k-means法

教師なし学習 データを分類せよ
面白いアルゴリズムだよなー
クラスタの中心とデータとの距離の二乗、その総和を最小にしようとする。
lets go-
データを任意の数のグループに分けることができる。
直線分離のみ。
実行するたびに結果が変わることがある。(必ず最適解が出るわけではない)
最初のランダムに決められたクラスタの中心(セントろいど)に結果が依存するため、
k-means++に進化している。
セントロイド(初期値)をなるべく離すというもの。ってかsklearnではデフォルトなので気にする必要なし。
クラスタの数を決めるのが難しい。そのためにx-meansがある。
情報量基準を使う。尤度を計算するようだ。ふむ。
クラスタを最低限わけて、分けた後にそのクラスターをさらに分割する。
その際、尤度が高くなれば分割、低くなればそのまま、といった方法でクラスターの数を割り出す。ほほう。
ちなみにmecabなどを使って、形態素解析をした自然言語もクラスタリングできるようだ。これは便利そう。
というわけで実践編。
ここから
ってか手法めっちゃいっぱいあるし。
datetime, string扱えない。

ふむ、できた、がどう解釈できるのだ。時系列でやったのはちょっと無理あったのかな。

次元削減して可視化したい。
PCA?SVD?UMAP?
とりあえずSVD。


うーん、沼。
倉敷のオープンデータ使って実験する。
地区別 年齢別人口

SVDで次元削減。
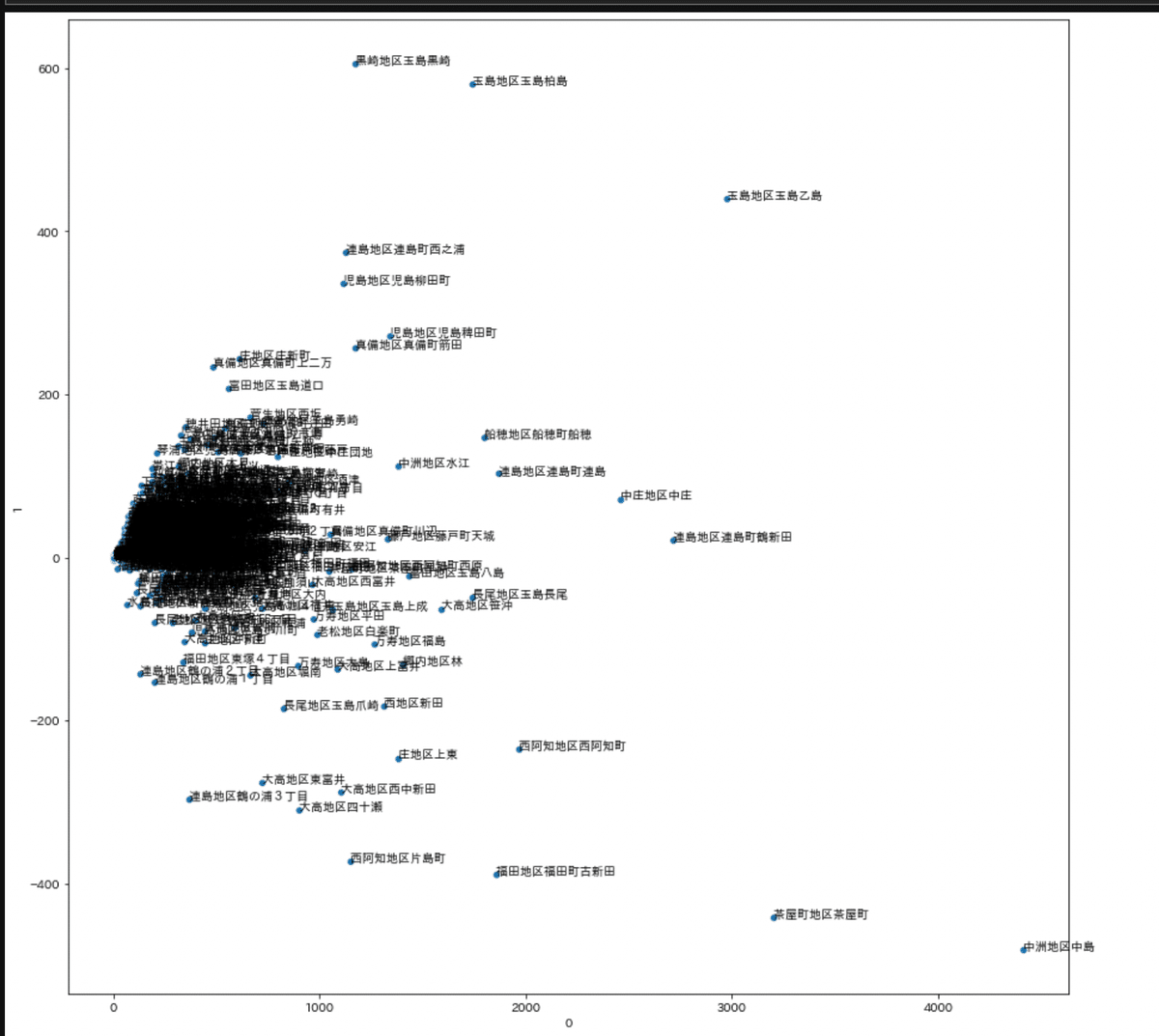
右に行くほど総人口が多いってことでいいのかな。

どやら上に行けば行くほど、高齢者が多い。
これを4つのクラスターに分けてみる。

これって、要は人口の多い少ないを4グループに分けてると解釈できる。

グループ分け後の平均値。
うん、kmeansにちょっと慣れた。
人口でもいいんだろうけど、十段階評価とか
、一個一個の数量の差が大きすぎない時の方が効果を発揮しそう。
ふう疲れた=。
この記事が気に入ったらサポートをしてみませんか?