
LoRAを作ってみよう!~実践編・基本~

はじめに
体調不良もあり、長らく更新しておらず申し訳ございませんでした。
前回は、LoRAについて基礎的なところを記事にしました。
今回は、その実践編になります。
本記事のお品書きとしては、前準備~基本的なLoRA学習までを取り扱おうと思います。
Contents
前準備(1)~コンセプトを決めよう~
前準備(2)~教師画像を集めよう~
前準備(3)~フォルダとファイルの下準備をしよう~
前準備(4)~学習に必要な各種ツールを導入しよう~
前準備(5)~キャプション付けを行おう~
前準備(6)~学習パラメータを決定しよう~
実践(1)~学習開始~
実践(2)~実際に生成してみる~
前準備 (1) ~コンセプトを決めよう~
LoRAを作るぞー!!ってなっても、コンセプトが決まらなければ、データセットも用意することができません。
LoRAで出来ることは、基本的に「既知の情報に関連した新しい概念を追加する」ことだけなので、既に概念として持っている情報を打ち消す(既知の概念と真逆の概念の様)ような学習をさせることはできません。※1
※1
ESD(Erasing Concepts from Diffusion Models)と呼ばれる技術をLoRA学習に取り入れると、特定の既知の概念を削除するようなことが可能になります。
この手法はLECOと呼ばれますが、ここではLoRA学習の基本的なお話なので一旦置いておきます。
なので、特定のキャラクター・物体・建築物・衣装などに特化し学習したLoRAが、基本的な使い方になります。
今回は、私のイメージキャラクターでもある「おからちゃん」のキャラクターLoRAを作ってみようと思います。

前準備 (2) ~教師画像を集めよう~
LoRAは、Checkpointのファインチューニングよりも少ない量のデータで学習が可能です。
とはいえ、多ければその分精度が上がりますが、逆に多すぎて適正なステップ数にしないとオーバーフィッティングになる可能性があります。
キャラクターLoRAで使用される教師画像は、「最低20枚」ほどあれば形になると思います。
今回は20枚でやってみようと思います。
但し、学習させたいキャラクターであれば、どの画像でもいい!というわけではありません。
LoRAの精度を上げるために、以下を参考に画像を集めるようにしてください。
教師画像に採用する画像
1. 必要情報以外のノイズを取り去った画像
今回はキャラクターLoRAということで、背景の情報は不要になります。
教師画像に選定するものは個人差がありますが、私は必要情報以外のノイズが入らないように背景が真っ白もしくは透過画像を使用するようにしています。
キャラクターLoRAを作る際は、拡張機能のRembgなどを使用して、背景削除しておきましょう。
2. ピンボケやジャギーなどが除去された高品質な画像
低品質な画像だと、その画像ノイズやブラーなども含んで学習してしまいます。
その場合、想定した出力が出来ない場合があるので、出来るだけ高品質な画像にしましょう。
3. 解像度は1024x1024以下の画像
解像度が大きければ大きいほど、使用するメモリ量が増え、さらに学習時間が膨大になります。
その為、大きくても1024x1024までの画像にしましょう。
4. 画像解像度を一定にする(任意)
画像解像度は一定にする必要は必須事項ではありませんが、学習の際にMax Resolutionを指定する項目がある為、高品質な状態で学習を均一化する為に行っています。
効果があるかは不明なので、任意です。
5. 様々な表情の画像を入れる(任意)
表情の変化を学習させることができれば、精度が上がりますが、既に喜怒哀楽の表情の概念はCheckpointモデルに存在している場合が多いので必須ではありません。
汎用的な表情であれば、イラストベースのLoRAである場合は不要ですが、フォトベースの場合は個人個人の表情の癖などがある為、状況を見て教師画像として入れるようにします。
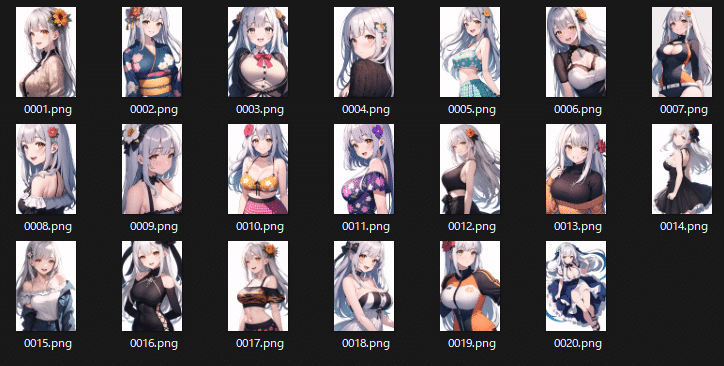
出来上がった教師画像群がこちら。

前準備 (3) ~フォルダとファイルの下準備をしよう~
モデル学習作業において、フォルダ名を好きな名前にする、という訳にはいきません。
フォルダ名はある程度のルールに則って命名する必要があります。
フォルダ名は、以下のルールに則ってつける必要があります。
[繰返し回数]_[トリガーワード]
フォルダ名では、学習の繰返し回数(どの程度画像を反復学習させるか)を設定し、どの文字列をトリガーにするかを設定します。
今回はこのようにしました。
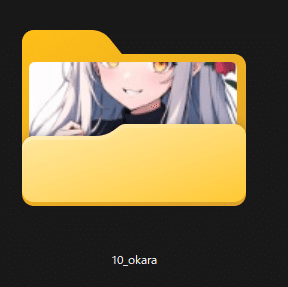
Trigger Word : okara
続いてファイル名です。
特にルールはありませんが、連番にすることで読み込む順番が明示化されていいと思います。
[連番].png
[連番].jpg
など
連番にする意味としては、画像の学習順序などを変更する際に、明示化されていると対処しやすいなどの理由がある為で、連番にしないからといって特に不都合が発生するわけではありません。
LoRA学習くらいの枚数であれば、連番は必要ないと思いますが、一応連番にしておきましょう。
ファイル名を連番にするの面倒!!
という方は、連番にするスクリプト作ったので、使ってください。
import os
# 連番にする対象のフォルダを記載
targetdir = input('Enter target folder: ')
def ChangeSNFile(targetdir):
# フォルダ内の全画像をピックアップ(.png/.jpg/.jpegのみ対象)
files = [f for f in os.listdir(targetdir) if f.endswith('.png')]
targetpic=files
files = [f for f in os.listdir(targetdir) if f.endswith('.jpg')]
targetpic=targetpic+files
files = [f for f in os.listdir(targetdir) if f.endswith('.jpeg')]
targetpic=targetpic+files
print(targetpic)
# ファイル名を連番に変更
for i, file in enumerate(targetpic):
if ".png" in file:
# PNG画像の連番フォーマット
SN = f"{i+1:04}.png"
elif ".jpg" in file:
# jpg画像の連番フォーマット
SN = f"{i+1:04}.jpg"
elif ".jpeg" in file:
# jpeg画像の連番フォーマット
SN = f"{i+1:04}.jpeg"
# 連番付与実行
os.rename(os.path.join(targetdir, file), os.path.join(targetdir, SN))
print("\n")
if __name__ == '__main__':
#Function実行
ChangeSNFile(targetdir)
#Rename後取得
files = [f for f in os.listdir(targetdir) if f.endswith('.png')]
targetpic=files
files = [f for f in os.listdir(targetdir) if f.endswith('.jpg')]
targetpic=targetpic+files
files = [f for f in os.listdir(targetdir) if f.endswith('.jpeg')]
targetpic=targetpic+files
print(targetpic)
print("\n")
print("Rename done.")↓
無論、手作業で連番にしてもいいですが、枚数が膨大になると果てしなく面倒なので、スクリプトやバッチファイルを活用していきましょう。
前準備 (4) ~学習に必要な各種ツールを導入しよう~
今回使用するツールは以下になります。
Kohya's GUI
Kohya氏が製作したsd-scriptを、GUIで操作できるようにbmaltais氏がGradioで開発した神サードパーティツールです。
これを使って、LoRA学習を実行します。
任意の場所に上記のツールを、以下コマンドでダウンロードしてください。
git clone https://github.com/bmaltais/kohya_ss.gitStability Matrixを使用している方は、既にパッケージ選択ができるようになっていますので、そちらから導入してください。

WD1.4 Tagger
この拡張機能は、Deepdanbooru interrogate機能のように、画像からキャプションを推察して、キャプション付けを自動で行ってくれる神拡張機能です。
これを使って、今回の教師画像にキャプションをつけていきます。
Dataset Tag Editor
データセットのキャプションを手直しする為の拡張機能です。
WD1.4 Taggerで想定していないキャプションが自動で付いてしまった際に、データセットのキャプションを手直しする為に使用します。
WD1.4 Taggerを使用せずに、この拡張機能で全て自分でキャプション付けを行うことも可能です。
面倒なので、ある程度はWD1.4 Taggerで付けてもらったほうがいいと思います…
前準備(5)~キャプション付けを行おう~
ついにここまで来ました。
ここからはデータセット作りです。
教師画像はあくまでも画像なので、キャプションが付いていない場合もあります。
画像+キャプションをつけることで、学習ツールへ読み込ませるデータセットとなります。
WD1.4 Taggerでキャプション付けを行う
まずは、WD1.4 Taggerでキャプション付けを行いましょう。
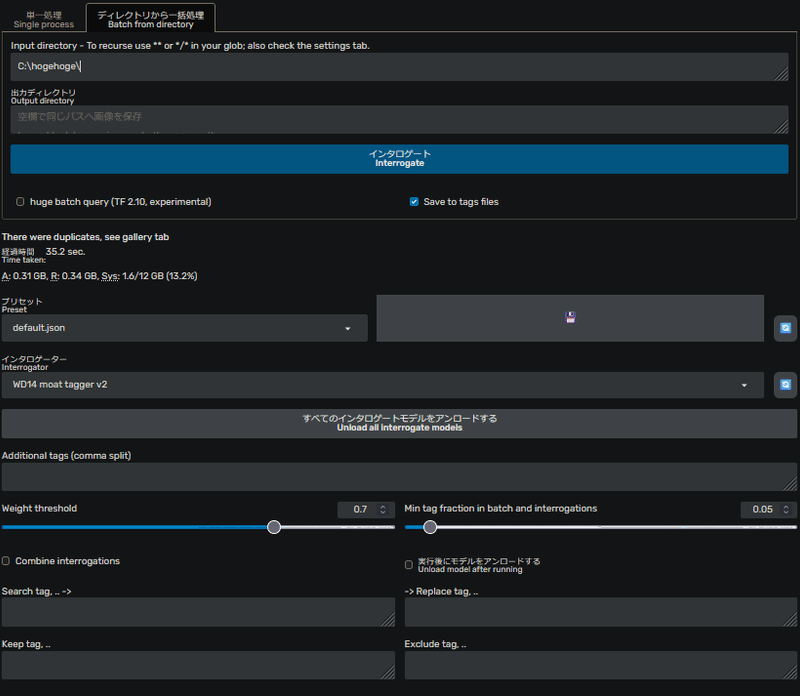
ディレクトリから一括処理(Batch from directory)で一括処理を選択します。
学習用のデータが入ったフォルダは既に準備してあるので、出力ディレクトリは空欄でOKです。
Interrogatorは複数ありますが、今回は一番新しめのWD1.4 moat tagger v2を使っていきます。
Weight thresholdはキャプションの合致率の閾値で、キャプション付けに反映する確信度を設定します。
今回は「0.7」で設定しています。
キャラクターなどの人物像を学習するときは、Weight thresholdを大きめに取ることで、自動タグの付与数を制限し、キャプションの手直し割合を軽減させることができます。
逆に衣装などを学習するときは、Weight thresholdを小さめに取る必要があります。
これは、衣装などの確信度が高くならない場合があり、大きめに取ってしまうと、自動タグから除外されてしまう可能性があるためです。
それでは実行してみましょう。

実行すると上記のようなTagの確信度が表示されます。
併せて、先ほどの学習用フォルダにテキストファイルが生成されています。
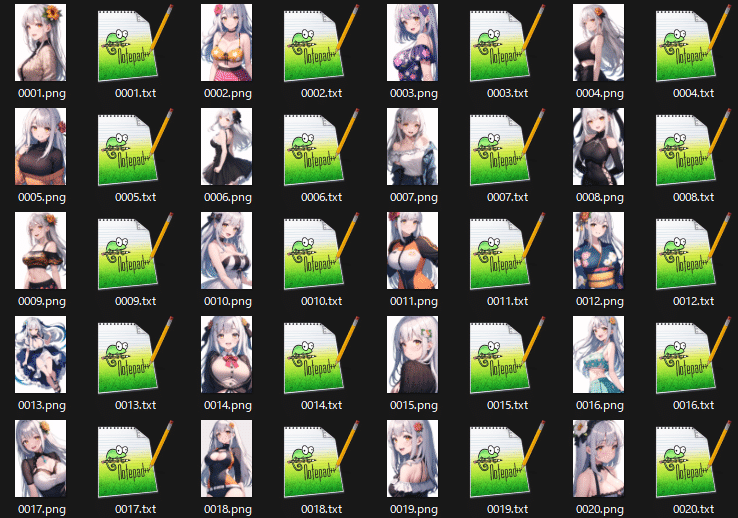
キャプションの自動付与が完了しました。
Dataset Tag Editorで手直しをする
続いて、キャプションの手直しをしていきますが、膨大な量のデータがある場合は、目視確認が非常に厳しいので、手直しせずにTaggerのみで進める方もいます。
プロンプトの感度を高精度にする為には、手直しが有効だと思いますが、面倒な方は手直しの工程は飛ばして頂いても構いません。
では進めていきます。

学習用フォルダを記述し、読み込みを行うと以下のようになります。

ここからは、キャプションの編集を行っていきます。
UI上の右側が編集画面になります。
選択した画像のキャプションを編集(Edit Caption of Selected image)を選択し、画像1つずつ目視で確認していきます。
選択すると以下のような画面になります。

いくつか重複している、もしくは不要なキャプションがあるので、修正していきます。
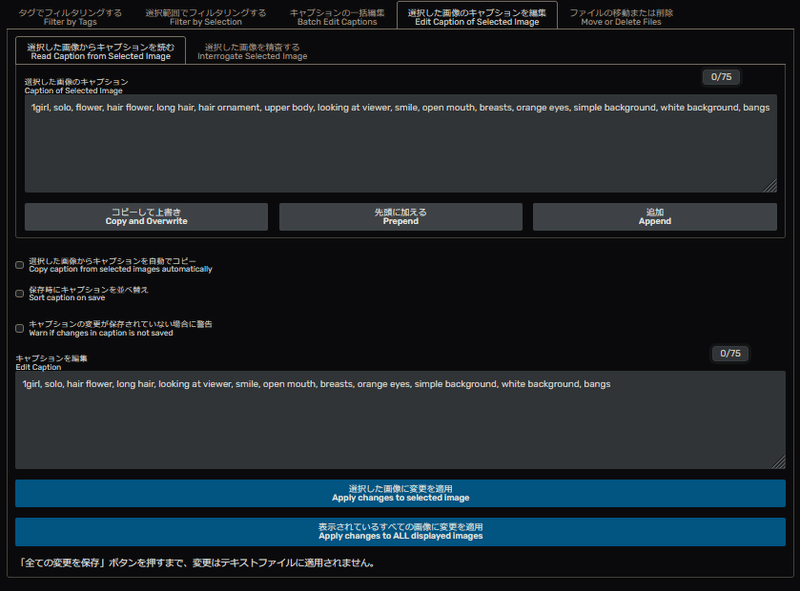
今回は、キャラクターの外見のみをコンセプトにLoRAを作ろうとしているので、衣装類のキャプションは取り除いています。
仮に、キャラクター+衣装が固定である場合は、そのキャプションも記入するようにしてください。
この工程を全ての画像で行っていきます。
キャプションを全て変更し終えたら、「表示されているすべての画像に変更を適用(Apply changes to ALL displayed images)」を実行してください。

これにてキャプション付け及び手直しは完了です。
前準備(6)~学習パラメータを決定しよう~
学習パラメータは多岐に渡って、いろんな項目があります。
すべて設定しないといけない!という訳ではなく、用途や目的に応じて変更していくのが好ましいです。
今回は、LoRA学習に必要最低限な項目のみを設定していきます。
モデルの出力に関する設定を決める
最初に一番イメージしやすいところから決めていきましょう。
学習完了後に出力されるモデルの名前、モデルタイプ、精度設定を決めていきます。
今回は、名前は「okara」、モデルタイプは「safetensors」、精度設定は「fp16」にします。
モデルタイプと精度設定は馴染みがある項目ですので、設定しやすいですね。
LoRA Typeの決定
LoRA Typeとは、LoRAやLoHA、LyCORISなど様々な形態の中から、どのモデルにするかを設定する項目です。
今回は、通常のLoRAですので、Standardを選択します。
ステップ数の決定
さて、いよいよ中枢に取り掛かっていきます。
LoRA学習におけるパラメータとしては、ステップ数の目安は5000~8000くらいが丁度いいと思います。
ステップ数とは前回の基礎編でも取り扱いましたね。
$$
step=imgs×repeat×epoch
$$
ここから逆算します。
今回はステップ数7000を目安に繰返し回数とエポックを決めていきます。
以下が条件です。
学習枚数:20枚
繰返し回数:10回
エポック:n回
ステップ数:7000回
上記式に当てはめて、エポック数を割り出します。
$$
7000=20\cdot10\cdot n\\
7000=200n\\
n=7000/200\\
n=35
$$
ということで、エポックは35epochとなりました。
学習枚数:20枚
繰返し回数:10回
エポック:35回
ステップ数:7000回
学習に用いるベースモデルの決定
続いて、学習に用いるベースモデルを選びます。
これはこれから作るLoRAのイメージに合うものを選びます。
今回は、私がリリースしているLastpieceCore A0692を選択します。
LRスケジューラとオプティマイザの決定
続いて、学習の使用するLRスケジューラとオプティマイザを決めます。
LRスケジューラとオプティマイザについては基礎編でも書いていますので、そちらを参照ください。
ここは好き嫌いが分かれるところですが、私はよく「Adafactor」を使用しています。
学習率に関わる設定というのは沼りやすい項目です。
その中でも、Adafactorは比較的オーバーフィッティングしにくく、特に悩まずともLoRAとして大体形になる印象があります。(個人的な感想です)
但し、学習効率が比較的緩やかな印象があるので、学習不足なものが出来上がったりすることが、しばしばあります。
なので、Adafactorを使うときはステップ数を少し多めに取るといいと思います。
その為、今回はステップ数を7000と比較的多めにしています。
LRスケジューラをAdafactorにすると、オプティマイザも必然的にAdafactorにする必要があります。
LRスケジューラをAdafactorにして、他のオプティマイザに設定するとエラーを吐きますのでご注意ください。

学習率の決定
続いて、Learning rate(学習率)を決めていきます。
デフォルトでは1e-4(0.0001)となります。
ここは、これだ!というものを学習前に算出するのが難しく、LRスケジューラとオプティマイザの設定次第では学習率が変動して、思った学習率で学習が進まないことがあります。
学習率を固定したい場合は、LRスケジューラをConstantにしますが、その分扱いが難しいのでここでは割愛します。
実際に学習してみて、出来栄えを確認しつつ、学習率を変更するようにしましょう。
学習率の項目は3項目ありますが、今回設定するの項目は「Learning rate」です。
他に「Text Encoder learning rate」と「Unet learning rate」という項目がありますが、そちらはText EncoderとU-Net、それぞれの学習率設定になります。
Learning rateの項目は包括的(Text Encoder learning rateとUnet learning rateを同一の学習率で学習を進める)為の設定です。
同一の学習率で各々進めていきますので、Learning Rateのみ設定とし、デフォルト値(1e-4)のまま進めていきます。
Max Resolutionの決定
Max Resolutionとは、学習に用いる際の最大解像度のことです。
これは、用意した教師画像や正則化画像と照らし合わせて設定してください。
今回は600x900の画像なので、「600,900」とします。
Network Rank(Dimension)の決定
続いて、Network Rank(Dimension)とNetwork Alphaを決めていきます。
Network Rank(Dimension)は、ニューラルネットワーク内の中間層の次元数を設定するもので、この数が多いければ、学習情報の保持格納量も多いと思って頂いてOKです。
学習枚数が20枚程度であれば、Dim:16くらいでも問題ない(多いくらい)と思います。
Network Alphaの決定
Network Alphaとは、ニューラルネットワークのWeightを決定する項目です。
Alpha値が小さければ、その分Weightが強くなります。
この項目は基本的にアンダーフローを防ぐ項目です。
モデル学習におけるアンダーフローとは、演算ミスによる不都合のことを指します。
この値を小さくすると、元画像との忠実さが低減し、大きくすると元画像との忠実さが向上する半面、描写崩壊が起きやすくなる印象があります。
今回は、Alpha値は「1」で行っていこうと思います。
パラメータまとめ
では、ここまでの主要なパラメータの内容を纏めてみます。
Output LoRA : okara
Model type : safetensors
Precision : fp16
Base model : LastpieceCore A0692.safetensors
LoRA Type : Standard
Images : 20
Repeat : 10
Epoch : 35
(Max train step : 7000)
LR scheduler : adafactor
Optimizer : Adafactor
Learning rate : 1e-4 (0.0001)
Max Resolution : 600,900
Network Rank (Dim) : 16
Network Alpha : 1
今回設定したjsonファイルも添付しておきます。
※Kohya's GUIで使用できるjsonファイルです。tomlファイルではないので、ご注意ください。
{
"LoRA_type": "Standard",
"LyCORIS_preset": "full",
"adaptive_noise_scale": 0,
"additional_parameters": "",
"async_upload": false,
"block_alphas": "",
"block_dims": "",
"block_lr_zero_threshold": "",
"bucket_no_upscale": true,
"bucket_reso_steps": 64,
"bypass_mode": false,
"cache_latents": true,
"cache_latents_to_disk": false,
"caption_dropout_every_n_epochs": 0,
"caption_dropout_rate": 0,
"caption_extension": ".txt",
"clip_skip": 1,
"color_aug": false,
"constrain": 0,
"conv_alpha": 1,
"conv_block_alphas": "",
"conv_block_dims": "",
"conv_dim": 1,
"dataset_config": "",
"debiased_estimation_loss": false,
"decompose_both": false,
"dim_from_weights": false,
"dora_wd": false,
"down_lr_weight": "",
"dynamo_backend": "no",
"dynamo_mode": "default",
"dynamo_use_dynamic": false,
"dynamo_use_fullgraph": false,
"enable_bucket": false,
"epoch": 35,
"extra_accelerate_launch_args": "",
"factor": -1,
"flip_aug": false,
"fp8_base": false,
"full_bf16": false,
"full_fp16": false,
"gpu_ids": "",
"gradient_accumulation_steps": 1,
"gradient_checkpointing": false,
"huber_c": 0.1,
"huber_schedule": "snr",
"huggingface_path_in_repo": "",
"huggingface_repo_id": "",
"huggingface_repo_type": "",
"huggingface_repo_visibility": "",
"huggingface_token": "",
"ip_noise_gamma": 0,
"ip_noise_gamma_random_strength": false,
"keep_tokens": 0,
"learning_rate": 0.0001,
"log_tracker_config": "",
"log_tracker_name": "",
"log_with": "",
"logging_dir": "",
"loss_type": "l2",
"lr_scheduler": "adafactor",
"lr_scheduler_args": "",
"lr_scheduler_num_cycles": 1,
"lr_scheduler_power": 1,
"lr_warmup": 0,
"main_process_port": 0,
"masked_loss": false,
"max_bucket_reso": 2048,
"max_data_loader_n_workers": 0,
"max_grad_norm": 1,
"max_resolution": "600,900",
"max_timestep": 1000,
"max_token_length": 75,
"max_train_epochs": 0,
"max_train_steps": 0,
"mem_eff_attn": false,
"metadata_author": "",
"metadata_description": "",
"metadata_license": "",
"metadata_tags": "",
"metadata_title": "",
"mid_lr_weight": "",
"min_bucket_reso": 256,
"min_snr_gamma": 0,
"min_timestep": 0,
"mixed_precision": "fp16",
"model_list": "custom",
"module_dropout": 0,
"multi_gpu": false,
"multires_noise_discount": 0,
"multires_noise_iterations": 0,
"network_alpha": 1,
"network_dim": 16,
"network_dropout": 0,
"network_weights": "",
"noise_offset": 0,
"noise_offset_random_strength": false,
"noise_offset_type": "Original",
"num_cpu_threads_per_process": 2,
"num_machines": 1,
"num_processes": 1,
"optimizer": "Adafactor",
"optimizer_args": "",
"output_dir": "G:\\Tools\\Python\\venv\\StabilityMatrix\\training\\LoRA\\output",
"output_name": "okara",
"persistent_data_loader_workers": false,
"pretrained_model_name_or_path": "G:/Tools/Python/venv/StabilityMatrix/Data/Models/StableDiffusion/LastpieceCore/LastpieceCore_A0692.fp16.safetensors",
"prior_loss_weight": 1,
"random_crop": false,
"rank_dropout": 0,
"rank_dropout_scale": false,
"reg_data_dir": "",
"rescaled": false,
"resume": "",
"resume_from_huggingface": "",
"sample_every_n_epochs": 0,
"sample_every_n_steps": 0,
"sample_prompts": "",
"sample_sampler": "euler_a",
"save_as_bool": false,
"save_every_n_epochs": 0,
"save_every_n_steps": 1000,
"save_last_n_steps": 0,
"save_last_n_steps_state": 0,
"save_model_as": "safetensors",
"save_precision": "fp16",
"save_state": false,
"save_state_on_train_end": false,
"save_state_to_huggingface": false,
"scale_v_pred_loss_like_noise_pred": false,
"scale_weight_norms": 0,
"sdxl": false,
"sdxl_cache_text_encoder_outputs": false,
"sdxl_no_half_vae": true,
"seed": 0,
"shuffle_caption": false,
"stop_text_encoder_training": 0,
"text_encoder_lr": 0,
"train_batch_size": 1,
"train_data_dir": "G:/Tools/Python/venv/StabilityMatrix/training/LoRA/training img",
"train_norm": false,
"train_on_input": true,
"training_comment": "",
"unet_lr": 0,
"unit": 1,
"up_lr_weight": "",
"use_cp": false,
"use_scalar": false,
"use_tucker": false,
"v2": false,
"v_parameterization": false,
"v_pred_like_loss": 0,
"vae": "",
"vae_batch_size": 0,
"wandb_api_key": "",
"wandb_run_name": "",
"weighted_captions": false,
"xformers": "xformers"
}実践(1)~学習開始~
では、ついに学習していきましょう!
まずは、任意の場所にデータセット用の作業フォルダ(データセット格納フォルダ)を作成します。

今回は、training imgフォルダとしました。
ここに、データセットフォルダを入れます。(今回では10_okaraフォルダごと入れます)
では、続いてKohya's GUIを起動します。
Kohya’s GUIを起動したら、LoRAタブをクリックしてください。

前項で決定したパラメータを入力していきます。(またはConfigurationから読み込んでもOKです)
まずは、Model設定です。

Pretrained model name or pathに学習のベースとなるモデルを、
Image folderに先ほど作成したデータセット用の作業フォルダを、
Trained Model output nameに出力するモデル名を入力します。
Image folderはデータセットフォルダ自体を指定してはいけないので、ご注意ください。
Image folderは必ず、
~/[ データセット格納フォルダ ] / [n_データセットフォルダ]
とする必要があります。
続いてParameterです。
出力先を決めましょう。

ここに学習されたLoRAが保存されます。
次に「Save every N Epoch」という設定がありますが、こちらは何Epoch毎にLoRAを保存するかという設定です。
今回はこちらは設定しません。
また、キャプションファイルを指定する必要があるので、忘れずに「Caption file extension」を「.txt」に設定しましょう。


「Save every N Epoch」という設定をしない代わりに、「Save every N steps」という設定を行います。
この設定は、Advanced内にあります。

今回は7000Stepsですので、1000Steps毎にモデルを出力するよう設定しておきます。
(モデルの学習度合いの変遷を確認する為です)
では、学習を実行しましょう。
「Start training」を押下します。

学習が完了するまで、暫く時間がかかります。
完了するまで、しばし待ちましょう。
(今回の例だと、GeForce RTX3080Tiで学習完了まで大体1時間~1時間半ほど掛かります)

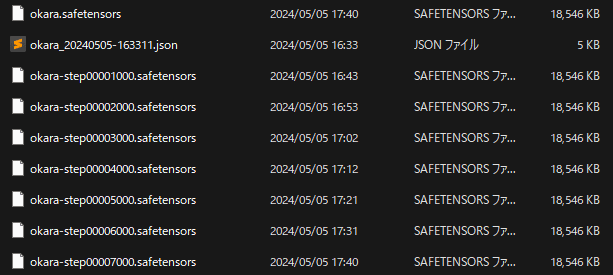
無事に完成しました。
実践(2)~実際に生成してみる~
では、実際に作ったLoRAを使って生成してみましょう!
出来上がったLoRAを所定のフォルダに入れて、実際に各強度別に生成してみます。
使うプロンプトは次の通りです。
okara,kawaii,cute,(1 girl,solo),arms behind back,[smile,open mouth],close view,from adove,looking to the side,
((Ruffled off-the-shoulder top and denim cutoff skirt):1.1),large breast,
BREAK
((white background,day):1.2),
<lora:okara:n>敢えて、髪色や目の色は指定していません。
okaraというトリガーワードのみで、どこまで教師画像の特徴を捉えられるか試してみます。


LoRA強度が「0.5」を境に、教師画像の特徴が出てきています。
特にノイズが入ったり、色合いの破綻などはありません。
安定して出力できるか、バッチ回数を上げて出力してみます。

バッチ回数:9回
目の色は特徴を捉えていますが、髪の色は精度が落ちるようです。
もう少し強度を上げてみます。
次は、LoRA強度を0.75にして出力してみます。

バッチ回数:9回
まだ完璧ではありませんが、大分特徴を捉えてきましたね!
ただ、思ったよりも強度を上げないとダメなので、ステップ数をもう少し上げても良かったかもしれません。
LoRA学習の失敗例
ここからは余談です。
LoRA学習に失敗するとどのようになるのか、見ていきましょう。
生成プロンプトは先ほどと同様です。
では、わざとオーバーフィッティングするようにパラメータを変えて、LoRAを学習していきます。
学習パラメータは以下です。
LoRA Type : Standard
Images : 1
Repeat : 1
Epoch : 20000
(Max train step : 20000)
LR scheduler : Constant
Optimizer : AdamW8bit
Learning rate : 1e-6 (0.000001)
Max Resolution : 600,900
Network Rank (Dim) : 16
Network Alpha : 1

完全にオーバーフィッティングが進み切ると、ノイズ画像になります。
または、人物の輪郭が溶けたり、ガビガビになったりします。
続いて、アンダーフィッティング状態を見てみましょう。
学習パラメータは以下です。
LoRA Type : Standard
Images : 1
Repeat : 1
Epoch : 5
(Max train step : 5)
LR scheduler : Constant
Optimizer : AdamW8bit
Learning rate : 1e-2 (0.01)
Max Resolution : 600,900
Network Rank (Dim) : 16
Network Alpha : 1

おや、なんか綺麗に出てる…?と思う方もいると思いますが、強度をかなり強く入れても、全くLoRAが効いておらず、教師画像の特徴がほぼ皆無です。
このことから、適正な学習パラメータが必要なことがわかります。
おわりに
今回はLoRA学習の実践編・基本をお伝えしました!
かなりのボリュームになってしまいましたね!
分かりやすく伝えようとしましたが、やはりモデルの学習はどうしても簡略化できない部分が多く、難しいなーと思いました。
是非、皆さんもLoRA学習をやってみて、うちの子LoRAを作ってみましょう!
次回は、応用編を予定しています。
ここから先は
よろしければサポートお願いします!✨ 頂いたサポート費用は活動費(電気代や設備費用)に使わさせて頂きます!✨