
KoboldAI + TavernAI使ってみた

「パソコンの中にChatGPTがあれば推しと無限会話できるんじゃね!?」というモチベーションでTavernAIを導入しました。
こっちの記事の続編として書いてますが、ぶっちゃけ以下のWikiだけ読めば分かると思います。
また、いろいろ躓いてはいますが、Wikiをちゃんと読めば分かる範疇です。ちゃんと読まなかったから転んでいる部分が多いです。
Wikiをちゃんと読まないとこうなるよというお話です。
導入でスッ転ぶの巻
OSError:[WinError 126] 指定されたモジュールが見つかりません。とか言われるんだけど!
これは色々関連要素が足りないかおかしい場合です。
Wikiに従って、install_requirements.batを実行してどのオプションでも1を選びましょう。
私はそれで治りました。ちょっとダウンロードには時間がかかりましたが。
なんかうまく動かないんだけど!?
結果的には上手くいったのですが、大量の凡ミスで躓きました。本編はここです。
キャラクターを選んでない?
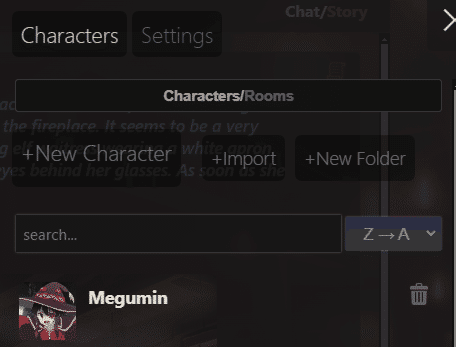
わかりました。選びます。右の三本線メニュー(ハンバーガーメニュー)を押すと出てくる次のメニューで選べます。
ちゃんとダブルクリックして、真ん中の画面が変わったのを確認しましょう。
No connectionって言われて何うっても反応しないよ!?

API urlを入れてませんでした。
さっきの三本線メニューの「settings」をクリックして設定しましょう。
ちなみにここでChatGPTやClaudeのAPIキーを入力することもできますが、今回はローカル環境なのでKocoldAIです。

KoboldAIを起動していることを確認して、Connectを押してください。
Read Onlyと言われるんだけど!!

KoboldAIの方のURL、http://127.0.0.1:5000/を開いてちゃんとモデル設定をしましょう。

ここのLoad Modelから、好きなのを選びましょう。
私はWikiでは「8GB程度のVRAM向け」項目でおすすめされていたpygmalion-6bを選びました。
Wikiで14レイヤーにしとけって言われたから、14レイヤーで設定したら動かないんだけど……。

Wikiの「KoboldAI + TavernAI上でPygmalionをインストールする」項目で、
ただし、8GBのVRAMを搭載している多くの人にとっては、14レイヤーで十分です。
と書いてあったので、NVIDIA GeForce RTX 3060 Ti Layers(前半はお使いのグラフィックボード次第です)を14にしないといけないと思っていました。
実際は28レイヤー全部グラフィックボードに乗せて大丈夫でした。
グラフィックボードが積んであるなら14レイヤーの話は真に受けないほうがいいかもしれません。
あるいは、グラフィックボードは14レイヤーにしないといけないと思い込んで、CPU7レイヤー、Disk7レイヤーと分割をしたのがいけないのかもしれません。そりゃ計算できないよ。
推しと喋りたいですよね?
実は、最初の画面に出ている画像はリンクになっています。

ここで有志が勝手にアップした二次創作設定ファイルを探せます。推しの英語つづりを覚えておくとハッピーになれます。
日本語で会話したいんだけど!?
2024年4月27日 実際にやったので追記。
日本語で学習されたモデルを拾ってくる
キャラ設定をテンプレートに従って日本語で書く
というのが必要です。
日本語で学習されたモデルを拾ってくる
KoboldAIのモデル選択画面では、ローカルにあるモデルファイルも選択できますので、そこで拾ってきた日本語モデルを選択すればいいです。

で、私はここでちょっと躓きました。KoboldAIの単体動作するLite版だと動いたモデルが動かなかったです。なんでかは知りません。
設定画面がPygmalion-6bの時と違い、しかも読み込んでも動きませんでした。
結果的に量子化していないモデルなら動くことが分かりました。つまり、拡張子が.binや.safetensorsのものです。
おすすめはこれ。
ちょっとひねったことを言っても理解してくれる印象があり、かつ無限ループや怪文書を生成しない印象です。さすが色々つよつよなモデルをマージしただけあるという性能です。
git cloneすると26.9 GBあるので注意。モデルのsafetensorだけだと14GB程度です。
注意がもう一点あります。
フォルダ内にGGUFファイルなど、LLMに関連したファイルがあった場合、サブフォルダまでは検索してくれません。
実例を出すと、こんな感じです。
model/
│
├── LightChatAssistant-TypeB-2x7B_iq4xs_imatrix.gguf
│
├── Antler-7B-Novel-Writing_IQ2_S.gguf
│
└── Antler-7B/
├── model-00001-of-00003.safetensors
└── この階層は検索がされないじゃあGGUFファイルを個別にフォルダに入れればいいかというと、ダメでした。
つまり、以下のようにしましたが、ダメでした。
model/
│
├── LightChatAssistant-TypeB-2x7B_iq4xs_imatrix/
│ └──LightChatAssistant-TypeB-2x7B_iq4xs_imatrix.gguf
│
├── Antler-7B-Novel-Writing_IQ2_S/
│ └── Antler-7B-Novel-Writing_IQ2_S.gguf
│
└── Antler-7B/
├── model-00001-of-00003.safetensors
└── まだ読まれない結局、今はGGUFの拡張子をLLMだとは思われないようなものに変更(.---ngとか、本当に存在しないような拡張子)にした結果、読み込まれるようになりました。
キャラ設定をテンプレートに従って日本語で書く
実はキャラ設定は英語のままでも大丈夫でした。ある程度英語も学習時に混ざっているからか、性格を示すプロンプトはそのままで大丈夫です。
ただ、英語に一人称の概念がないため、一人称についてだけは添え書きしたほうがいいかもしれませんね。
一番重要なのは、First messageを日本語にしておくことだと思います。これ英語だと英語出力されると思う。
日本語化まとめ
日本語で学習されたモデルを拾ってくる
量子化がされていないものを拾う(拡張子が.binや.safetensorsのもの)
他にggufファイルがあるようなフォルダに保存しない
Firstmessageだけ日本語にすれば大丈夫
この記事が気に入ったらサポートをしてみませんか?