Lookerでデータ指標の乱立を解決する【データ利活用の道具箱 #3】

BIツールやExcelを使ってデータの分析、可視化をするとき、または分析結果や可視化したレポートで報告を受けるとき、以下のような悩みをもつことはありませんか?
違う言葉で定義された同じ意味合いのデータ指標がたくさんあるので、どれを使って良いのか分かりづらい
同じ言葉を使ったデータ指標なのに、人や部署によって違う意味合いで使っているから混乱してしまう
本記事では、上記の悩みをLookerという製品で解消する方法について記載します。
Lookerは、Googleが提供しているデータガバナンス強化のためのデータ仮想化プラットフォームです。独自のデータモデリング言語であるLookMLを使うことで、企業全体のデータガバナンスを強化することができます。
前半ではLookerを使ったデータガバナンスの考え方を紹介し、後半で具体的なやり方を紹介します。
似たようなデータ指標が乱立するのはなぜか
データ指標が乱立する主な原因として、以下の2つがあります。
本記事では、Lookerが解決できる1に注目して解説します。
同じ単語なのに意味が違う
異なる単語なのに意味が同じ
同じ単語なのに違う意味で使われてしまう原因は、企業内の異なる部門やチームが独自の方法でデータ指標を設定するため、データ指標を算出するロジックに差が出てしまうからです。
例えば、データ利活用を促進するために全社員が自由にデータ加工やダッシュボードを作成できる環境を提供したとします。
この環境下では、売上のデータをダッシュボードで可視化する際に、一部のスタッフは返品を含む売上を計上し、別のスタッフは返品を除外した売上を計上することがありえます。
このように同じ「売上」という言葉が使われていても、計算方法に違いが生じることで、結果として異なる数値が出てしまい、組織全体としての意思決定に混乱を招くリスクがあるのです。
どうすれば防げるのか
データ指標の乱立を防ぐ主な方法としては、「新しいデータの作成を制限する」または、「データの定義と管理を全社的に一元化する」という二つが考えられます。
前者の方法は、ユーザには予め用意されたデータセットやダッシュボードだけが利用できることとし、新しいデータソースの追加を禁止してデータの統一性を保ちます。
しかしこの方法は、ビジネスの進化や市場の変化に対応しづらいといった大きなデメリットがあります。
一方、後者のデータの定義と管理を全社的に一元化する方法では、組織全体で「顧客満足度」などのデータ指標の計測方法を統一します。
一貫したガバナンスの下で導入するので、新しいデータ指標が必要になった場合には、データ指標の整合性を保ちつつ、柔軟性と適応性を確保できます。
つまり、後者の方がより良い方法であるといえます。
そしてデータの一元化を実現する最適なツールがLookerなのです。
Lookerがデータ指標の乱立を解決できる理由
Lookerはデータガバナンス強化のためのデータ仮想化プラットフォームで、データの定義と管理を一元化する機能が揃っています。
LookMLという独自のデータモデリング言語を使うことで、データの定義、計算ロジック、集約がデータモデルという形で統制でき、かつ自由にカスタマイズできる点がとても大きな強みです。
さらに、Lookerはデータの可視化やダッシュボード作成にも優れているため、一元化されたデータを効果的に活用し、組織全体でのデータ理解を深めることが可能です。
これらのLookerの強みを活かせば、データの一元化、いわゆるデータガバナンスを効果的に実現できます。
より具体的なイメージをもってもらうために、冒頭の例で挙げた「売上」という指標の定義が部署や個人によって異なる問題を、Lookerがどのように解決するか説明します。
Lookerでは、LookMLを使って「売上」という指標をコード化できます。つまり、「売上」に返品を含めるか否かを定義することができるのです。
このコード化によって出来上がるのがデータモデルです。そしてこのデータモデルを使って、全てのスタッフがデータの分析やダッシュボードを作成します。
つまり個人がバラバラにデータを集計してレポートを作るのではなく、事前に定義された指標(計算や集計の方法など)を使ってレポートを作ることで、全社員が同じ定義に基づいてデータ分析、可視化できる環境が実現できます。
とても簡易な例ですが、これがデータガバナンスが実現されている環境のイメージです。データガバナンスを効かせられるようになると、同じ単語なのに意味が違う、といったデータ指標の乱立が解消して認識齟齬を減らすことができます。
Lookerを使ってデータ指標を統制する手順
ここからは、とある小売店の売上情報をみるダッシュボードをサンプルとして、実際にLookerを使ってデータ指標を統一する方法を紹介します。
それでは、実際にLookerでデータモデルを作っていきます。
Lookerは以下のオブジェクトで構成されています。
(参考:LookMLの用語と概念|プロジェクトの各部)

Lookerでは、最初にプロジェクトを作ります。プロジェクトは、ビューやモデルを定義するための箱として機能します。
ビューは、ディメンションとメジャーというテーブルの構成要素を定義します。ディメンションはデータの個々の属性(顧客ID、購入日など)、メジャーはデータの集計方法(総売上、平均購入額など)です。
モデルは、テーブルの接続情報と、ビューを結合したExploreを定義します。ユーザはExploreに定義されたビューを使って分析を行います。
この小売店が使うダッシュボードでは、月別売上推移と、カテゴリ別売上の比較を見ることができるとします。そこでデータ指標が乱立しないように、売上、カテゴリ、受注月の3つのデータモデルをLookMLで定義します。
売上ビューの作成
最初に今回利用するテーブルを定義するため、ビューを作成します。
以下は、売上のビュー定義です。
Orders_view.view
view: orders_view {
sql_table_name: looker-private-demo.ecomm.order_items ;;
########## IDs, Foreign Keys, Counts ###########
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: inventory_item_id {
type: number
hidden: yes
sql: ${TABLE}.inventory_item_id ;;
}
measure: count {
label: "商品数"
type: count_distinct
sql: ${id} ;;
drill_fields: [detail*]
}
measure: order_count {
view_label: "売上"
label: "オーダー数"
type: count_distinct
drill_fields: [detail*]
sql: ${order_id} ;;
}
dimension: order_id {
label: "オーダーID"
type: number
sql: ${TABLE}.order_id ;;
}
dimension: sale_price {
label: "売上"
type: number
value_format_name: usd
sql: ${TABLE}.sale_price;;
}
dimension_group: created {
label: "受注"
type: time
timeframes: [hour, date, week, month, year]
sql: ${TABLE}.created_at ;;
}
measure: total_sale_price {
label: "総売上"
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
########## Sets ##########
set: detail {
fields: [created_date, sale_price]
}
}商品ビューの作成
次に、商品のビューを定義します。
Items_view.view
view: items_view {
sql_table_name: looker-private-demo.ecomm.inventory_items ;;
## DIMENSIONS ##
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: product_id {
type: number
hidden: yes
sql: ${TABLE}.product_id ;;
}
}
view: products_view {
sql_table_name: looker-private-demo.ecomm.products ;;
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: category {
label: "カテゴリ"
sql: TRIM(${TABLE}.category) ;;
drill_fields: [item_name]
}
dimension: item_name {
label: "商品名"
sql: TRIM(${TABLE}.name) ;;
}
}データモデルを定義
上記のビューをまとめて、データモデルを定義します。
今回は売上、受注月、カテゴリを集計するため、それぞれのビューを結合させた「売上、商品」というExploreを定義します。
こうすることで、ダッシュボードを作る際に各ビューの値をまとめて指定することができます。
order_dashboard_demo.model
connection: "looker-private-demo"
include: "/views/*.view.lkml"
explore: orders_model{
label: "売上、商品"
view_name: orders_view
view_label: "売上"
join: items_view {
view_label: "商品1"
#Left Join only brings in items that have been sold as order_item
type: full_outer
relationship: one_to_one
sql_on: ${items_view.id} = ${orders_view.inventory_item_id} ;;
}
join: products_view{
view_label: "商品2"
relationship: many_to_one
sql_on: ${products_view.id} = ${items_view.product_id} ;;
}
}このように、LookMLの定義によってデータモデルを作ることにより、Lookerでダッシュボードを簡単に作成できます。付録1として可視化の方法を最後に載せているので、興味がある人は読んでみてください。
また、LookMLの構文について詳しく知りたい人は、付録2の構文解説を読んでみてください。
おわりに
今回はデータ指標が乱立する問題を解消するためにLookerを活用する方法を紹介しました。
この「データ利活用の道具箱」では、データ利活用を推進したり、データをもっと活用したいと奮闘している皆さんに役立つ情報をnoteで発信しています。ぜひ他の記事もご覧ください!
ウルシステムズでは「現場で使える!コンサル道具箱」でご紹介したコンテンツにまつわる知見・経験豊富なコンサルタントが多数在籍しております。ぜひお気軽にご相談ください。
付録1:Lookerで可視化する
付録としてLookMLで定義したビューとモデルを、ダッシュボードで可視化する方法を解説します。
サンプルとして以下2種類のダッシュボードを作成します。
月次の売上推移
カテゴリ別の売上比較

月次の売上推移
このダッシュボードでは、月次の売上推移を表示します。時間の経過とともに売上がどのように変化しているかを視覚化します。
「売上、商品」のExploreを選択すると、画面左側でダッシュボードに指定可能なフィールドが表示されます。
受注月と総売上を選択して画面右上の実行を押下すると、以下のキャプチャのようにデータが集計されます。

集計したデータをダッシュボードとして保存します。

保存したダッシュボードは、以下のように表示できます。

Exploreで指定した日付の範囲を、保存後に変更することも可能です。

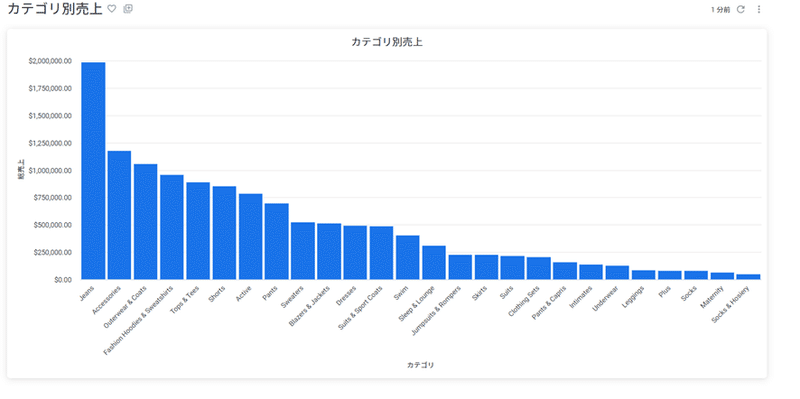
カテゴリ別売上
このダッシュボードでは、各カテゴリの売上を表示します。
どのカテゴリが最も売上を上げているのか、逆に伸び悩んでいるのかを視覚的に比較します。
先ほどと同じ「売上、商品」のExploreから、カテゴリと総売上を選択して、データを集計します。

集計したデータをダッシュボードとして保存します。

保存したダッシュボードは、以下のように表示できます。
月次売上で利用した総売上と同じデータ指標を使って、異なる集計方法のダッシュボードが作成できました。
付録2:LookMLの構文解説
付録として、今回作成したデータモデルを使ってLookMLの構文を解説します。
ビュー
ビューには、データベースのテーブル名を指定します。BigQueryのテーブル名をsql_table_nameに指定することで、LookMLで参照可能になります。
view: orders_view {
sql_table_name: looker-private-demo.ecomm.order_items ;;上記ビューの定義でテーブルを指定し、ディメンションとメジャーでカラムを指定していきます。
ディメンション
typeとsqlを指定することで、一つのカラムを表現します。
sqlに記載されている${TABLE}が上記ビューで指定したテーブルと対応しており、テーブルのカラムを指定することでディメンションを定義します。
dimension: sale_price {
label: "売上"
type: number
value_format_name: usd
sql: ${TABLE}.sale_price;;
}
dimension: category {
label: "カテゴリ"
sql: TRIM(${TABLE}.category) ;;
drill_fields: [item_name]
}ディメンショングループ
時間や期間のディメンションを、特定の単位でまとめて定義できます。
今回の例では、受注日時のOrder Dateに対して、時間単位(hour)、日付単位(date)、週単位(week)、月単位(month)、年単位(year)で集計可能としています。
dimension_group: created {
label: "受注"
type: time
timeframes: [hour, date, week, month, year]
sql: ${TABLE}.created_at ;;
}メジャー
ディメンションに対する計算結果をカラムとして定義できます。COUNT、SUM、MIN、MAXなどが定義できます。
今回は総売上を集計するため、typeをsumにして売上の合計値を集計したtotal_sale_priceを定義しました。
measure: total_sale_price {
label: "総売上"
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]