlWeightは0.75くらいにして、AIにある程度自由に描かせます。シルエットがグネグネしている画像をベースに1で生成させると生成物もグネグネしてしまいますからね。シルエットをしっかり描いた場合は1で構いません。

生成には私の絵柄で学習されたLORAを使用。はい、イメージ通りキャラと群衆が生成されました。ここで『人物』を生成しているのに猫耳娘と奥の群衆とで色が若干違うことに気付いたと思います。先ほど言った通りsegmentationの色は厳密に決まっている訳ではありません。なのでこうして微妙に色を変えてしまうことで、メイン猫耳娘と群衆を差別化できます。これにより猫耳娘が群衆に混ざることなく、イメージした通りのポーズを取らせることができました。
では次はもうちょっと細かくパーツ指定してみましょう。

落描きからイラスト生成するscribbleの場合、背景に四角やら丸やら描いてもなかなか的確にモニターやらライトやらにはなりません。しかしsegmentationならAIが『あ、この色はモニターっスね』『この色は光源っスね』と判断してくれるので、scribbleと同程度の落書き労力で的確な生成ができる訳です。まぁ、下の方に並んでるライトみたいに描写がなんとなく自然でないものは再現性も下がるので、良い感じのが出るまで多少生成ガチャすると思いますが…。
さて、上の二枚は色見本にあった色を使いましたが、見本の色数はたかが150個ですので、世の神羅万象からすると足りない物だらけです。ヘッドフォンも該当する色が無いので『hood』の色で塗りましたが、実際には何色でも問題ありません。segmentationはリストに存在しないものでもそれっぽく塗り分けてさえいれば、大体見た目通りのものとして描写をしてくれるのです。

服を塗って生成してみました。通常、人物が着ている服はその人物の一部として扱われるため、色見本には『服』がありません。しかしご覧の通り塗り分けは正常に認識されています。それとかなり便利なテクニックですが、「同一の連なった物体」も微妙に色を変えることでパーツの境界を表現させることができます。服を想定して塗った紫色も「上半身、胴、スカート」で微妙に色を変えましたが、生成に何となく反映されていますね。

この『微妙に色変え』は、人物のプロポーションをはっきりイメージしている場合や、ダイナミックなポーズを取らせたい時に役に立ちます。このお姉さんも「顔、上半身、足」で微妙に色を変えましたが、イメージした通りの四つん這い&巨乳で生成されました。全部同じ一色で塗ってたらかなりの生成ガチャを強いられたでしょう。
更にsegmentationは雑なラフと詳細な描き込みを両立させることもできます。

細部を追従して欲しいのでControlWeight値を1で生成。顔のパーツをちょっとづつ動かしましたが、生成物の顔の向きも変化しています。詳細な描き込みが生成に反映された訳ですね。これは例えばAI生成画像を編集する場合でも「これの顔の向きをもうちょっとずらしたい」「こういう形のリボンをつけたい」という時に、
生成画像からsegmentation画像を取得
↓
パーツをちょっと描き込む
↓
segmentationで生成
とすれば微妙な顔の向きやパーツを調整できます。ざっくりしたラフと詳細パーツ配置の両立、まさしく剛と柔を兼ね備えておる。こいつぁ痒いとこに手が届くぜ。
あとイラスト製作的に少し面白いのは光源位置をコントロールできることでしょうか。

「lamp」に対応する黄色の位置を動かすことで、生成物の光源の位置を制御できます。と言ってもAIが描写するライティングは必ずしも正しくないですし、影の雰囲気も生成毎にまちまちなので信頼性はあまり高くないのですが。
はい、segmentationは大体こんな感じです。意外と直感的に扱えるので驚きました。雑なイメージからAI画像を起こしたい場合はscribbleより断然segmentationを使いたいですね。
■AI着色→グレースケール化→グリザイユによるイラスト制作
では折角なんでsegmentationでラフを起こしつつ、線画→AI着色→グレースケール化→グリザイユ彩色によるイラスト制作をササッとやっていきたいと思います。

まずはアタリから描きます。いきなりsegmentation描けって言われてもバランス分からなくて上手く描けませんからね。アタリをベースにsegmentationを手塗り。各5分。

描いたsegmentation画像を読ませて生成。解像度が低いのでまぁまぁ狂っとる。何枚か生成して良い感じの部位を参考にしつつ、線画を手描きしていきます。

線画ヨシ。所要時間だいたい2時間30分。結構かかるな…参考があるとは言え…。線画が描けたのでLineartでAI着色してみましょう。Lineartについては以前の記事で何回か登場しているので参照してください。

高解像度で本格的に着色させる前に、全体的なライティングを決めたいので低解像度で何十枚かAI着色ガチャ。クォレハ…、ちょっと色が散かり過ぎてて手に負えないのでは?note描くからって線画ハリキリ過ぎたんだ…!AI着色はキャラ単体の線画ならそれなりにやり易いですが、構図が複雑になってくると生成が手に負えなくなってきます。現状マトモに塗れるラインはこの辺が限界でしょーか。真面目に塗らせるとしたらモブはモブで別線画として分割して塗らせるとかしたいところですね。
ちなみにControl Modeの設定によって見た目に変化が生じるようです。realisticで塗らせる場合、Control Modeが「balance」だとなんかのっぺり明いですね。色味としては「My prompt is more important」も好みですが、どうもcontrol netの遵守性が下がるようです。「ControlNet is more important」が良い感じでしょうか。

良い感じのところをピックアップして雑に合成。ライティングはこんな感じでいきましょう。後の工程でグレースケール化して色を自力で着色しますので、この段階ではなるべくキャラのカラーリングは白や明るい色主体である方が望ましいです。モブのオッサンが黒いズボン穿いてますが、これはグレースケール化した際に陰影が濃くなってしまい、好きな色を乗せ辛いので避けた方が良いです。まま、モブだしえやろ。
次にこの画像を高画質化します。

拡張機能のMultiDiffusionを使い2倍に拡大。ノイズ軽減の為にNoise Inversionをチェックし、Inversion stepsは20。拡大生成できたら、更にそれをRealESRGANで2倍に拡大。解像度は768*512→3072*2048になりました。作業時間測ってたんですが、途中でStableDiffusion自体の不具合に見舞われてしまい、解決の為にネット検索したり環境の全面的な再構築&アップデートを余儀なくされ、もう作業時間とかどうでも良くなってしまったのでした。まぁお陰でなんか生成速度が今までの1.2倍くらいになったんだけど…。こういうのもツールとして安定しないとこや!(言いがかり
StableDiffusionでの作業はこれで完了なので、以降は手描き作業です。過去のnote記事でもAI着色のイラスト利用を試みて来ましたが、実のところ全体的に微細な色ムラがあったり、そもそも統合されてしまっているフルカラーイラストの細部修正自体やたら手間のかかるものだったりで、ある程度適当で構わないブツでしか使えない気がしていました。例えばキャラクターの肌の色を微妙に調節したい場合なども、肌のコントラストを上げようとすると既に塗られている「肌の赤み」まで過剰に赤くなったりで、非常にやり辛い訳です。

なのでこうして一旦グレースケール化して細部修正する…。キャラと背景も分割して作業します。色は後からグリザイユで塗りますが、グレースケールだと細部修正は圧倒的にやり易いですね。

グレースケール画像の修正完了。割と全面的な修正が必要になるので1時間30分。続いてグリザイユ画法で色を乗せていきます。

ご存じの通りみんな大好きグリザイユ画法とは、グレースケールの下地に対して、乗算レイヤーやオーバーレイレイヤーなどを追加して後から色を乗せていく画法です。これによりモノクロ画像に自在に色を…、い、色…、わからん…グリザイユでどう塗るのが正しいのか…なにも…、我々はフィーリングでグリザイユグリザイユ言っている……。AIイラストは生成毎に肌の濃淡が微妙に異なります。これはグレースケール化した際にも灰色の濃度として表れますので、色レイヤーのテンプレを使いまわそうにも、常に毎回微妙な色調調整を強いられる訳です。AI着色のグレスケ化→グリザイユは色ムラが安定するので品質的に満足できるけど、作業として安定しないので困るぜ。

キャラは大体塗れました。着色2時間30分くらい!普通に時間かかってますね。背景はAI生成物を流用してササッとやりましょう。

1時間で背景完了。ソファや窓枠は流用の度合いが強いですが、窓の外やバーベルなど描き直してる部分も多いです。とは言え先に何十枚か生成したものを具体的に参考にできるので、何も無しの状態から描くよりはサクサク作業できますね。
背景の壁に貼っとくポスターもAI生成すっぺ。

じゃあ+1時間30分ほどディテールアップしたり最終的な色調整したら完成です…。

完成!所要時間9時間!
これは時短になってるんでしょうか。どうなんでしょーか。今回はグリザイユの工程を挟むので、前回のAI着色記事より時間がかかってるのは仕方ないですし、AI着色物からカラーリングの大幅変更し易いなどメリットは沢山あります。恐らく手描きと比較した場合の時短効果は2時間程度でしょう。ただAI生成にかかる時間を含まなくてこの時間なので、実時間としてはうーん、どうでしょう。
まだ作業として最適化できてない部分が多いので、更に時間短縮の余地はありそうです。最近はこの手法で何枚か描いてみてそれなりに手応えを感じているので、しばらく続けてみたいですね。
では今回は以上です。
この記事が気に入ったらサポートをしてみませんか?