
初めてのPython--DictReader編--

こんにちは。
外出自粛で暇すぎるので、Pythonのお勉強でもしておこうかと。
前回、CSVファイルを読み込むことが出来るようになりました。
そこで今回挑戦したいのはDictReader。
DictReaderを使ってみる
標準クラスのようです。
リファレンスを見るだけだと使い方がよくわからないけども、これだけで辞書に読み込めるということのよう。
reader = csv.DictReader(csvfile)やってみます。
1.CSVファイル用意。
key:都道府県コード、value:都道府県名の2列だけ。
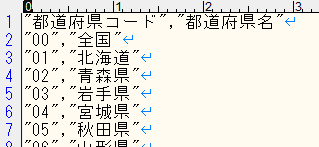
2.コードをコピペして、列名だけ修正。
with open('data/dict.csv', 'r') as f:
reader = csv.DictReader(f)
for row in reader:
print(row['都道府県コード'], row['都道府県名'])3.実行。
いつもそうなんですけど、Pythonって簡単ですよね。
他の言語だと、やってみて「はい、エラー。今度は何?」というエラーつぶしが必須なんですが(私の場合はとりあえずやってみるスタイルなのでw)、Pythonはほとんどがコピペでさらっと行けちゃう。優しい。
全部dictに入れる
1行ずつ取り出せるのはわかったのですが、withの中で1行ずつ処理するのではなく、dictに全部入れておいて後から取り出したい。
実際の業務で何か使うとなるとそういう使い方もありそうなので実験。
import csv
# dict変数を用意 ※1
data={}
with open('data/dict.csv', 'r') as f:
reader = csv.DictReader(f)
for row in reader:
# keyとvalueの列を取り出してdataに追加 ※2
data[row['都道府県コード']] = row['都道府県名']
# dictから取り出す ※3
print(data['03'])ぐぐってもちょうどいいものが見つからなかったのですが、おそらくこんな感じ?
これは結構悩みました。
※1では、dictの宣言の仕方がわからず。これはぐぐって解決。
※2では、1行ずつ取り出さなくても纏めて追加する方法がありそう。ただ、これが一番シンプルで自分にはわかりやすかったので。
※3では、「あれ?withってどうやったら脱出できるの?」というところで悩みました。Pythonではインデントでブロックが決まると聞いていたので、インデントを無しにしたら出来ました。便利だけど、これは慣れない。

CSVファイルが2列じゃない場合
KeyとValueを勝手にdict化してくれてとても便利なDictReaderですが、対象が2列じゃなかったらどうなるんでしょう?実験してみます。
1.CSVの列を増やす

2.1行ずつ出力する
with open('data/dict.csv', 'r') as f:
reader = csv.DictReader(f)
for row in reader:
print(row)3.実行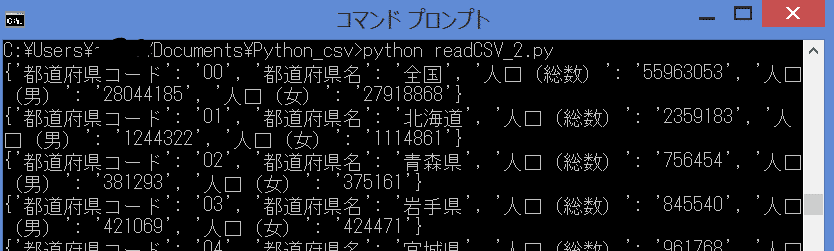
・・・おや?列が増えると、Key/Valueのセットが増えている?
Keyはデータ行ではなく、常にヘッダ行ということだったのか。
イメージはこう。Key:赤、Value:青
誤:データ行の中でKey/Valueが勝手に作られる。

正:ヘッダー行がKey、データ行がValueになる。

なるほど。
となれば、列がいくら増えても関係ないですし、確かにこちらのほうが便利。
盛大な勘違いでしたが、検証してみた甲斐があるというものですね。
今日はここまで。
次回はこれを視覚化するとか、、、かな?
この記事が気に入ったらサポートをしてみませんか?