pythonで機械学習「野菜価格予測」

初nishika。
まずはデータ確認。

過去の価格と天気から、2022年5月分の野菜価格を予測するもの。
まずは、学習データから。
野菜は44種ある。

取引量(数量と書いてあるので、kgではない?)で、並べ替えて見ると、キャベツ・玉ねぎ・大根と続く。
testデータに44種の野菜全て含まれるわけではなく、16種のみとなっている。テストデータにはないが、学習データには含まれる野菜が、どう影響するのか(相関があるのか、例えば、テストデータにはない、しめじや榎茸が生椎茸に影響するのかどうか)は調べてもいいかもしれない。関係がないなら学習データから除外してよい。

卸売価格の中央値でソートするとこんな感じ。松茸高い。
今回で言うと、ランキングはそんな重要ではない気がするけどね。
野菜一種見てみる。’だいこん’

天気データをどのように活用しようか。
学習データと天気データのareaはどんな感じか。


うーん。学習データと天気データのareaは調整が必要。また、学習データと天気データが膨大な割に、テストデータはコンパクト。テストデータを元に考えてみる、あと、前年同月の平均かなんかとって一旦提出して点数のベースラインが欲しい。
ちなみに、評価指標はRMSPE。
平均二乗パーセント誤差の平方根(RMSPE:Root Mean Squared Percentage Error)
予測 ー 正解値を正解値で割って、二乗して(マイナスをとって)SUMして、平均をとったもの。
dfのdateを年と月日に分割したい。
こんな簡単なものに苦労してしまった。今度からエクセルでやろうかなw
きっともっといい書き方あるけど、こんな感じでやった。
まずくっつけ、
all = pd.concat([train,test],axis=0,sort=False)
データの型を変えて、
all['date'] = all['date'].astype(str)
days = []
for id, row in all.iterrows():
day = row[1][4:]
days.append (day)
days = pd.DataFrame(days)
all = all.reset_index()
all = all.join(days)勉強になったのは、
iteritems() → カラム名、カラムのデータ(Series形状)を返す
あと、.append。
あとは、グループにして平均にしただけ。
では、投稿してみる。
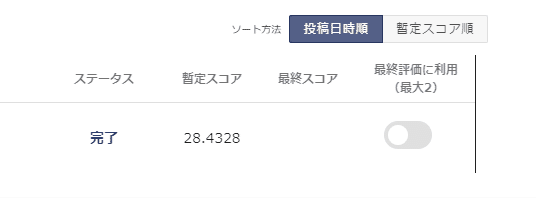
こんな感じ。20は切っていかないと話にならんですね。
今日はここまで。
アイデア
野菜の生育適温
野菜の生育期間
生育期間内の、
最低気温 最高気温
日照時間合計値
日照時間 平均
去年の平均価格 最高 最低
この記事が気に入ったらサポートをしてみませんか?