RVCのモデルマージで架空の声のUTAUやMYCOEを作りたい覚え書き

というか作ったので同じようなことをやりたい人のために覚え書きを作っておきます。一般的なボイチェンの用途でRVCを使う場合はミリも参考にならないと思うのでご注意ください。
はじめに
この記事はRVCを使ってUTAUやMYCOEIROINKを作りたい人向けの覚え書きです。よく話題になってるリアルタイム変換とかの解説はしません。
また、筆者は生成AI系の知識もパソコンの知識もないです。なんかわかんないけど使える!で使ってるので細かい仕様はわかりません。
あと声優さんの声とか勝手に使おうとしている人は参考にしないでください。普通に考えて悪いことなので。
2024年1月時点の情報です。すぐに古くなってしまう可能性があります。
最低条件
大量のデータを保存できる余裕がある
Googleに課金できる金またはかNVIDIA製のGPUが入ったPCがある
大量のデータを保存できる余裕がある
材料になる音声wavとか各ソフトウェアとかいっぱい保存するので容量カツカツだとしにます。
Googleに課金できる金またはNVIDIA製のGPUが入ったPCがある
残念ながらRVCってまあまあいいPCがないと学習できないんですよね。
GPU必須だしなんならNVIDIA製じゃないと使えなくはないけど後々できないことが多くて不便だったりするらしいです。
ということでこちらRVCが動くであろうGPUの条件。
NVIDIA製
VRAM 8GB以上 できれば12GBとか欲しいね。
1650や1660などの16シリーズは使えない
これは罠なんですが、NVIDIA製でも1660とか書いてあるバージョンのGPU(16シリーズとかいうらしいです)は変換はできても学習ができません。
次の項目でGPUの有無やバージョンの確認方法を書いておきます。
GPUが無い場合はGoogle Colabを使うという手がありますが、生成AIが流行ったことでGoogle側の負担が大きくなったために一部ノートブックで課金ユーザーしか使えない制限がかかっており、RVC公式ノートもその対象です。
筆者は1650使ってておしまいになったので別のGPU買いました。
参考程度に買ったやつ置いておきますね。
こっちもよさそうだったんだけど玄人志向って安いかわりにPC初心者が買うと説明書とかが無くて導入で詰むってPC組むのが趣味の家族が言ってたのでやめておきました。
そしてGPU強くしたらついでに消費電力も増えちゃったので電源と変換ケーブルも買い替える羽目になったのでした。
PC内のGPUの確認方法
筆者はwin10なのでそちらでの確認方法です。
タスクバーを右クリック
↓
「タスクマネージャー」を選択
↓
出てきたウィンドウの「パフォーマンス」タブを選択
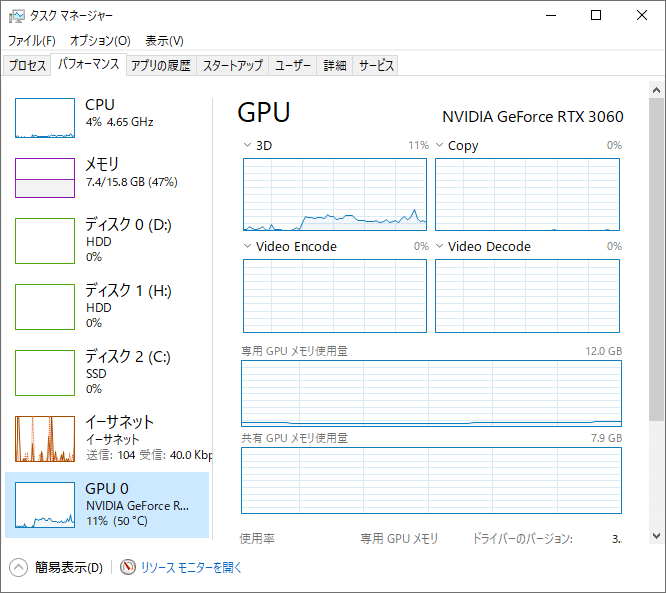
上の方に書いてある「GPU」という文字の右側にある「NVIDIA GeForce RTX 3060」という文字が使っているGPUのバージョンです。
タスクマネージャー内にそもそもGPUの項目がなかったり、GPUが16シリーズだったりしたら対応してないPCということで大体あってると思います。
RVCに学習させる音声データを用意する
学習に必要な音声データを用意します。
おそらくこの記事を参考にする人はどちらかというとUTAUやMYCOE収録の知識がある人だと思うので詳しい解説はしません。
以下は注意点や筆者の使用感など。
ノイズはなるべく少ない方がいい
wavファイル名に日本語は使わない
音声は短く切ったほうがいい
歌声と話声を両方入れたほうが多少綺麗に生成できる
声質を安定させたい場合は声質がなるべく変わらないようにする
変換前の声の強弱や声の出し方も再現したい場合はいろんな声で収録する
たぶんUTAU連続音1音階とかITAコーパスemotionのみとかがちょうどいい
アニメやCDなどのデータを勝手に使用してはいけません
長い音声で学習させてもできなくはないですが、普通に精度が落ちるのでやめたほうがいいです。コーパスとかUTAU音源とかもう短くなってるやつならそのまま学習させていいんじゃないかな。
また、もとのWAVが少なくても綺麗に変換できるのがRVCの良いところですが、できれば素材は多い方がきれいにできると思います。でも多すぎても学習に時間がかかってエラーの原因になるのでお好みで。
筆者はITAコーパスから3文抜粋したものを学習させたことがありますが普通に学習できちゃったので少なくても大丈夫ではあるみたいです。
RVCは素材になった声のバリエーションが多いほど細かいニュアンスを残したまま声質変換ができるようになります。
たとえばどんな声もささやき声に変換されるRVCを作りたいならささやき声の音声だけ用意すればOKです。
逆に声の強弱や高さ、明るさなどを変えたものをたくさん用意して学習させれば、話し方は比較的元の声に近いまま声質だけ変換させたような感情豊かに聞こえるRVCモデルが作れます。
ただし、複数話者の音声を一度に学習してしまうと、ボイチェン時に変換したい声と一番近い人の声がより強く出てしまい変換結果にムラが出るので、複数話者の声を綺麗に混ぜたいのであればマージ機能を使ったほうがいいです。
アニメキャラの声や歌手のCDの声など、ご自身に権利が無い音声を切り取って勝手に使うのはやめてください。非営利であろうとなかろうとそれをインターネット上に公開した時点ですでに個人利用の範囲ではありません。
モデルをマージして別人に聞こえるようにするとしてもやめてください。法的に問題がないことと倫理的に問題がないことは別の話です。
音声収録時にあると便利そうなツール
oremo
UTAU音源収録に特化した録音ソフトです。コーパス録るのにも便利。
公式サイトのDLリンクは使えなくなっていますが、開発者様のTwitterにて新DLリンクが公開されています。
公式サイト
http://nwp8861.web.fc2.com/soft/oremo/
DLリンク
https://onedrive.live.com/?id=4E56C6D911E0FAA3%21326&cid=4E56C6D911E0FAA3
開発者様による新リンク案内ツイート
OSDNが慢性的に不調のようなので、代替場所としてOneDriveに各ソフトのファイルを置きました。https://t.co/za3DMsZIZz
— nwp8861 (@nwp8861) August 24, 2023
ITAコーパスの文章リスト
oremoでITAコーパスを録るときに使える収録リストとwavファイルの名前をITAコーパス用に変換してくれるやつです。
MYCOEIROINK疑問符対応用 MANAコーパスoremo対応セット
oremoでMANAコーパスが録れるやつです。
ファイル名を変更してくれるやつも入っています。
wavTar
たくさんあるwavファイルを1つのwavに繋げたり繋げたwavを分解したりできるやつです。
分解の前後でサンプリングレートが違うと分解時にズレるので注意。
公式サイトから飛べるリンクは繋がりませんがoremoと同じリンクからダウンロードできます。
wavconv
たくさんあるwavファイルのサンプリングレートなどを一括で変更してくれるツールです。
wavTarで結合する前、または分解した後に使うとズレなくて済みます。
Audacity
たぶんこの記事を参考にするような人はみんな知ってる。
音声のちょっとした編集に使える波形編集ソフトです。
MIX等に使うには力不足ですが、ここだけちょっと編集したいんだよな~みたいなときにいちいちDAWを立ち上げなくて済みます。
ファイル名変更君
複数のファイルの名前を一括で変更してくれるツールです。
筆者はoremoの録音時に1行ズレちゃったをよくやるのでこいつがいないと泣きます。
UTAU音源を学習させるときもwavファイルをこれで連番にしてます。
RVCが使えるソフト一覧
RVCはよく有志が改良して派生ソフトを作るのでその時によって最適解が違うので、最初にいくつか紹介しておきます。
RVC関連の記事によく出現する「VC Client」というソフトがありますが、あちらはリアルタイムボイスチェンジャー特化なので今回は使いません。
でもVC Clientも便利なので興味ある人は調べてみてね!なんとわたしがCV担当する「黄琴まひろ」がデフォルトモデルの一人になっています。(ダイマ)
公式
とりあえずこれが公式です。
これを書いている2024年1月時点ではHugging Faceにある「RVC1006Nvidia」「RVC1006AMD_Intel」が最新版のはず。
V1とV2がリリースされており、圧倒的にV2の方がきれいなのでここではV2について解説します。
でもどうやらV3が開発中みたいなのでもしかしたらすぐ仕様が変わっちゃうかもね。
Applio
有志が改良したRVCが簡単に使えるやつです。海外ではこっちの方が主流で使われてるみたいです。
おそらく現在いちばん性能が良い事前学習モデル「Ov2Super」の開発元が使用を想定しているのは公式ではなくApplioの方っぽい。
本家RVCよりいろいろ使いやすいので個人的にはこっちのUIが好き。
…しかし、Applioはマージ機能が上手くいっていないみたいなので、もし使うなら学習と変換はApplio、マージは本家、という感じで両方使った方がよさそう。
RVC導入方法
公式RVC (ローカル)
PCがRVCに対応している人はローカルがおすすめです。
こちらのページから最新版のRVCをダウンロードして解凍します。
これを書いている2024年1月時点では「RVC1006Nvidia」が最新版です。
解凍したファイルの中に「go-web.bat」というファイルがあると思うのでダブルクリックしてください。
黒いウィンドウが出てくるのでしばらく待ってRVCのwebUIがブラウザ上で開いたら成功です。
黒いウィンドウはRVCを使い終わるまで閉じないでください。

公式RVC (Colab)
※現在Colabに課金していないため動作確認ができないので記憶だけで書いてます。今度課金したときにちゃんと書きます。
PCがRVCに対応していなかった悲しき人類はColabを使用してください。
まずGoogleドライブに学習用wavを入れてzipにしたものを置きます。今回は「voice」にしておきました。日本語は使わないでください。
次にColabのノートブックを開きます。
こちらのページがRVC V2のノートブックです。
GitHubのREADME欄にあるColabへのリンクはV1のノートブックに飛んでしまうのでご注意ください。
基本は上から順番に実行していけばOKです。
「从谷歌云盘加载打包好的数据集到/content/dataset」は一部手動で書き換える必要があります。赤字で表示されている「/content/drive/MyDrive/dataset/lulu20230327_32k.zip」を学習用zipの保存場所に変更してください。
今回は「/content/drive/MyDrive/voice.zip」に変更します。
「启动web」のセルを実行してしばらくすると出てくる2個目のURL(おそらく「Running on public URL:」の欄)にあるURLをクリックするとローカルの場合と同じようなwebUIが出てきます。
ColabはRVCを使い終わるまで閉じないでください。
Applio
まず、GitHubまたはHugging Faceからzipをダウンロードしてきます。
基本的にはGitHub版のDLの方が時間かからなくて済みそう。
インストールに自信が無くてクソデカファイルをDLしてもいい人はHugging FaceからDLして解凍するとこの後のインストールをまるっとショートカットできます。
GitHubからzipをDLした人はインストール作業が必要です。
zipを解凍してできたフォルダを丸ごとCドライブ直下に移動してください。
公式曰く一旦Cドライブ直下にインストールしてからあとで好きなとこに移動したほうがなんかいいらしい。たぶん管理者権限とかそういうの。
移動できたらrun-install.batを実行してください。
なんか黒い画面が出て文字がヴァアアってなると思います。

途中で画面が更新されずに動きが止まったように見えたりエラーっぽい文字が見えたりとなんだか心配になりますが、見えないところでめちゃめちゃ頑張って動いてるのでこの黒いのが「続行するには何かキーを押してください」といきなり日本語を話すまでそっとしておいてあげてください。
最後は指示通り何かのキーを一回押せばインストールは終了。
初回起動時になにかDLするっぽい挙動をしているので、できればいちおうrun-applio.batも実行しておいてください。
UIが起動したら黒い画面とUIをいったん閉じて、Applio-(任意のバージョン)フォルダをまるごと本来インストールしたい場所に移動すれば導入終了。
RVCで声質を学習する
おそらくこれ読んでる人類が一番知りたい部分。
ここに到達するまでで既に結構長かったね…
公式RVC
※ローカルもColab版もだいたい同じですが表示言語が違うため、Colab版を使用する場合は画像を参考にしてください。
まずwebUIの「トレーニング」タブを開いてください。

UIの説明に従って上から実行していきます。
以下はおすすめ設定
モデル名:モデル名を指定します。できるだけ英数字にしてください。
目標サンプリングレート:40kがいいと思います。
バージョン:基本はV2がいいと思います。
「トレーニング用フォルダのパスを入力してください」の欄で学習用wavが入ったフォルダの場所を指定します。
今回はわかりやすいようにするためにRVCが保存されているフォルダ内に「voice」というフォルダを作って、その中にモデル名と同じ名前のフォルダを用意しました。

Colab版の場合は基本的に「/content/dataset/ドライブにアップロードしたzipファイルの名前」になるはず。たぶん。
zipファイルそのものではなく、そのzipファイルをdatasetフォルダ内に解凍したものを指定しないと学習できないので注意。
入力したら「データ処理」を押します。
「出力情報」の枠がオレンジになってなんか文字がいっぱい出るのでしばらく放置。
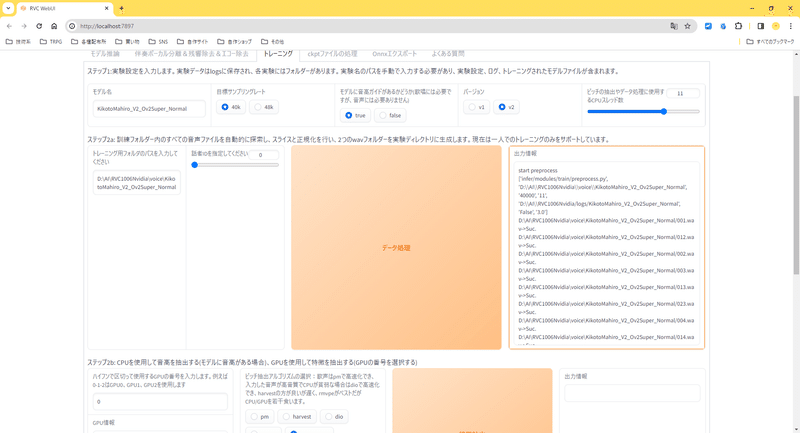
枠がオレンジじゃなくなったら完了なので次の「特徴抽出」も実行してください。
なんかGPUの番号とかピッチ抽出アルゴリズムの選択とか書いてありますが「どのGPU使うんや?」「どんなふうにピッチ抽出するんや?」って聞かれてるだけなのでこだわりが無ければデフォルトのままで学習できます。
特徴抽出も終わったらいよいよ学習開始です。
以下はおすすめ設定です。でもここはお好みで良いと思います。
エポックごとの保存頻度:10
総エポック数:100
もう何もわからない!クオリティは二の次でいいからRVCモデル作りたい!という場合はもうモデルのトレーニングに進んじゃって大丈夫です。
どうせならこだわりたいよ!という方は最後にひと手間加えます。
最近出た「Ov2Super」という事前学習モデルが公式より性能が良く、より少ないエポック数で綺麗な音声に変換できます。
つまり公式モデルと同じくらいのエポック数にすればさらに綺麗に…!?
(過学習にご注意ください。)
Hugging Faceから「f0Ov2Super40kG.pth」「f0Ov2Super40kD.pth」をDLして、RVCの「assets」フォルダ内にある「pretrained_v2」フォルダに置きます。
Ov2Superには32kモデルもありますがこちらは公式のRVCでは使用できないらしいので、間違えないように気を付けてね。
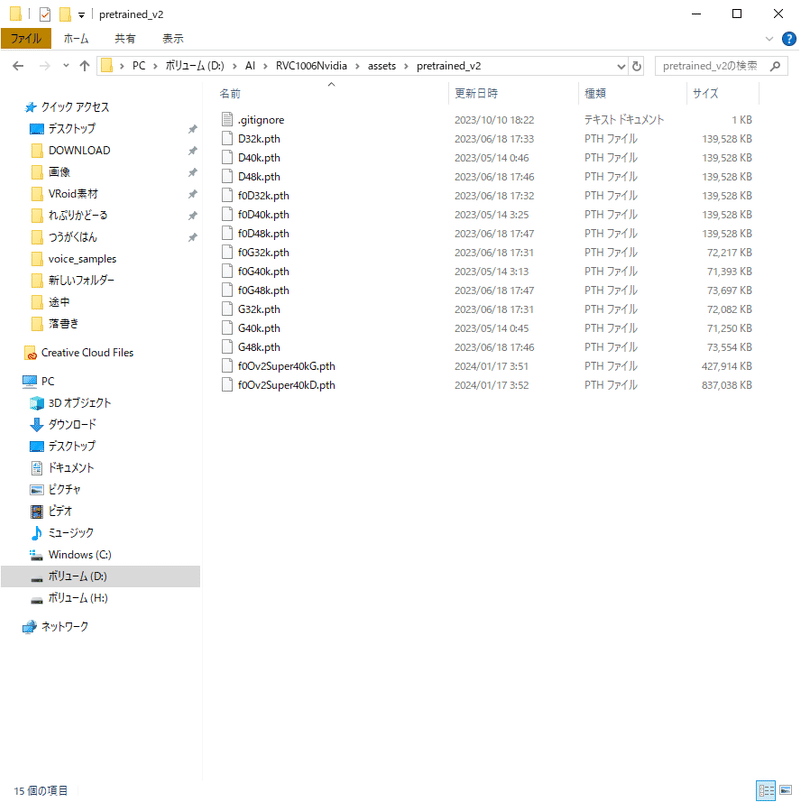
「事前学習済みのGモデルのパス」「事前学習済みのDモデルのパス」をさっき保存したOv2Superのパスに変更して、「モデルのトレーニング」を実行

「ワンクリックトレーニング」なんていう一見便利そうなボタンもありますが、こちらは時々エラーになるのでわたしは使いません。
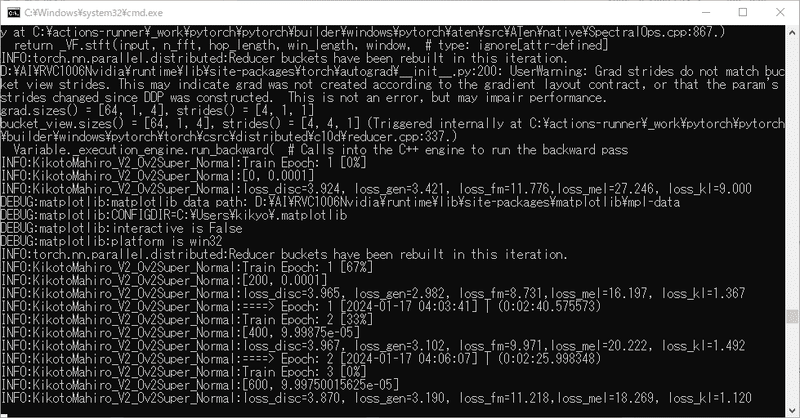
RVCをローカルで使ってると出てくるこのなんか黒い画面の下のほう見ると今何エポック目を学習中なのか見れてちょっと楽しいよ!
学習が終わって、「assets」フォルダ内にある「weights」というフォルダに指定したモデル名のpthファイルがあったら成功です。

次は「特徴インデックスのトレーニング」を実行します。
まあこれは今回の用途では使わないのですが、RVCモデルとしては作っておいた方がいろんな用途に使えるらしいのであって損はないです。
学習に使ったwavファイルが多いとエラーで生成できない時があるのでそういう場合は諦めてください。というか、エラーでindexファイルが作れないくらい豊富なwavで学習させたなら多分indexファイルが無くても綺麗な音声に変換できるのでいらないです。大丈夫です。なくても死にません。
生成したindexファイルは「logs」フォルダ内の指定したモデル名のフォルダに2個くらい入ってると思います。
なんかどっちとっとけばいいのかよくわからないのでわたしは一応両方入れといてます。
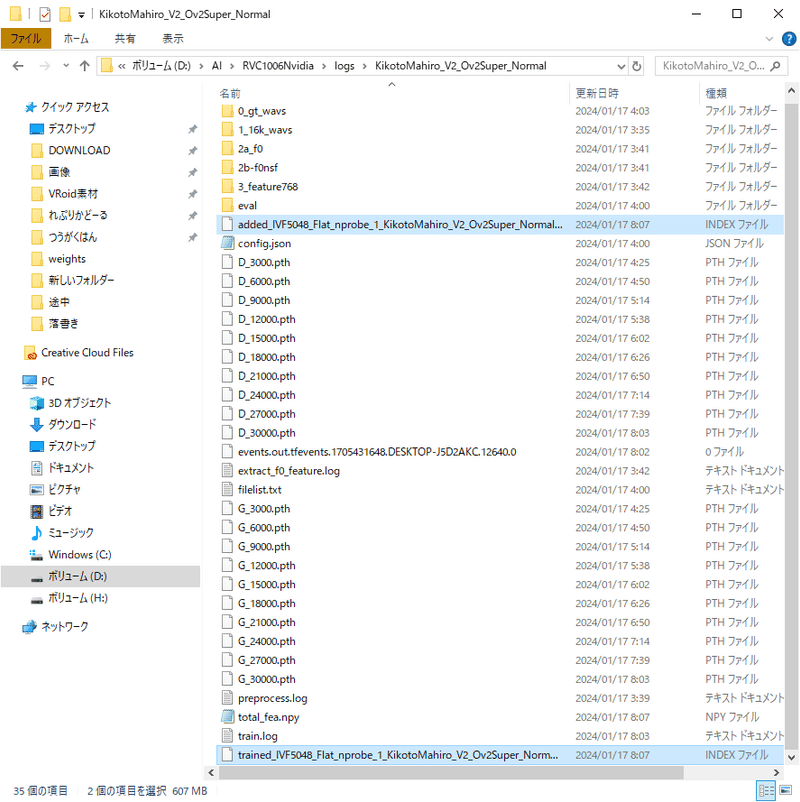
ところで怖い話をしますね。
Colab版の場合のRVC本体が保存されているフォルダは「Retrieval-based-Voice-Conversion-WebUI」なので、もちろん生成されたモデルやindexファイルも「Retrieval-based-Voice-Conversion-WebUI」内の「weights」や「log」にそれぞれ生成されますが、こちらGoogleドライブに保存してくれているわけじゃないので、colabの接続が切れたら作ったモデルたちも消えます。無慈悲に消えます。
なくなったら困るファイルは完成次第DLしておくようにしましょう。
Applio
まず、run-applio.batを実行してください。
最初に黒い画面が出て、しばらく待つとUIが出てきます。

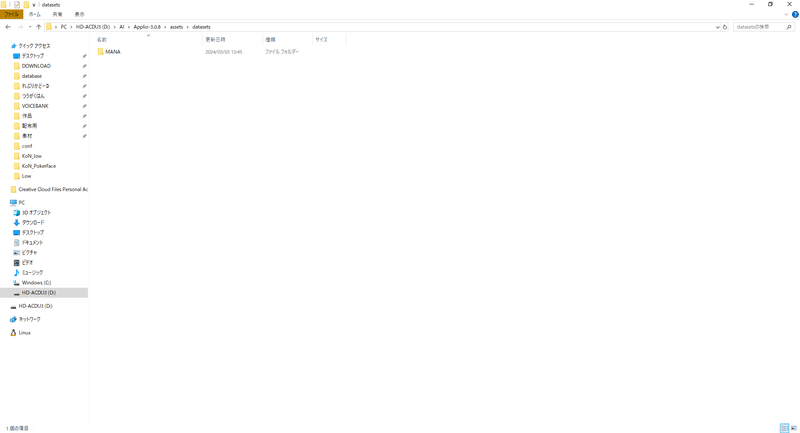
用意した学習用の音声が入ったフォルダを「assets」フォルダ内の「datasets」フォルダに入れてください。
UIの「学習」タブを開いて、「データセットの更新」を一回押してください。
そうすると「データセット パス」の欄でさっき入れたフォルダが選べるようになると思います。

無事に選択できたら「モデル名」の欄で任意の名前に変更してから「データセットの前処理」を押してください。
なんかロード中みたいな感じになると思うので、終わるまで放置。
「Model (モデル名) preprocessed successfully.」と出たら次の「特徴量の抽出」もこだわりが無ければそのまま押しちゃってOK。
抽出も終わったら、いよいよ学習です。
以下はおすすめ設定です。でもここはお好みで良いと思います。
エポックごとの保存頻度:10
総エポック数:100
もう何もわからない!クオリティは二の次でいいからRVCモデル作りたい!という場合はもう「トレーニングを開始」を押して大丈夫です。
さらに品質を上げたい人は事前学習モデルを変えます。
まず、Hugging Faceから「f0Ov2Super40kG.pth」「f0Ov2Super40kD.pth」をDLして、「rvc」フォルダ内にある「pretraineds」フォルダのさらに中にある「pretraineds_custom」フォルダ内に置きます。

次にUIの「カスタム事前学習済みモデル」にチェックを入れます。
なんかいろいろ出てくるので、とりあえず「カスタム事前学習済みモデルの更新」をクリック。
そうすると「Custom Pretrained G」「Custom Pretrained D」でさっきDLしてきた事前学習モデルが選択できます。
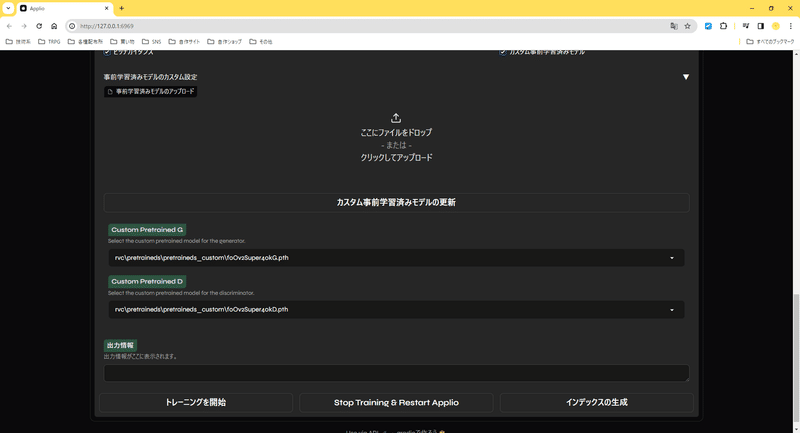
全部選べたら「トレーニングを開始」を押してしばらく放置してください。
おわったら「インデックスの生成」もしておくと後々楽かも。
完成したデータや学習進捗は「logs」フォルダ内に保存されています。
RVCでボイチェンさせてみる
モデルが制作できたら試しに使ってみてください。
架空の声でボイチェンさせたい場合は先にモデルのマージをしてください。
ボイチェンさせたい音声のwavが複数ある場合はあらかじめwavTarで繋げておくと楽です。
公式RVC
「モデル推論」タブを開いてください。

まず、「音源リストとインデックスパスの更新」を押してください。
これはweightsフォルダとlogsフォルダを再度読み込みするボタンなので、それぞれのフォルダをいじったりモデルを増やしたりしたら毎回押してください。
次に、「音源推論」の下にある空欄をクリックして、学習したモデルを選んでください。
「処理対象音声ファイルのパスを入力してください」の欄にボイチェンさせたい音声のwavが保存されているパスを入れます。なるべく日本語は使わないようにしてください。
このまま「変換」ボタンを押せば変換できるはずです。しばらく待つと出力音声の欄に再生ボタンが現れるので一旦聞いてみてください。

聞いてみて問題が無ければそのままwavファイルをダウンロードできます。
もし声が高すぎたり低すぎたりした場合は「ピッチ変更」で数値を入力してみるか、ボイチェンさせたい音声のwavをあらかじめピッチ変更しておくといい感じになります。
特にUTAUなどの歌唱合成の場合はピッチ変更すると音階が変わってしまうので、あらかじめwavファイルをピッチ変更してからボイチェンしたほうが管理しやすいかもしれません。
この記事の通りに制作した場合、変換したwavのサンプリングレートが40k固定なので、適宜変換して使用してください。
Applio
まず「推論」タブを開いて「リフレッシュ」を押してください。
リフレッシュはlogsフォルダを再度読み込みするボタンなので、それぞれのフォルダをいじったりモデルを増やしたりしたら毎回押してください。
次に、「音声モデル」欄から使いたいモデルを選んでください。
インデックスファイルは使っても使わなくてもいいです。
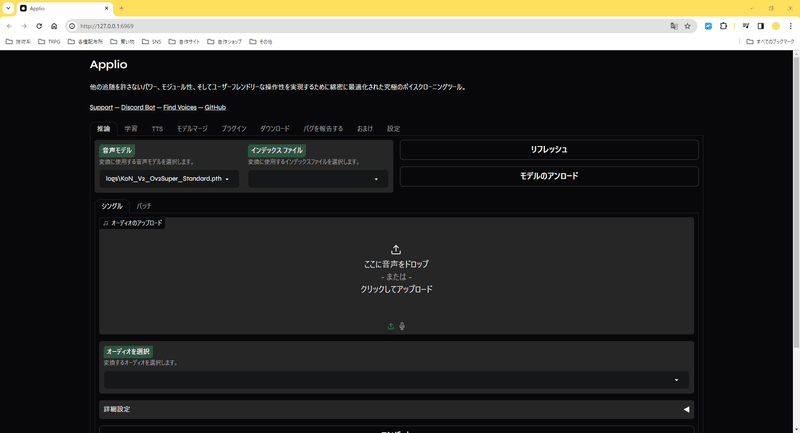
「ここに音声をドロップ」のところに変換したい音声を入れて、「コンバート」を押すと音声が変換されます。
「詳細設定」の欄をクリックするとなんかいっぱい出てくるので、いろいろいじってからコンバートしてみるのもいいかもしれません。
「シングル」「バッチ」タブの「バッチ」では複数音声を一度に変換したりもできます。
この記事の通りに制作した場合、変換したwavのサンプリングレートが40k固定なので、適宜変換して使用してください。
RVCモデルをマージさせる
ここがわざわざ音声合成にRVC使う理由の大部分よね。
まずはマージさせたいRVCモデルを2つ作ってください。これは同じ人の声色違いでも別人2人の声でも問題ありませんが、他人の声を勝手に学習させたりマージさせたりするのはやめましょう。
あてがなければとりあえずつくよみちゃんとか使ってください。
いまのところマージは本家RVCじゃないと使えないっぽいです。
公式RVC
まずは「ckptファイルの処理」タブを開いてください。

AモデルBモデルそれぞれのパスを入力します。
「Aモデルの重み」はどれくらいAモデル寄りの声にするかを決められます。デフォルトはちょうど50%になるように設定されています。
「拡張子のない保存するモデル名」でモデル名を指定します。
「モデルのバージョン」はマージさせるモデルに従ってください。この記事に従ってモデルを制作した場合はV2です。
あとは「マージ」ボタンを押せばweightsフォルダ内にマージ済みのモデルが生成されるので他のモデルと同様に使えます。
マージで作ったモデルをさらに別のモデルとマージさせることもできますよ!
RVCでボイチェンした音声で作れそうな音声合成ソフト一覧
自分でモデルを作れる音声合成ソフトのなかからよさげなのを紹介しておきます。他にも探せばいろいろあると思う。
音声AIはいろいろ触っておくとあっちのソフトで覚えた知識がこっちのソフトで役に立つ、みたいな部分が多いのでたのしい。
UTAU
歌詞とメロディを打ち込むと歌ってくれるやつです。
AIではなくゴリゴリの人力なので学習が必要ないかわりに原音設定とかいう初心者にはえぐい作業が必要になりますが、本人は歌う必要が無く音痴でも作れるのでうれしい。
多分現状の歌声合成の基本になるやつなので、一旦UTAUを作ってからENUNUとかDiffSingerとかにチャレンジすると分かりやすいのかなあなんて思います。
ENUNU
ちょっとあんまり詳しくないのですが、NNSVSをUTAUで使用することでAI歌唱にできるやつらしいです。
歌唱DBの収録カロリーが高いしラベリングとか音程をなんやかんやするやつとか、しっかりとした専門知識と忍耐が必要らしいのですが、そこを過ぎればbatファイルを実行するだけで学習できるらしいので、Colabの接続切れるのとかを心配しなくていいのがうれしい。
DiffSinger
これもAIで歌声合成できるやつらしいです。
歌唱DBとラベリングは必要らしいですが、言語の壁さえ突破できればENUNUより敷居が低いとか。どうやらColabで学習できるらしい。
MYCOEIROINK
日本語でTTSできるソフトウェア「COEIROINK」のユーザーモデルを制作できるサービスです。ITAコーパスまたはMANAコーパスで制作できます。
最低10文からなので制作コストも低くて日本語の分かりやすい説明もある!!必要なのは時間だけ!!
公式ではColabでの学習がメインですが、RVCがローカルで動くPCを持っている人なら頑張ればローカルでもいけました。
多分TTS作るなら現状はこれが一番サポートも手厚いし参考になる記事も多いのかなって思います。
Style-Bert-VITS2
豊かな感情表現に特化したTTS「Bert-VITS2」を有志が改良したものです。
AIが文脈から感情を読み取りそれに合った音声を生成してくれるほか、手動でどんな感情のスタイルで読んでほしいかを指定することができます。
また、日本語で録音したコーパスを学習させた場合でも、英語、日本語、中国語に対応したトリリンガルにできます。
コーパスの指定がないのでどんな文章でも使えます。公式でローカルとColab両方あるので好きなほうを選べるのもうれしい。
この記事が気に入ったらサポートをしてみませんか?