
Whisperを使って動画で喋った内容をテキストにして要約したい

概要
最近というか近年のレベルでニコ生とかYoutubeで放送とかLIVE配信を見たりしたりしてるんですが、生は長くなりがちですよね。殆どが1時間以上、長ければ6時間とかです。ながらで見るには良いんですけど、後追いするのはしんどいというか、現実的に無理です。
そんなこんなで、喋った内容の概要があって、それが説明欄とかに書いてあったら良いと思いませんか?ということで試行錯誤してみました。
要点
一応、具体的な方法を後述しますが、手法が試行錯誤段階なため確立していないので、結構ぐちゃぐちゃですから、先に要点だけ書きます。
①動画から音声を取り出す。
②音声を文書にする。
③文書を要約する。
動画から要約を直接やれたら一番良いんですが、恐らく現状では簡単に出来ないと思われますので、段階を追ってやっています。各工程の具体的手法は幾つかあるはずなので、これが良い!というのは私にはまだ分かりません。
方法
以降は私が実践した具体的な方法です。
動画→音声
最初は動画編集ソフト(DaVinci Resolve)でやってました。


これはこれで良いんですが、後述の作業でpythonを使うので、もういっそ一緒に自動化した方が楽じゃん、という話で、今はffmpegでやってます。
import ffmpeg
stream = ffmpeg.input("movie.mp4")
stream = ffmpeg.output(stream, "voice.mp3")
ffmpeg.run(stream)ffmpeg本体をインストールしてパスを通したら、pythonのラッパ?をインストールすれば良いです。詳細は検索してもらった方が良い説明があると思うので、そちらへ委ねます。
音声→文書
ここが面倒です。たぶん本当に色々方法がありますが、私はWhisperを使いました。Whisperの使い方にも色々あるようですが、現状では自分のローカルに環境構築して使っています。一番お手軽なのは、Google Colaboratoryを使う方法ですが、mp3のアップロードが面倒だったり、無料で使える環境では速度が出なかったりで、ローカル環境を構築してます。
こちらも詳細は他の方にお任せしたいのですが、一部疑問に思ったことを後述します。
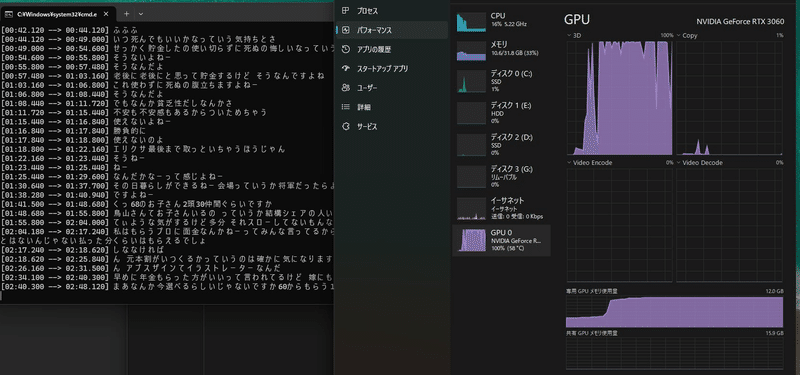
私が試した限りだと、Whisperとffmpegがあれば動くには動きました。ただし、GPUが使われないため、かなり時間がかかります。よってGPUで動かしたくなりますが、前述のページ全てでcuDNNのインストールを記載しているものの、私はcuDNNを入れても入れなくても、処理時間に変化がなく、GPUは動いているように見えました。
よって、個人的には処理時間に目を瞑るなら、Whisperとffmpegだけで良いし、GPU使いたいにしてもCUDAとPyTorchだけ入れたら良いのでは?と思っています。なお、処理時間の変化は以下に例を示します。
mp3ファイルは3分
CPU処理時間:約4分半(Core i9 13900)
GPU処理時間:約1分半(RTX3060 12GB)
タスクマネージャーのパフォーマンスを見ると、GPUが限界まで回ってるようなので、ハード性能が直に効くと思われます。
Whisperのpythonコードはこんな感じです。
import whisper
model = whisper.load_model('large')
result = model.transcribe('voice.mp3', verbose=True, language='ja')
f = open('log.txt', 'w')
f.write(result['text'].encode('cp932', "ignore").decode('cp932'))
f.close()音声変換もそうですが短くて良いですね。良い時代です。Whisperにはモデルのサイズがあるらしくて、サイズに応じて精度も違うようです。largeは一番でかくて精度が良いやつです。あとは、言語指定をすると起動が若干早いそうです。文字コードの小細工は、変な文字が含まれると保存できないとかあったので、その対策です。
文書→要約
ここが現状、私の中で一番イマイチな所です。文書要約はオンライン会議ツールとかに付属され始めて身近になりましたが、好きな文書を入力できるようなwebで公開されているサービスはどれも文字数制限とか精度とかの面で、どれもイマイチでした。
仕方なくChatGPTを説得しつつ使っているのですが、私はケチなので有料版にできていないので、色々不便です。軽く調べた?感じですと、有料版ならファイルをそのまま渡せるらしいので、前述までで用意した文書のファイルを渡せばうまい事出来る気がします。
私は仕方がないので、5000文字程度に区切って、都度要約させ、要約させた文章を繋げて、再度要約させています。この際のやり取りも確立しておらず、毎回内容に合わせて違った説得を試みています。今時のAIの使い方感あってこれはこれで面白味がありますが、面倒です。
5000文字?というのは、恐らく一度に送れる文字数が5000文字くらいのようです。これ以上の長さだとエラー?のような表示が出るので、区切らざるを得ません。
おまけ
以下は現段階で使ってるpythonコードです。
import sys
import time
import glob
import ffmpeg
import whisper
def main():
print(sys.version)
start = time.time()
files = glob.glob("*.mp4")
for file in files:
mp4_to_mp3(file)
voice_to_text(file)
end = time.time()
time_diff = end - start
print(time_diff)
def mp4_to_mp3(file):
stream = ffmpeg.input(file)
stream = ffmpeg.output(stream, file.replace(".mp4", ".mp3"))
ffmpeg.run(stream)
def voice_to_text(file):
model = whisper.load_model("large")
result = model.transcribe(file.replace(".mp4", ".mp3"), verbose=True, language="ja")
f = open(file.replace(".mp4", ".txt"), "w")
f.write(result["text"].encode("cp932", "ignore").decode("cp932"))
f.close()
if __name__ == "__main__":
main()カレントディレクトリにあるmp4から個別にテキストファイルを作成する内容になっています。ChatGPTの5000文字制約対策に、改行とか入れたいと思ってますが、おま環なので入れる前の状態で貼っときます。
この記事が気に入ったらサポートをしてみませんか?