
MWC Barcelona 2024への参加レポート第二弾:最新テクノロジーの紹介・今後の展望

はじめに
こんにちは!GEOTRAインターン生の伊藤です。
当社社長の陣内が、スペイン・バルセロナで開催された世界最大級のモバイル技術の展示会及びカンファレンスである「MWC (Mobile World Congress) Barcelona 2024」に、KDDIブースでの講演のスピーカーとして参加しました。
本記事では、陣内のイベント参加レポートの第二弾として、「MWCで注目した最新テクノロジー」をご紹介します。
1. MWCの概要・GEOTRAのプレゼンテーション(第一弾はこちらから)
2. 最新テクノロジーの紹介・今後の展望
代表取締役社長 陣内寛大が注目する最新テクノロジー
SKテレコム〜生成AIが変えるデータ分析〜
概要
SKテレコム社は、韓国最大の通信事業者の一つとして、高品質で幅広いサービスを提供しており、近年は、AI分野の開発・投資を推進しており、グローバルにAI事業を展開しています。
MWC2024では、同社が開発したAI秘書の「A.」、医療AIサービスの「X Caliber」を含む10種類のAIテクノロジー・サービスを展示しました。
同社は、世界初の韓国語の大規模言語モデル(Large Language Model、以下LLM)を開発し、同社が提供するAI関連の事業で活用し、新規サービスを提供しています。

出典:SKテレコム社HP、 SKT to Showcase AI Technologies at MWC Barcelona 2024より引用
同社のLLMは、キャリア通信のロジックと知識を学習した特化LLMで、新規サービスのみならず、顧客管理・マーケティング等の領域でも活用できます。
LLMとは?
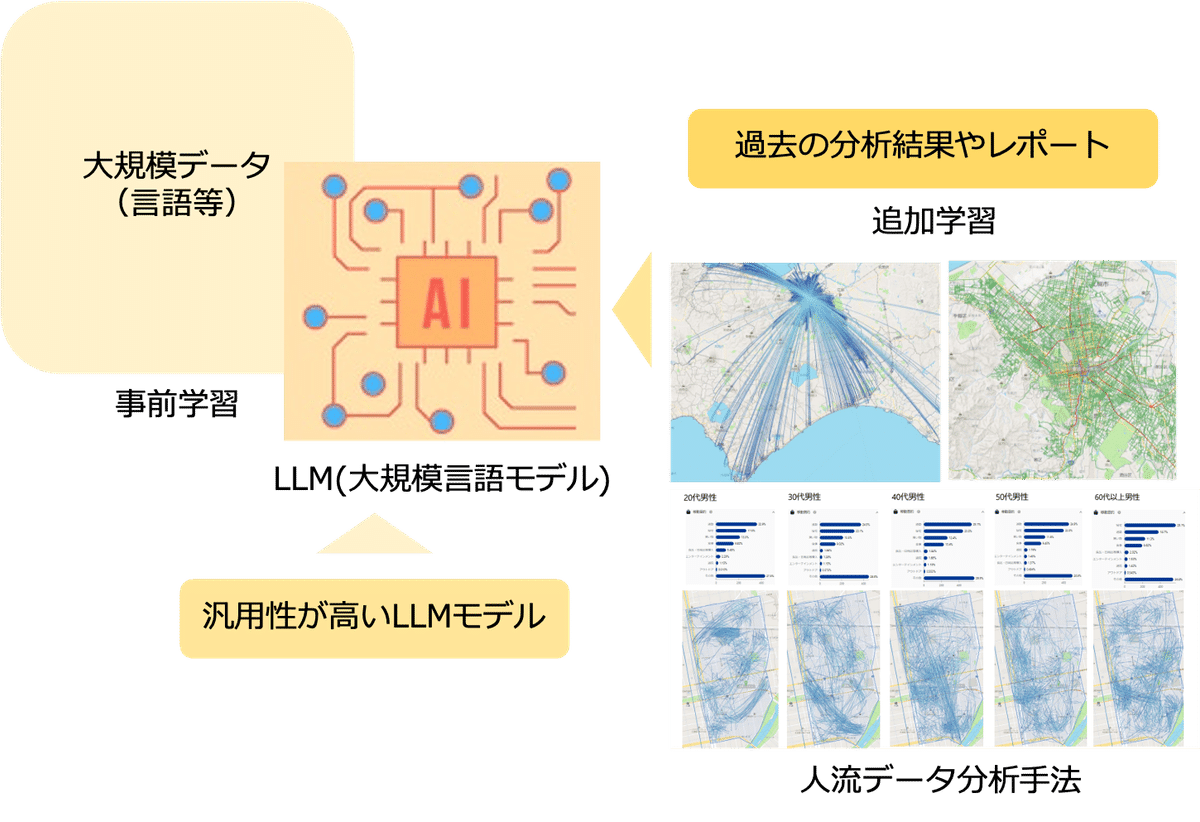
LLMは、大量の言語等のテキストデータを事前学習して自然言語のパターンや構造を理解し、個別の追加学習を行うことで、人間のような文章の生成・言語に関するタスクを実行する従来の言語AI以上に高精度な言語モデルである。
機械学習と深層学習の技術を駆使して、膨大な量のデータから言語の複雑なパターンを抽出し、そのパターンを元に新しい文章を生成するほか、言語に関するタスクを解決することができる。
具体的取り組み:人流データ分析サービス(Location AI Technology)×生成AI
SKテレコム社は、同社のLLMを基盤に、様々なサービスを展開しており、その一つがAI基盤の位置分析プラットフォームの「LITMUS(リトマス)」です。
同社は、LITMUSを通じて、同社の基地局情報やAI技術を用いて可視化した人流データから移動情報(時間・手段)や移動目的を分析するプラットフォームを顧客に提供します。

出典:LITMUS TRAFFIC Solutionのスクリーンショットより引用
脱炭素分野等で活用され、都市・交通・環境などの問題を解決しており、同サービスは「MWC2023グローバルモバイルアワード」の「都市のための最高のモバイル革新事例」部門を受賞しました。
「MWC2024」では、LITMUSのプラットフォーム上で、同社のLLMを基盤とするチャットボットで仮想顧客を具現化したサービスを展示しました。
利用者が、チャットボット上で分析内容を質問すると、AIがプラットフォームの内容を分析し、AIによる分析の結果を、生成AIを用いて回答するサービスを展示しました。

出典:'SK Open API, LITMUSより引用
陣内のコメント
「データ分析のあり方を根本的に変えるシステムだと感じました。AIが分析から結果に基づく示唆出しまで行うため、データを見るという行為自体が不要になると思います。
生成AIを人流データの分析において活用するサービスは日本にはまだ展開されていないサービスであるので、AIを活用することで、人流データのサービスを更に展開する余地が国内にあると思います。」
今後の展望〜LLM×生成AI×データ分析の融合〜
生成AI×LLM×データの融合が持つ意味
MWC2024を通じて、「ユーザーの体験」を向上するデータ分析とAIテクノロジーの融合の必要性を強調しています。
特定のパラメータや条件に基づいて文章を生成するテキストに特化した「LLM」と、人の指示から文章や表などのテキストデータ及びイラストや写真等の画像データを生み出す「生成・対話型AI」のデータ分析への融合は、プログラム言語だけでなく、普段用いる自然言語でのデータの取り扱いを可能にします。
陣内は、AIがデータ分析・示唆の提示まで行うことで、デジタル化やAI活用に伴う業務効率化以上の「データを扱う」行為の意味の変化や、ユーザーが「データ」を扱うに至るハードルの解消の可能性を示唆しています。
“今後の展望”を実現するためのチャレンジ
陣内は、データ分析とLLMの融合を行うために、「データベースの整備」というシステム領域での取り組みの必要性を強調しています。
具体的に、データベースの整備には、主に「どのようにLLM・生成AIがデータを学習するか」と「どうデータを管理するか」の2種類の取り組みの重要性を示唆しています。
①データ学習
LLMを訓練し、使用時に正確な答えをAIから得るには、大量のテキスト・画像データセット及び言語モデルの事前・追加学習が必要です。
更に、LLMがユーザーの科学的テキストを理解し、「人流データ」の分析を行うためには、一般的なテキストデータだけでなく、過去の人流データの分析結果や目的に特化したデータソースを用いてLLMを訓練する必要があります。
同時に、データソースの信頼性と質を確保する必要があり、データクリーニングやデータ整形プロセス等を行う必要があります。
②AIのモデルの活用・管理〜セマンティックレイヤー〜
学習した言語モデルを活用・管理するための重要な技術として注目されているのが、セマンティックレイヤーです。
LLMがユーザーからの自然言語入力を元に正しいデータ分析を行うためには、「データの構造や関係性を正しく定義した辞書」が必要になります。
「辞書」の役割を果たし、生成AIが正しいデータセットを出力することが出来る様にする役割を担うのが、蓄積したデータ(DWH)とBIツールの間に位置する「セマンティックレイヤー」です。
セマンティックレイヤーは、データの指標の意味及びデータを集計する際の方法などを定義した辞書を含んでおり、これらをLLMにインプットした上でデータ分析タスクを行うと、LLMの正答確率が飛躍的に高まることが分かっています。

陣内は、MWCを通じて、当社のサービスの質向上のために生成AIを活用するためには、ドキュメントを管理するレイヤーの必要性を実感し、データを介する基盤であるAPIの整備の必要性を強調しています。
最後に
本記事では、当社社長の陣内が参加したWMCのイベントレポートの第2弾として、SKテレコム社のLLMの活用事例をご紹介しました。
GEOTRAでは、独自の個人情報保護技術により、人々の動きや行動目的などが高粒度に可視化された人流データ、GEOTRA Activity Dataをご提供しています。更に人流データのご提供に留まらず位置情報データ全般に関する利活用促進のためのご支援を行っております。

noteでは、引き続きGEOTRAの事例紹介や活動報告、GEOTRAに関連するテーマの特集や事例研究を掲載していきます。
今後も皆さんのお役に立てるコンテンツを配信できればと思っておりますので、皆様のいいね・フォローをお待ちしています!