【BigQuery・Geo Viz】地理情報をPythonでBigQueryにデータを入力したり、可視化してみる

BigQueryってなんですか?
概要
Google Cloudの列志向なデータウェアハウス
データウェアハウスってのはデータを保存したり、検索したりできるサービスのことです
データベースと比べるとデータの蓄積に主眼が置かれていて、ビッグデータ志向なサービスになっています
SQL文をサポートしている
爆速で検索できる
データウェアハウスだけどACID特性がある(Google Cloud)
何に使える?
一般的にはData Analytics用途に使われることが多いようです
とにかく爆速なので理にかなった使い方ですね
使ってみる・前準備
Python側の準備
次の環境で作業しました
python = "^3.9"
Flask = "^3.0.1"
numpy = "^1.26.3"
google-cloud-bigquery = "^3.16.0"
google = "^3.0.0"
pandas = "^2.2.0"
pyarrow = "^14.0.2"
jupyter = "^1.0.0"データの調達・前処理
人工的なデータセットを使っても面白くないので、AMeDASのデータを使います
気象情報データですね
観測所の情報はこちらから取得できますhttps://www.jma.go.jp/bosai/amedas/const/amedastable.json
Jupyterで成形・可視化するとこんな感じです:
url = "https://www.jma.go.jp/bosai/amedas/const/amedastable.json"
data = requests.get(url).json()
amedas_spot_df = pd.DataFrame().from_dict(data).T
amedas_spot_df.index.name = "spot_id"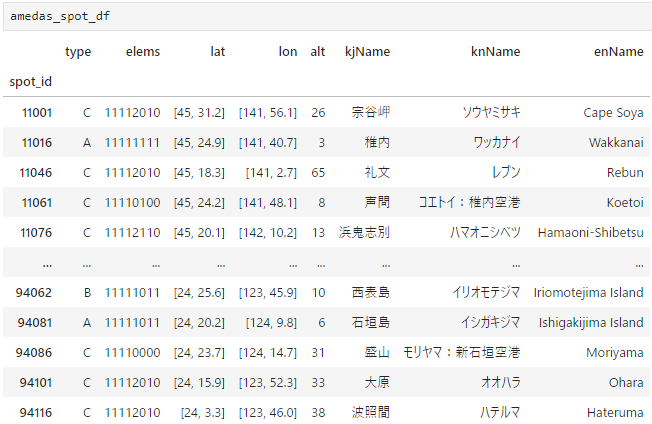
気象情報はこちらですhttps://www.jma.go.jp/bosai/amedas/data/map/YYYYMMDDHHMMSS.json
(YYYY:年、MM:月、DD:日、HH:時、MM:分、SS:秒)
こちらもpandasで成形しました
実際には最も多くの気象情報が出力されています
url = "https://www.jma.go.jp/bosai/amedas/data/map/20240405120000.json"
data = requests.get(url).json()
amedas_request_df = pd.DataFrame().from_dict(data).T
amedas_request_df.index.name = "spot_id"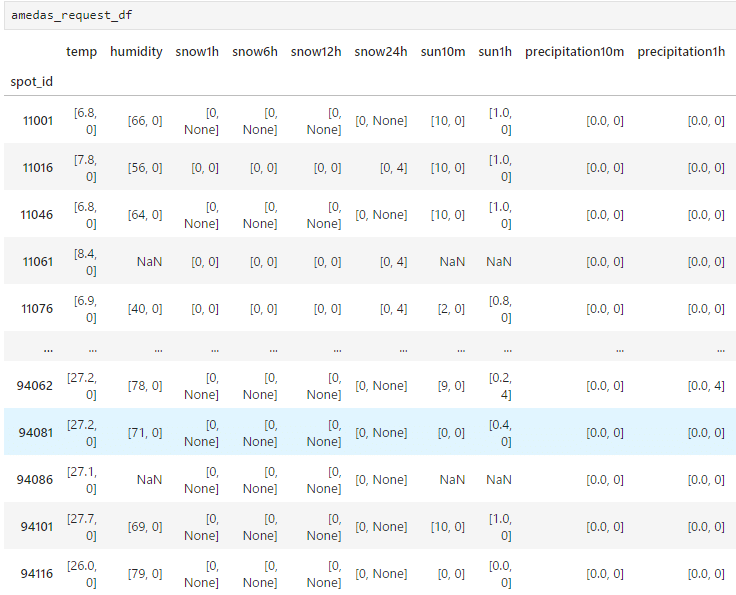
amedas_spot_dfとamedas_request_dfを組みにすれば地点名kjNameと気象情報を紐づけられそうですね
データの前処理
位置情報のテーブルを成形していきます
applyとlambda関数の組み合わせで整えていきましょう
lat (緯度)とlon(経度)が[a, b]となっていますが、aが度、bが分のようでしたので、a + b/60で度に直しています。
amedas_spot_df['spot_id'] = amedas_spot_df['spot_id'].apply(lambda x: str(x))
amedas_spot_df['elems'] = amedas_spot_df['elems'].apply(lambda x: str(x))
amedas_spot_df['lat'] = amedas_spot_df['lat'].apply(lambda x: x[0]+x[1]/60)
amedas_spot_df['lon'] = amedas_spot_df['lon'].apply(lambda x: x[0]+x[1]/60)
amedas_spot_df['point'] = amedas_spot_df.apply(lambda x: 'POINT(%s %s)'%(x['lon'], x['lat']), axis=1)
amedas_spot_df = amedas_spot_df.drop(columns=['lat', 'lon'])
amedas_spot_df = amedas_spot_df.reindex(['spot_id', 'type', 'elems', 'point', 'alt', 'kjName', 'knName', 'enName'], axis=1)
amedas_spot_df
次は観測データのテーブルを成形していきます
こちらの[a, b]となっているものは、aが正の値、bが負の値を示しているということのようです
nullの欄はそのままnullにしています
def preprocess_weather_info(x):
try:
return -1 * x[1] if x[1] != 0 else x[0]
except:
return
amedas_request_df['spot_id'] = amedas_request_df['spot_id'].apply(lambda x: str(x))
amedas_request_df['temp'] = amedas_request_df['temp'].apply(lambda x: preprocess_weather_info(x))
amedas_request_df['humidity'] = amedas_request_df['humidity'].apply(lambda x: preprocess_weather_info(x))
amedas_request_df['wind'] = amedas_request_df['wind'].apply(lambda x: preprocess_weather_info(x))
amedas_request_df['pressure'] = amedas_request_df['pressure'].apply(lambda x: preprocess_weather_info(x))
amedas_request_df['obs_at'] = amedas_request_df['obs_at'].apply(lambda x: datetime.datetime.strptime(x,"%Y-%m-%d %H:%M:%S%z"))
amedas_request_df = amedas_request_df.rename(columns={'temp':'temperature'})
amedas_request_df
BigQuery・前準備
他の多くのサービスの多くがそうであるように、BigQueryでも認証→データ処理の順番で作業をします
前準備: サービスアカウントの準備
で、その認証のためにはサービスアカウントが必要なので、サービスアカウントを作りましょう。
わかりやすい参考サイトがたくさんあるので、いったん省略します
公式はこちらです
操作を行う前の認証
テーブルを走査する前にこんな感じでclientを取得します
ここで取得したclientを後の処理で渡して、実際の処理を行います
def init_client():
key_path = "(サービスアカウントキーファイルへのパス)"
credentials = service_account.Credentials.from_service_account_file(
key_path, scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
return bigquery.Client(credentials=credentials, project=credentials.project_id)BigQuery・クラスの実装・テーブルの作成
テーブルの作成・クラスの定義
次のような階層構造でテーブルを作ります
[project直下]
| -- amedas_bq : データセット
| -- amedas_location : 地点情報・amedas_spot_df向けテーブル
| -- weather_info: 観測データ・amedas_requet_df向けテーブル
まず、amedas_spot_df向けにamedas_locationというBigQueryテーブルを用意してあげます。こんなクラスを作りました
class handling_bigquery:
def __init__(self, client:bigquery.Client):
dataset_id = "{}.amedas_bq".format(client.project)
self.dataset = client.get_dataset(dataset_id)
def creaet_table(self, client:bigquery.Client):
table_id = "{}.{}.{}".format(client.project, self.dataset.dataset_id, self.dataset_name)
table = bigquery.Table(table_id, schema=self.schema)
client.create_table(table)
def record_insert_from_dataframe(self, client: bigquery.Client, dataframe):
table_id = "{}.{}.{}".format(client.project, self.dataset.dataset_id, self.dataset_name)
job = client.load_table_from_dataframe(dataframe, table_id)
job.result()
def record_insert_from_dict(self, client: bigquery.Client, dict_data_list):
table_id = "{}.{}.{}".format(client.project, self.dataset.dataset_id, self.dataset_name)
job = client.insert_rows_json(table_id, dict_data_list)簡単に説明するとこんな感じです:
BigQueryではテーブルを(プロジェクト名).(データセット名).(テーブル名)として指定するので、table_idの記述がこのようになっています
client.create_tableでテーブル作成です
レコードのinsertはJSON (dict型)からでも、pandas DataFrameからでもいろいろ可能です
後は先ほどのクラスを基底クラスとして、テーブルごとに新たなclassを定義します:
class amedas_location(handling_bigquery):
def __init__(self, client:bigquery.Client):
super().__init__(client)
self.dataset_name = 'amedas_location'
self.schema = [
bigquery.SchemaField("spot_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("type", "STRING", mode="NULLABLE"),
bigquery.SchemaField("elems", "STRING", mode="NULLABLE"),
bigquery.SchemaField("point", "GEOGRAPHY", mode="NULLABLE"),
bigquery.SchemaField("alt", "FLOAT", mode="NULLABLE"),
bigquery.SchemaField("kjName", "STRING", mode="NULLABLE"),
bigquery.SchemaField("knName", "STRING", mode="NULLABLE"),
bigquery.SchemaField("enName", "STRING", mode="NULLABLE"),
]
class amedas_weather_info(handling_bigquery):
def __init__(self, client:bigquery.Client):
super().__init__(client)
self.dataset_name = 'weather_info'
self.schema = [
bigquery.SchemaField("spot_id", "STRING", mode="REQUIRED"),
bigquery.SchemaField("temperature", "FLOAT", mode="NULLABLE"),
bigquery.SchemaField("humidity", "FLOAT", mode="NULLABLE"),
bigquery.SchemaField("wind", "FLOAT", mode="NULLABLE"),
bigquery.SchemaField("pressure", "FLOAT", mode="NULLABLE"),
bigquery.SchemaField("obs_at", "TIMESTAMP", mode="NULLABLE"),
]AMeDAS地点データでテーブルを作る
後は、そのままインスタンスを作って、create_tableを呼ぶだけですね
bq_client = init_client()
amedas_location_table = amedas_location(bq_client)
amedas_location_table.creaet_table(bq_client)結果はこちらです

いい感じに値が入っています!!
AMeDAS観測データでテーブルを作る
先ほどの要領でテーブルを作り、データをインサートしてみます:
bq_client = init_client()
amedas_weather_table.creaet_table(bq_client)
amedas_weather_table.record_insert_from_dataframe(bq_client, item_list)
なんだかレコードがnullだらけです!!
原因: nullのレコードがあるとDataFrameからうまくデータをインサートできない
nullのデータはNoneとしてデータをインサートしなくてはならないのですが、pandasでのNaNはNoneではありません
そうした型のミスマッチがこうした奇妙な挙動を引き起こすようです
なので、こちらに対してはDataFrameからでなく、dictからインサートしてみました
前処理はこちらです
col_key = amedas_request_df.keys()
amedas_request_df.replace({np.NaN: None}, inplace=True)
amedas_request_df["obs_at"] = amedas_request_df["obs_at"].apply(lambda x: x.strftime("%Y-%m-%d %H:%M:%S"))
item_list = [{key : item[i_] for i_, key in enumerate(col_key)} for item in amedas_request_df.values]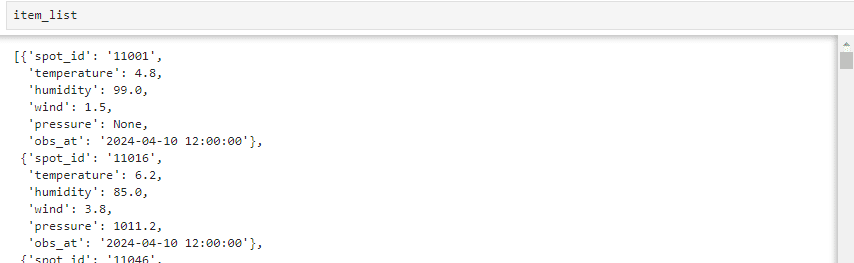
これをインサートしてみます
bq_client = init_client()
amedas_weather_table.creaet_table(bq_client)
amedas_weather_table.record_insert_from_dict(bq_client, item_list)
成功です!!
データの検索、テーブルのジョイン
テーブルを無事作成できたので、BigQueryでもテーブルジョインしてみましょう
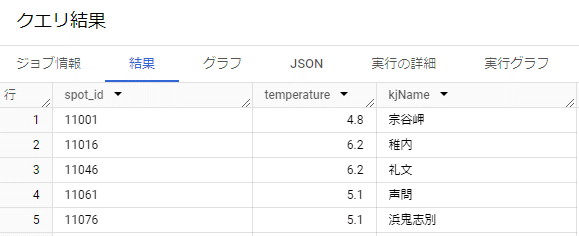
SELECT
weather.spot_id, weather.temperature, loc.kjName
FROM `t-gateway-373112.amedas_bq.weather_info` as weather
LEFT JOIN `t-gateway-373112.amedas_bq.amedas_location` as loc
ON weather.spot_id = loc.spot_id LIMIT 1000いい感じですね!
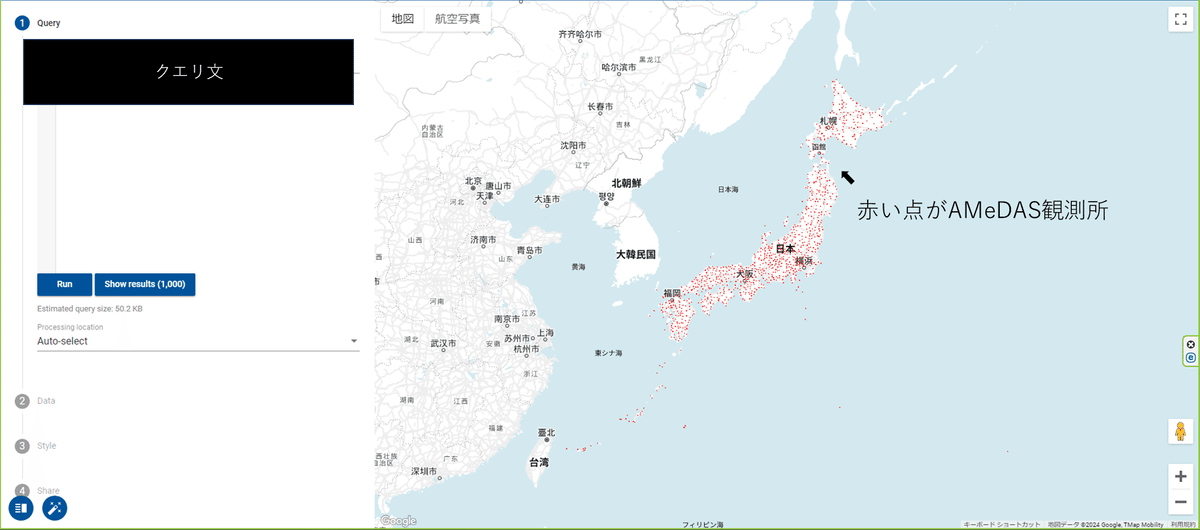
Geo Viz
BigQuery上でGeometry型を使ったカラムのクエリ結果の可視化用にBigQuery Geo Vizというサービスが提供されています
使い方は超簡単です(公式)
1. GeoVizウェブツールを開く
2. 承認をクリック
3. クエリを実施
ただクエリを実施しているだけですが、地図上にデータが描画されています!!
まとめ・雑感
こんな感じでAMeDASのデータ取得からテーブル作成、SQL文の実行までを試してきました。
現実的には世間の気象予報システムは非常によくできているので、自分で何かアプリを作ることはないような気もしますが(←その用途であればJavascript系統でアプリを作ったほうが良い)、AMeDASも使いやすいサービスになっていることを確認できました
この記事が気に入ったらサポートをしてみませんか?