
BigQuery の ScheduledQuery で小さく始める ELT

こんにちは!
QRオーダー & 決済チームでサーバーサイドエンジニアの濱口です。今回はチームで活用しているデータの加工・集計処理についてまとめてみました。
現状
ユビレジでは、サービスのログなどのデータを BigQuery にためて分析に利用しています。
各プロダクトのデータが BigQuery にそれなりに溜まっていて、QRオーダー & 決済チームでは必要な分析に応じて Ruby で API を叩いて加工・集計するレポーターくんを通して利用していました。定期実行に関しては GitHub Actions のワークフローで行なっています。また一部 Firestore からもデータを引っ張ってきており、図にすると以下のような感じです。
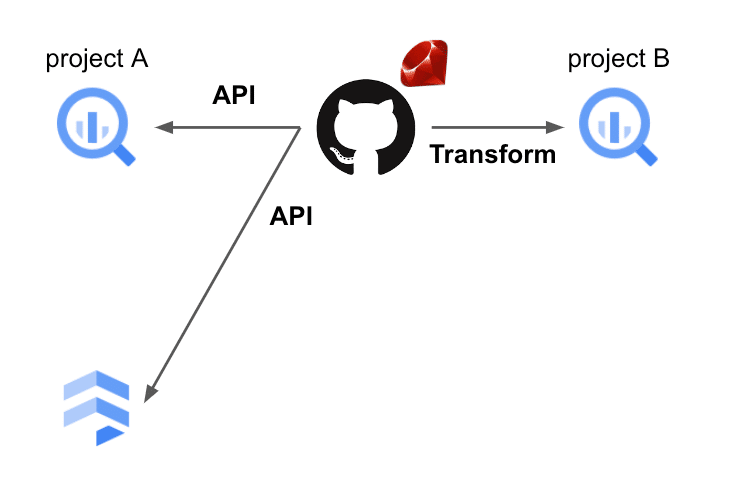
これでもやりたいことは実現できているんですが、運用における学習コストが高いのと、データの集計・加工処理が増えてきた時に GItHub Actions で定期実行するのはパフォーマンス的にいかがなものかと思っていました。
じゃあどうやるか
Ruby で API 叩いてゴニョゴニョしている部分をフル SQL に置き換えて、Github Actions で定期実行しているのを BigQuery の ScheduledQuery(スケジュールされたクエリ) に任せる構成に変えてみます。また Firestore から抽出していたデータは BigQuery に転送するようにしました。図にすると以下のような感じです。
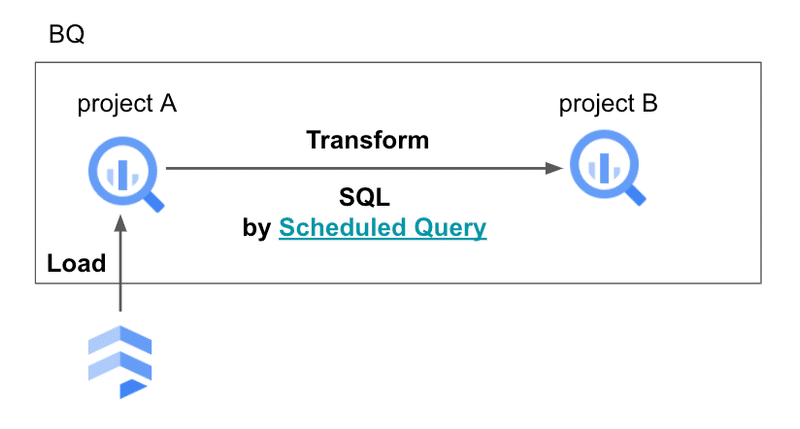
ScheduledQuery とは
簡単に言うと、標準 SQL で作成したクエリを定期的に実行するようにスケジュールできる機能です。追加課金は不要で、コンソールからアドホックにクエリを実行するのと変わりません。
実行したいクエリと宛先テーブル、実行タイミングと頻度などの設定を行うだけです。その他の設定の詳細に関しては上記の公式ドキュメントを参照してください。
メリット
1. クエリに集中できる
データの加工や集計に関する本質的な部分に集中できることが一番のメリットだと思います。BigQuery 内で完結するので、GitHub Actions のワークフローのメンテや API の使い方をキャッチアップする必要もありません。SQL さえ書ければ BigQuery でのデータ集計・加工処理を実施できるので学習コストも低くなります。
2. Terraform で管理できる
BigQuery で作成するほとんどのリソースは Terraform で管理できます。テーブルやデータセットはもちろん、スケジュールクエリやユーザー定義関数、IAMポリシーなどにも対応しています。
何をどこまで管理するのが良さそうかという部分に関しては議論の余地があるかもしれませんが、バージョン管理のための一つの選択肢としては良さそうですね。
デメリット
1. BigQuery Scripting を利用できない
BigQuery Scripting を使用したクエリは ScheduledQuery で実行することができません。設定しようとすると以下のようにエラーが表示されます(右上ですね)
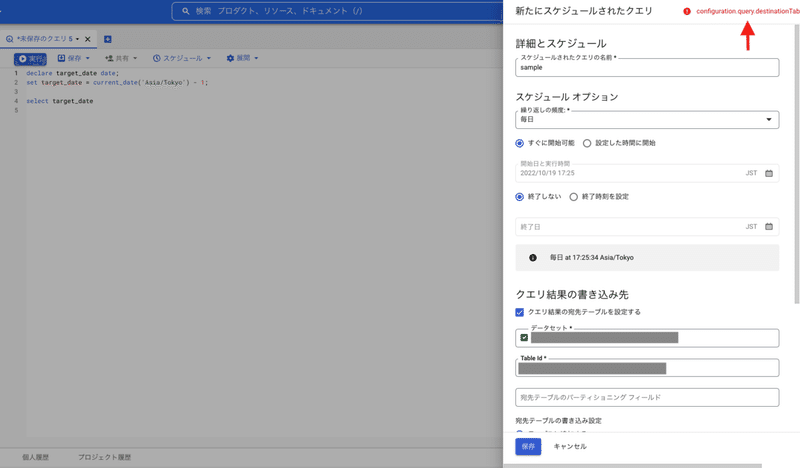
繰り返し使う変数などを定義しておいたりそのほかにも何かと便利なのですが ScheduledQuery では利用できません。
2. 後々に運用を工夫する必要は出てくる
数が少なくて把握できる内はコンソールぽちぽちで設定を追加するのでも良いかもしれませんが、スケジュールクエリが増えてきたり、新しい人が入ってきたりすると何がどういう集計をしているのかを把握しづらいといった問題が出てくるかもしれません。
そうなる前に Terraform で管理するように整備したり、別途 dbt ツールの導入などが必要になるかもしれません。
まとめ
小さく始めるなら ScheduledQuery は便利
ScheduledQuery では BigQuery Scripting が利用できない
データ利用が活発になり組織が拡大すると、運用をどうするかちゃんと考える必要は出てくる
フェーズによって変わるとは思いますが、とりあえず小さく始めるなら ScheduledQuery 便利だよって話でした。
この記事が気に入ったらサポートをしてみませんか?