
VOICEVOXをpythonから遊ぶメモ

このメモを読むと
・VOICEVOXのエンジンを導入できる
・音声データを生成できる
・GPUを使って高速に処理できる
検証環境
・Windows11
・VRAM24GB
・ローカル(Anaconda)
・2023/6/M時点
事前準備
VOICEVOX
無料で使えるテキスト読み上げソフトウェアです。
商用利用可なモデルも多数揃っているので、導入して遊んでみます。
下記記事をまるっと参考にさせていただきました。
VOICEVOX導入
とても簡単です!
1. 下記からエンジン本体[Windows(GPU/CUDA版)]をダウンロード
2. ダウンロードしたものを7Zipで解凍(展開)し、任意の場所へ格納

完了です。
VOICEVOXを使ってみる
VOICEVOXの使い方は下記の2ステップです。
・エンジン(ローカルサーバー)を起動する
・エンジンにリクエストを投げて音声を生成する
エンジン起動
コマンドラインから下記を実行します。
cd (エンジン格納先)\windows-nvidia
run.exe --use_gpu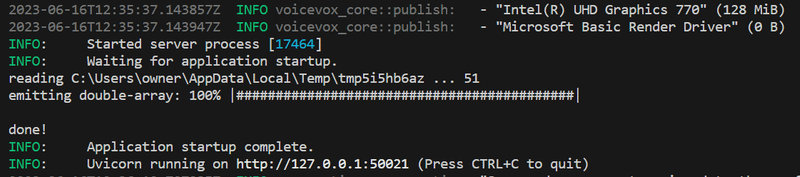
音声生成
1. エンジン起動とは別のコマンドラインから仮想環境に切り替え、必要パッケージをインストール
conda create -n voivotest python=3.10
activate voivotest
pip install requests simpleaudio2. 好きな名前で下記スクリプトを作成し実行します。例:voicevox.py
import requests
import json
import time
import re
import simpleaudio
host = "127.0.0.1" # "localhost"でも可能だが、処理が遅くなる
port = 50021
sleep_time = 0.5 # 文節毎の間隔
def audio_query(text, speaker, max_retry):
# 音声合成用のクエリを作成する
query_payload = {"text": text, "speaker": speaker}
for query_i in range(max_retry):
r = requests.post(f"http://{host}:{port}/audio_query",
params=query_payload, timeout=(10.0, 300.0))
if r.status_code == 200:
query_data = r.json()
break
time.sleep(1)
else:
raise ConnectionError("リトライ回数が上限に到達しました。 audio_query : ", "/", text[:30], r.text)
return query_data
def synthesis(speaker, query_data,max_retry):
synth_payload = {"speaker": speaker}
for synth_i in range(max_retry):
r = requests.post(f"http://{host}:{port}/synthesis", params=synth_payload,
data=json.dumps(query_data), timeout=(10.0, 300.0))
if r.status_code == 200:
#音声ファイルを返す
return r.content
time.sleep(1)
else:
raise ConnectionError("音声エラー:リトライ回数が上限に到達しました。 synthesis : ", r)
def text_to_speech(texts, speaker=8, max_retry=20):
if texts==False:
texts="ちょっと、通信状態悪いかも?"
texts=re.split("(?<=!|。|?)",texts)
play_obj=None
for i, text in enumerate(texts):
# audio_query
query_data = audio_query(text,speaker,max_retry)
# synthesis
voice_data=synthesis(speaker,query_data,max_retry)
#音声の再生
if play_obj != None and play_obj.is_playing():
play_obj.wait_done()
wave_obj=simpleaudio.WaveObject(voice_data,1,2,24000)
if i != 0:
time.sleep(sleep_time)
play_obj=wave_obj.play()
if __name__ == "__main__":
text_to_speech("ジャガイモはカレーに非常に良い付け合わせです。ジャガイモは、カレーに味と食感を与え、カレーがより風味豊かになるため、非常に人気があります。")音声が生成されたら成功です。
以下のように別スクリプトに組み込むことも可能です。
from voicevox import text_to_speech
text_to_speech("マイクテストマイクテスト",speaker=3) #ずんだもん speaker一覧は、サーバー起動中にhttp://localhost:50021/speakers にアクセスするとJSON 形式で取得できます。
おまけ
下記スクリプトから生成速度のテストを行うことができます。
import requests
import random
import json
from time import perf_counter
import argparse
def synthesis(
text: str, address="127.0.0.1", port=50021, speaker=0, pitch=0.0, speed=1.0
) -> float:
"""音声生成
Args:
text : 生成する文章
address : VOCIEVOXのAPIサーバーのアドレス
speaker : speaker_id
pitch : ピッチ
speed : スピード
Returns:
生成時間(秒)
"""
address = "http://"+address
query_payload = {"text": text, "speaker": speaker}
resp = requests.post(f"{address}:{port}/audio_query", params=query_payload)
if not resp.status_code == 200:
raise ConnectionError("Status code: %d" % resp.status_code)
query_data = resp.json()
synth_payload = {"speaker": speaker}
query_data["speedScale"] = speed
query_data["pitchScale"] = pitch
before = perf_counter()
resp = requests.post(f"{address}:{port}/synthesis",
params=synth_payload, data=json.dumps(query_data))
if not resp.status_code == 200:
raise ConnectionError("Status code: %d" % resp.status_code)
after = perf_counter()
return after - before
def gen_text(count: int):
return "".join(
[chr(random.randint(ord("あ"), ord("ん"))) for i in range(count)])
def get_speakers(address="127.0.0.1", port=50021):
address = "http://"+address
speakers = {}
resp = requests.get(f"{address}:{port}/speakers")
resp_dict = resp.json()
for i in resp_dict:
speakers[i["name"]] = {}
for s in i["styles"]:
speakers[i["name"]][s["name"]] = s["id"]
return speakers
def bench(length: int, count=10, address="127.0.0.1", port=50021, quiet=False):
synthesis("test", address=address, port=port)
tmp = 0
for i in range(count):
text = gen_text(length)
elapsed_time = synthesis(text, address=address, port=port)
tmp += elapsed_time
if not quiet:
print(i+1, "time:", elapsed_time)
result = round(tmp / count, 4)
return result
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"-s", help="VOICEVOX API Server Address", default="127.0.0.1")
parser.add_argument("-p", help="VOICEVOX API Server Port", default=50021)
parser.add_argument("-q", help="Quiet benchmark log", action="store_true")
parser.add_argument("-w", help="No wait for key input",
action="store_true")
parser.add_argument("--ssl", help="Use SSL", action="store_true")
args = parser.parse_args()
if not args.w:
input("Press Enter key to start benchmark...")
if args.ssl:
ADDRESS = "https://" + args.s
else:
ADDRESS = "http://" + args.s
score_10 = bench(length=10, address=args.s, port=args.p, quiet=args.q)
score_50 = bench(length=50, address=args.s, port=args.p, quiet=args.q)
score_100 = bench(length=100, address=args.s, port=args.p, quiet=args.q)
score_avg = round((score_10 + score_50 + score_100) / 3, 4)
resp = requests.get(f"{ADDRESS}:{args.p}/version")
info_engine = resp.text.replace("\"", "")
resp = requests.get(f"{ADDRESS}:{args.p}/supported_devices")
info_devices = resp.json()
if info_devices["cuda"]:
info_device = "CUDA"
elif info_devices["dml"]:
info_device = "DirectML"
else:
info_device = "CPU"
print()
print("=========== Info ===========")
print(" Engine:", info_engine)
print(" Device:", info_device)
print("========== Result ==========")
print(" 10: ", score_10)
print(" 50: ", score_50)
print(" 100:", score_100)
print(" Avg:", score_avg)
print("============================")
print()
if not args.w:
input("Press Enter key to exit...")
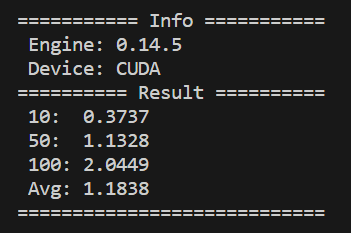
生成速度がイマイチな場合はGPUを使えていない可能性があります。
動作確認に活用できそうですね。
おわり
VOICEVOXを使って音声を生成できた。
参考資料
・無料で使用可能な音声合成ソフトをPythonで喋らせてみた - OVERS (zigexn.co.jp)
・API として使う方法 [VOICEVOX] – Site-Builder.wiki
この記事が気に入ったらサポートをしてみませんか?