微分方程式の数値解析②【反復法のPython上でのプログラミング】
前回,偏微分方程式を解くための方法としてクランク・ニコルソン法というものまで紹介しました.今回からは,そのクランク・ニコルソン法を用いて,次の具体的なフォッカー・プランク方程式を解く問題をPython上にプログラミングすることを考えます.一風変わったフォッカー・プランク方程式ですが,これは以前の記事で登場した,カエルの分布についての時間発展方程式です.

反復法の一種であるガウス・ザイデル法によってこの方程式を数値的に解くことを考えます.反復法は,初期値を設定し,繰り返し計算することで正しい解に近づいていくような方法です.反復計算せず,直接逆行列を求めるような方法もありますが,数値計算につきものの丸め誤差を嫌って,今回は反復法を用います.許容誤差を自分で設定できるのが反復法のメリットです.
クランク・ニコルソン法の復習
フォッカー・プランク方程式

は,クランク・ニコルソン法によって離散化すると,

となる,ということを前回学びました.下付きの添字は空間の格子点を,上付きの添字は時刻の格子点を表しています.ここで,
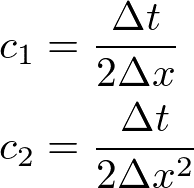
であって,また今の場合,ドリフト係数と拡散係数は時間には依存せず,
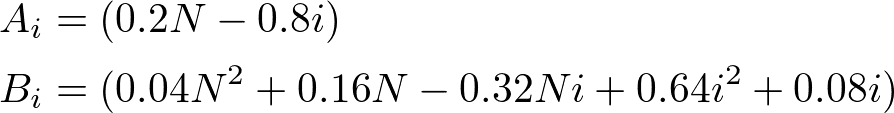
となっています.
反復法その1 ヤコビ法
クランク・ニコルソン法の公式は単純化して書くと,
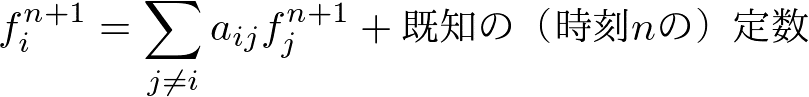
という形で空間の格子点に関しての連立一次方程式になっています.
これを,次の漸化式に置き換えてしまいます.(以下では時間に関する添字は関係ないので省略.)

右辺に勝手に初期値を定めて例えば

とし,そこから予測値を得ます.その予測値を再び右辺に代入していくことを繰り返せば,

という数列が得られます.この予測値の数列が収束するとすれば,それは求めたかった連立方程式の解と一致するはずです.漸化式を用いて収束するまで繰り返し計算する方法を反復法と呼びます.特に上の漸化式を用いるこのアルゴリズムをヤコビ法といいます.
ところで,本当に収束するのか不安になるところです.次の数学の定理が知られています.

今,行列は

の形をしています.この行列の固有値はどうなっているのでしょうか.実際に固有値を求めることなく,固有値の範囲を絞るだけなら,次のゲルシュゴリン(Gershgorin)の定理が便利です.

対角行列であれば,その対角要素が固有値になります.対角行列でないときには,各対角要素の値の付近に固有値を探すと,その行の非対角要素の和以下の範囲に見つかる,ということをこの定理は述べています.今の場合,対角要素は0であり,非対角要素は2つしかないので,

ということになります.この右辺が1以下になっていれば,収束の十分条件と言えます(必要条件はわかりませんが).したがって,パラメータの設定によっては収束しないこともあり得るものの,ドリフト係数があまり大きくなくて,時間の刻み幅もある程度小さく取れれば,解は収束するであろうことがわかります.(どれくらい小さくとるかは割と経験的な部分があると思います.)
反復法その2 ガウス・ザイデル法
ヤコビ法とほとんど同じ方法ですが,ガウス・ザイデル(Gauss-Seidel)法というものがあります.これは,クランク・ニコルソン法の公式の右辺について,すでに求まった予測値はその場ですぐに用いる,というものです.式で書けば,

ということになります.これはヤコビ法よりも早く計算が収束します.
ちなみに,ガウス・ザイデル法は書き換えた変数をその場で用いるため,並列計算には向きません.一方,ヤコビ法はそれぞれの式で独立に計算ができるため,並列計算に向いています.すなわち,ガウス・ザイデル法がいつでも良いとは言えないのが難しいところです.
__________________________________________________________________
Pythonについて
プログラミング言語にはさまざまなものがありますが,ここではPython(注:Python 2ではなくPython 3)を用います.Pythonは初心者にもわかりやすく,可読性が高いとされています.Pythonの可読性の高さは,インデントによってコードのブロックが判断されるという特徴から来ます.また,Pythonにはライブラリが豊富にあり,数値計算の目的に適うものもあります.ライブラリとは,Pythonのファイル(モジュールという)やフォルダ(パッケージという)の総称で,他のプログラムにインポートして使うことができるものです.特に,Numpy,Scipy,Matplotlibなどが有名です.車輪の再発明を避けて,効率的にプログラミングできる,ということですね.もちろん,車輪を再発明することでブラックボックスでなくなり勉強になるでしょうし,新しいことをするために車輪の再発明が必要なこともあるかもしれませんが.
インポートは,例えば次のように書くことでできます.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation一行目で,Numpyというパッケージをインポートしていて,別名として np という名前をつけています.Numpy は配列や行列を高速に扱うことができ,それらの演算も定義しているので,数値計算では基本となるパッケージです.
二行目では,Matplotlib というパッケージの中の,pyplot というモジュールをインポートして plt という名前をつけています.pyplot モジュールには,グラフを描くための機能が備わっています.さらに,グラフをアニメーションで表示するために,三行目で animation モジュールもインポートしています.これから用いるのは以上のモジュールになります.
パラメータ変数の定義
変数を用いると,処理を一般化できるので便利です.
変数とは,用意したデータを管理するための「ラベル」です.ラベルは剥がして別のデータに付け替えることもできます.物理的実体としては,データも変数も,コンピュータのメモリ上の領域に用意されます.変数の領域には「どのデータを参照するか」という情報が記憶されます.これが「ラベル」といった意味です.
変数でデータをラベル付けするには,

という形で書きます.Python では,変数を使用する前に,参照データの型(数値なのか文字列なのかなど)を宣言する必要がなく,変数とデータを関連づけたときに同時に変数が定義されます.
ここで,イコールの記号はプログラミングでは代入演算子と呼ばれ,上のように書いたときには「変数にデータを代入する」という言い方をよくします.代入と言うと変数とは何か箱のようなものであって,そこにデータを入れているような印象を持ちます.しかし初めに述べたように,変数はデータをラベル付けするものと言った方が実体にあっています.(このように理解しておかないと,ミュータブルなデータ型を扱うときに混乱すると思います.)数学的には変数からデータへの写像を意味し,イコールの記号を使うものの等式ではありませんし,代入でもありません.(英語ではassign(割り当て)というので,代入とはニュアンスが違い,こちらの方が正確に思えます.とはいえ,「箱」のイメージも普段はそこまで悪くはありません.)
さて,まず解きたい問題のパラメータを変数に割り当てる部分を書きます.パラメータの部分は適宜変更することで,さまざまな条件に対しての解を計算することができます.
# input parameter
dx = 1.0 # 空間刻み幅
xtot = 500 # カエル総数(フォッカープランク方程式の N のこと)
dt = 0.0004 # 時間刻み幅
dur = 5.3 # 計算期間
tout = 0.02 # 間引き時間間隔「#」の記号以降から改行まではプログラミングの実行の際には無視されるので,分かりやすくコメントをすることができます.
さらに,入力したパラメータから自動的に計算できる他のパラメータも記述します.
# calclated parameter
nx = int(xtot+1 / dx) # 空間的分割数
nt = int(dur / dt) # 時間ステップ数
nout = int(tout / dt) # 間引き
c1 = dt/dx/2
c2 = c1/dx
A = lambda x : 0.2 * xtot - 0.8 * x
B = lambda x : 0.04 * xtot**2 + 0.16 * xtot - 0.32 * xtot * x + 0.64 * x**2 + 0.08 * x四則演算は「+,-,*,/」の記号で行ってくれます.nxやntはそれぞれ空間,時間の分割数を表していますが,これは後で整数型として扱う必要があります.そこで,int()という関数を用いて浮動小数点型を整数型に直しています.(注:浮動小数点とは,実数を近似的に表したもので,有効桁数を固定しておき,小数点をどこに打つかはまた別に決めるような数の表現方法です.演算によってある程度桁落ちすることが前提となってしまうのがデメリットですが,広範囲な数を表現することができます.)
A,Bはドリフト係数,拡散係数ですが,これにはラムダ式で定義した関数を割り当てています.ラムダ式は次のように書くことで無名関数を定義することができます.

def文によっても関数を定義することはできますが,ちょっとした使い捨ての関数ならラムダ式で書いたりします.どちらでも同じことです.
次に,初期条件を設定します.
# initial condition
f_init = 0.0
f = np.full(nx, f_init) # fは f[0] から f[nx-1] まで
f[250] = 1.0
time = 0.0
f_old = np.zeros(nx)numpy.full(a,b) は,「a個の要素を持ち,その全ての要素がb」という配列を生成する,Numpyに含まれている関数です.ここでは,まず nx 個の要素を持ち,全ての値が f_init となる配列を作り,その後 f[250] = 1.0 と書くことで251番目の要素のみ 1.0 に書き換えています(要素番号は0から数えるので頭が混乱しないように注意が要ります).これで250が確率 1 でほかは確率 0 となるような初期確率分布を記述しています.(境界があまり問題にならない領域でフォッカー・プランク方程式を導いたので,初期分布をあまり端の方に偏らせないようにしなくてはなりません.それがどの程度なのかは,あまり深く考えないでおきます.考えてみると面白いかもしれません.)time は時間で,時間の初期値は0.0から始めています.f_old は,後で繰り返し計算するときに,値を更新する前の確率分布関数を一時的に記憶しておくための配列です.numpy.zeros は,全ての要素が 0 の配列を生成する関数です.
グラフ描画用の変数の設定
次に,グラフの描画のための変数を定義します.
# graph data array
ims = []
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
gx = np.zeros(nx)
for i in range (nx):
gx[i] = i * dximsは各時刻の図を後で追加していくための空の配列を定義しています.
matplotlib.pyplot.figure() は描画領域を用意する関数です.これだけだと単に描画領域が用意されるだけなので,そこに個別に座標軸を設定します.それがadd_subplot() というメソッドになります.メソッドとは,変数の後ろにドットを付けて記述することで呼び出す関数の一種で,変数が参照しているデータに作用して何らかの操作を行います.ちなみに,データとメソッドの組をオブジェクトと言います.
add_subplot(l,m,n) と書くと,縦に l 分割,横に m 分割し,左上から数えて n 番目の領域に座標軸を新たに追加する,という意味になります.今回表示したい図は一つなので(1,1,1)としています.
gxには横軸の値を設定しています.「for i in range(nx):」と書くと,「次の処理をダミー変数 i に対して,0から nx-1 までの範囲でその値を1つずつ増やし,繰り返せ」ということを意味します.これをforループといいます.繰り返したい処理は,コロンの後に字下げして書きます.forループを回すことにより大きさ nx の配列に一つ一つ値を設定しています.
ガウス・ザイデル法による計算
いよいよ,数値計算の主要部分を書いていきます.
# loop calculation
itr_max = 10000
for n in range(1, nt + 1): # nt まで時間発展
f_sum = sum(f)
for i in range(nx):
f_old[i] = f[i]
for itr in range(itr_max): # 繰り返し計算
resd = 0.0
eps = 1.0e-8
for i in range(1, nx-1): # 境界は除外
fx = f[i]
f[i] = ( (1 -c2 * B(i)) * f_old[i] \
+ 1/2 * ( (-c1 * A(i+1) + c2 * B(i+1)) * f_old[i+1] + (c1 * A(i-1) + c2 * B(i-1) ) * f_old[i-1] )\
+ 1/2 * ( (-c1 * A(i+1) + c2 * B(i+1)) * f[i+1] + (c1 * A(i-1) + c2 * B(i-1) ) * f[i-1] ) )\
/ (1 + B(i) * c2)
resd += abs(f[i] - fx)
if resd <= eps:
break
# apply boundary condition
f[0] = B(1) * f[1]/(dx * A(0) + B(0))
f[nx-1] = (dx * A(nx-2) + B(nx-2)) * f[nx - 2] / B(nx-1)
time += dt
# data thining out
if n % nout == 0:
print('n: {0: 7d}, time: {1: 8.1f}, sum: {2: 5.3f}, itr:{3:4d}'.format(n, time, f_sum, itr))
im_line = ax.plot(gx, f, 'b')
im_time = ax.text(0, 0, 'Time = {0: 8.1f} [s]'.format(time))
ims.append(im_line + [im_time])itr_max で繰り返し回数の上限を設定しておきます.時間ステップごとに解を記録するために,forループを回します.range(a,b) と書けば,aから始まり1ずつ増やしていき,bを超えない値までの範囲を指定することができます.
sum() は配列の要素の和をとる関数です.確率の和を時刻ごとに計算しておき,毎回ちゃんと和が1になっていることを確認するために用意しました.
各時間ステップごとに,空間の点について連立して解く必要があります.ここにガウス・ザイデル法を用います.f_old には,前の時間ステップの確率関数のコピーを作製しておきます.リストのコピーを用意したいとき,f_old = f のように書いてはいけません.リストはミュータブル(同じ変数のまま変更可能)なデータなので,このように書いた f_old は f のデータが書き変わると f_old のほうも変わってしまいます.しかし,リストの各要素はイミュータブルなので,forループを回して各要素を f_old にアサインしておきます.
次に,ガウス・ザイデル法の繰り返しを回します. for itr in range(itr_max): で始まるループです.このループの中では,f_old は既知の値として固定で,f[i] を繰り返し計算していきます.全空間について計算するために,さらにforループで計算していきます.左辺と右辺に共通の f[i] を用いることで,その都度新しい確率分布を用いて計算していることになります.一つ前計算で得られた f[i] は fx としておき,新しい f[i] との差の絶対値をとり,全空間に対して和をとったものを resd としています.if文は,ifの後に書かれた条件を満たすときだけ,その後の処理をするというものです.残差 resd が,指定した精度 eps より小さくなったらガウス・ザイデル法の繰り返しループを抜けるようになっています.
端の点だけは特殊なので,別に値を更新することにします.境界条件を設定することで解が定まります.今回の設定では,端の点では確率分布が反射すると考えます.それは,端の点において,確率の流れがないということ,すなわち

という条件を課してやることです.
結果の表示
上の各時間ステップのループ内の最後に,if文があります.% は割り算のあまりを計算する二項演算子です.数学のイコールは == とイコールを2回続けて書きます.nは時間ステップの番号ですから,noutごとに条件を満たして,データを出力させます.全てのグラフを出力するとコマ数が多くなりすぎるので,適度に間引きしているというわけです.
それぞれ,どういう値をとっているのかを確認するために,print() によって知りたいデータの中身を表示させています.単に羅列すると見にくいので,formatメソッドによって整理しています.formatメソッドは, { } 部分を format の対応する引数で穴埋めします.空欄番号は {0}, {1} のように指定でき,formatのどの引数と対応づけるのか明らかにできます.(デフォルトでは0, 1, … と順番通りです.)コロンの後には,どのように書式化するかの指定をすることができます.d によって桁数(disit)を指定でき,f によって浮動小数点(floating-point number)の桁数を指定できます.すなわち,7dと書けば7桁の整数で表され,5.3fと書けば全体で5桁の小数点以下3桁の小数で表されます.
変数axに対してplotメソッドを用いるとグラフをプロットします.x軸データ,y軸データの順にデータを指定します.'b'は線の色をblueにせよ,という意味です.textメソッドは,(テキストを表示するx座標,y座標,'表示したいテキスト')のように書くことでグラフ内に文字を表示できます.
リストに対してappendメソッドを用いると,リストの末尾にデータを付け加えることができます.+ してやれば同時に加えてくれます.im_timeの方はリストにしておきます.
forループを抜けたら,グラフの細かい設定をします.
# plot
ax.set_xlabel('x')
ax.set_ylabel('Plobability')
anm = animation.ArtistAnimation(fig, ims, interval = 50)
anm.save('animation_kaeru.gif', writer = 'pillow')
plt.show()set_xlabel, set_ylabelはそれぞれx軸,y軸の軸ラベルを指定するメソッドです.matplotlib.animation.ArtistAnimation は事前に用意した図のリストをアニメーションにしてくれる関数です.引数に(fig, ims, interval = 50)と書くことで,figというグラフ領域に,imsというグラフのリストを,50 ミリ秒間隔でアニメーション化することができます.saveメソッドは作成したアニメーションファイルを保存します.保存する名前を指定します.pillowは画像処理ライブラリです.最後にmatplotlib.pyplot.showで画像を表示します.
こうして書かれたのが以前の記事の最後のアニメーションです.
初期条件を色々変えて遊んでみてください.
今回のまとめ
反復法は,ある問題の解を求めるために,設定した初期値から繰り返し計算を行い,徐々に正確な解に近づけるアルゴリズムである.連立方程式を解くために使うことができる.収束するとは限らないため,注意が必要である.
更新履歴
2023.03.15 ゲルシュゴリンの定理のタイポを修正.
2023.03.16 Pythonのコーディングの解説を追加.
クオリティの高いノートをたくさん書けるように頑張ります!