Pythonでやってみた13:各社の平均年収のデータ取得

1.概要
本記事ではEDINETの有価証券報告書から平均年収を抽出して、比較・可視化しました。
1-1.背景
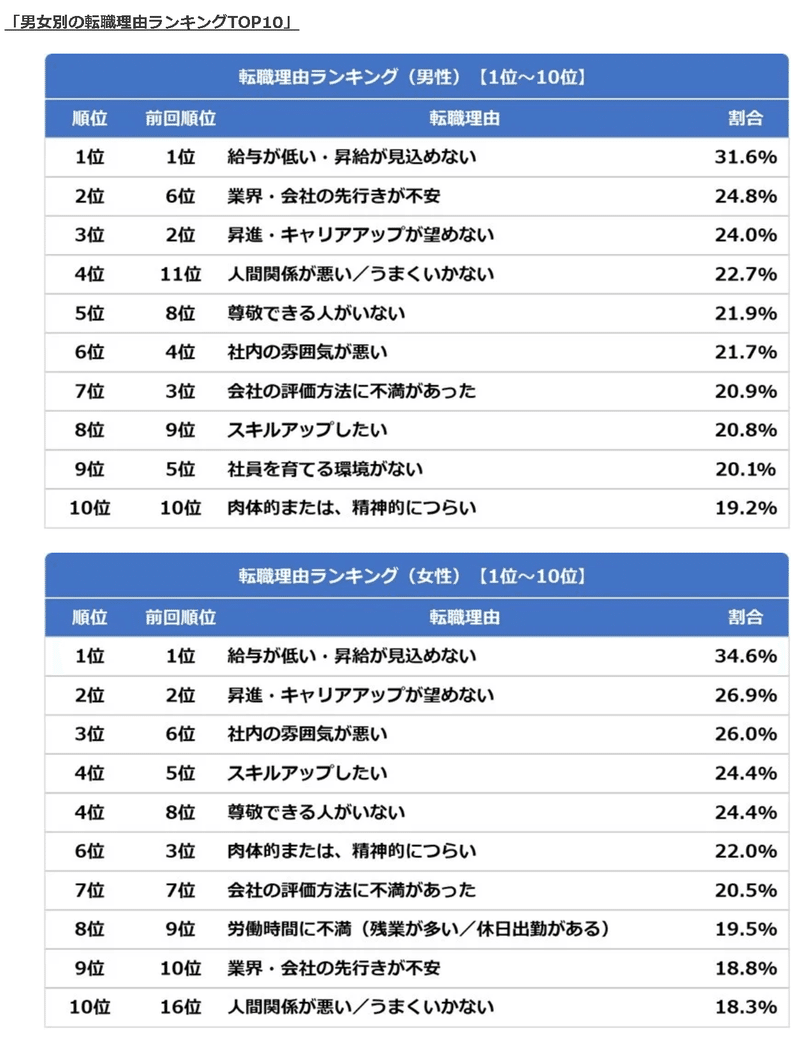
日本において転職活動が隆盛を極めるなか、転職理由の上位として「年収」があります。
年収を理由に転職しても会社と転職者では情報格差があるため、提示年収が高くても下記のような理由で年収が上がらない・下がる可能性もあります。
提示された数値(ボーナスの月数・想定残業時間など)が適当
定時年収を25h残業で計算しているが、実際は経費削減のため残業0hでないといけない
ボーナスを前々月の高い数値を出しておき、今年は1か月分低い(入社して数日後の労組の話で認知)
会社都合で残業時間を規制
15分単位で残業時間をカットする
お金に関する福利厚生がない
前の会社より食堂・売店の価格が高く出費が多くなる
経費を削減しており自費出費が発生(そういう風に誘導している)
会社がある場所の土地代やユーティリティ代が高い
提示年収も重要ですが「平均年収が高い会社=まともな会社」という前提のもと、平均年収を誰でも簡単に調べることが出来る必要があります。提示年収と平均年収がかけ離れている場合はその理由も転職時に確認すべきだと思います。
1-2.EDINET
EDINETは「金融商品取引法に基づく有価証券報告書等の開示書類に関する電子開示システム」のことで、有価証券報告書、有価証券届出書、大量保有報告書等の開示書類について、その提出から公衆縦覧等に至るまでの一連の手続きを電子化するために開発されたシステムです。
1-3.EDINET API
EDINET API はプログラムを介してEDINET のデータベースから効率的にデータを取得できるAPIです。
仕様は下記の通りであり柔軟性があまりないため、仕様に合わせたシステムを作成します。
エンドポイントにHTTPクライアントのGETメソッドを使用。dateの情報は必須
データは提出日付(date)における指定図書の一覧を取得する。よって、各社の情報や図書(有価証券報告書など)ごとの抽出はできない(と思う)
データはXBRL ファイル(Zip?)またはPDFで取得:JSON形式のデータは無し

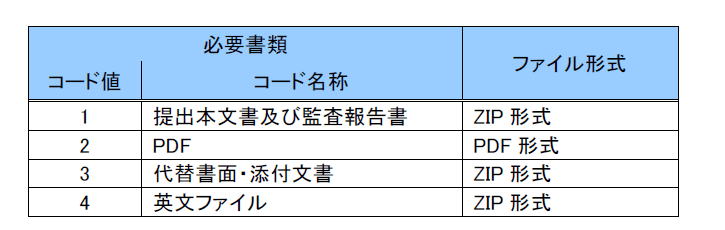
1-4.有価証券報告書/平均年収
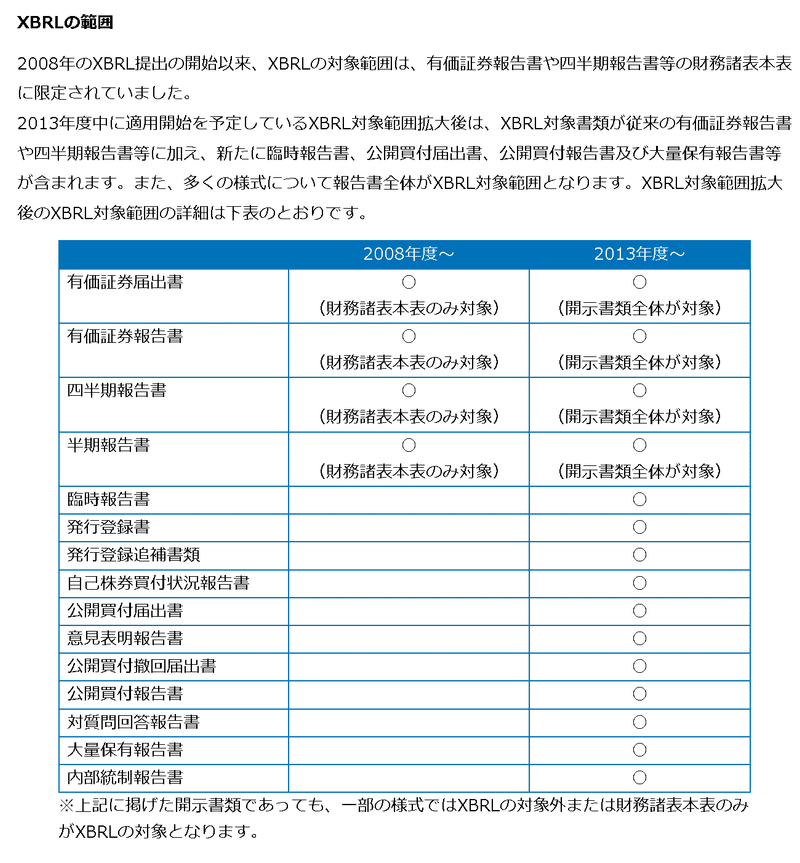
平均年収は有価証券報告書に記載されております。EDINETのページから下記手順で数値を確認できます。今回はこれを自動化します。
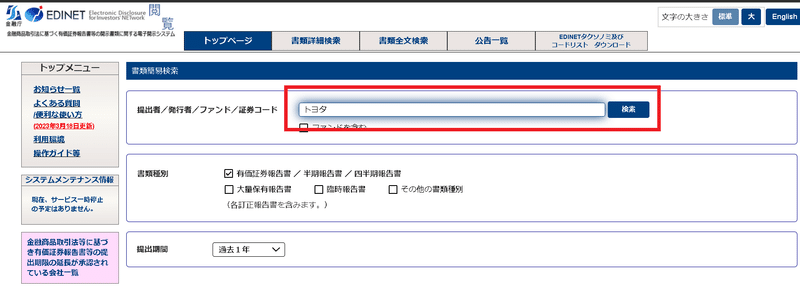
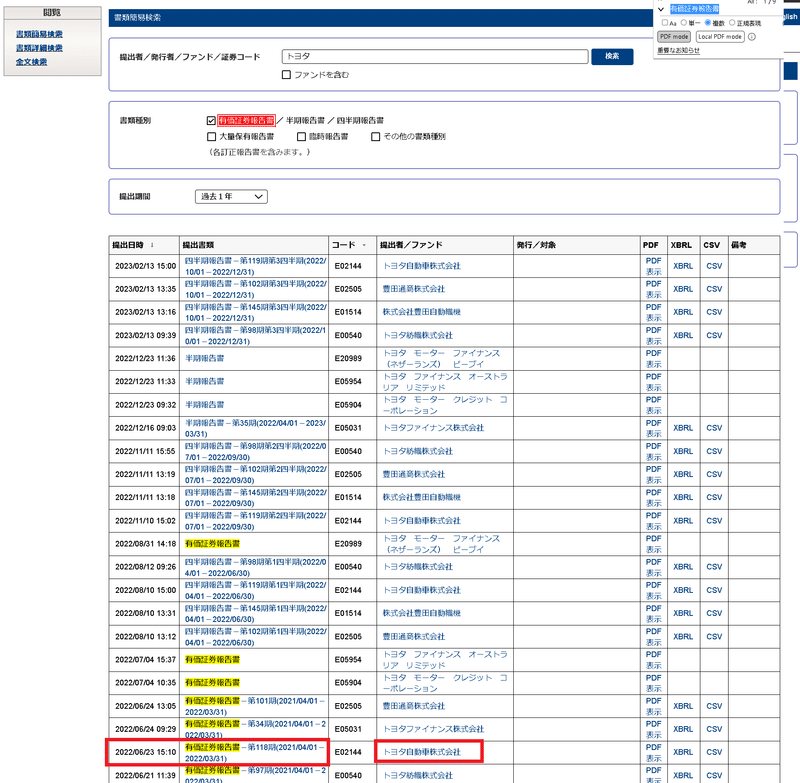
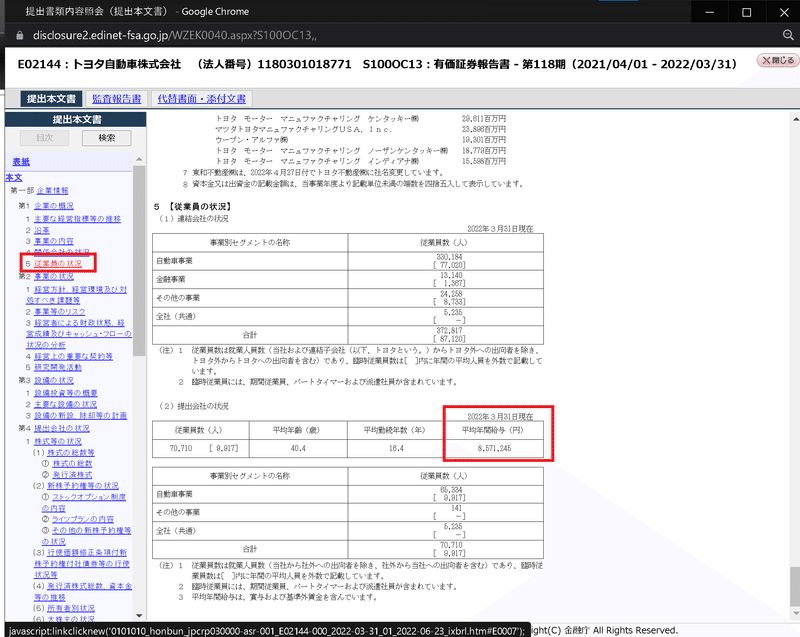
EDINET関して2013年度以降からのデータは揃っているとのことです。
2.コードの設計思想
コードの設計思想は下記の通りです。参考までに、途中でエラーが出たため初期設計ではなく完成後の設計思想となります。
(※一部の処理はうまくいかなかったため後処理追加をしておりますので、コード自体はきれいではありません。)
処理したい日付を連番で作成
EDINET-APIはdateからしか指定できないため日付でスクリーニング
最終日は本日の日付で自動化
EDINET-APIで指定した日付の書類データ一覧取得
空で抽出させる可能性もあるためtry文
データはJSON形式で'results'内にあるためDataFrameに変更
取得したデータから検索したい会社を検索(データはリストで渡す)
会社名を完全一致させるのは手間のためキーワードで抽出
前章の通り複数検索させる可能性もあるためリストを作成時はなるべく広めに書く(人間が頑張る)
会社データを抽出(get_Companydata)
有価証券報告書の記載があるデータのみ抽出(訂正有価証券報告書も存在するが後で除去※多分ここで処理する方が効率的)
得られたデータから['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription']のみ抽出(書類ID, Code番号、会社名、提出日、書類詳細)
EDINET-APIで指定書類IDのPDFデータ取得(getPDF_EDINETAPI)
「サーバーに負荷をかけないようtime.sleep()」で待機時間を設定
エンドポイントに「docID」が必要なためデータから抽出して結合
PDFで保存するためtype:2をパラメータに渡す
PDF保存のためのファイル名を指定(提出日と会社名を利用)
APIでデータ取得後にファイルへ出力
PDFから平均年収情報をOCRで抽出(get_wageAvg):★律速工程
データがテーブル形式なのでPDF-OCRのtabula-pyを使用
有価証券報告書の平均年収が円と千円単位があるため”平均年間給与”を元にデータ抽出
tabula-pyだとカラム(平均年間給与)が1行目のデータに入り込むことがあるため1行目に”平均年間給与”がある場合の処理も追加
抽出した平均年収のDataFrameから値を抽出(extract_wage_value)
全て同じ形のDataFrameで抽出できたらpd.concat()でよかったが、tabula-pyの性能?でたまにずれるので直接結合できなかった
”平均年間給与”の値はカンマ付き文字列であり、かつ円の有無、千の有無があるため前処理をして円単位の整数で抽出
データをSQLのDBに保存(insertData_toSQL)
抽出するカラム数を決めているため先に初期化:SQLはカラムの追加は手間のため
データ抽出後のPDF削除:保存容量の削減
データの可視化
3.実装編:データ抽出
まずはデータ抽出法に関して紹介します。データ抽出のサンプルとしては分かりやすくトヨタ自動車を選定しました。
3-1.全コード
[IN]
#EDINETから有価証券報告書のデータ抽出
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import os
import glob
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime, timedelta
import sqlite3
import time
import urllib3
import logging
import warnings
logging.getLogger("tabula.environment_info").setLevel(logging.ERROR) #tabulaのログを非表示にする
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
pd.options.display.max_columns = 30
#フォルダ作成
if not os.path.exists('output'): os.mkdir('output')
if not os.path.exists('database'): os.mkdir('database')
# conn = sqlite3.connect('database/sample_database.db')
# columns = ['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription', '平均年間給与(円換算)']
# df_original = pd.DataFrame(columns=columns)
# # データベースにテーブルを作成
# df_original.to_sql('sample_table', conn, if_exists='fail', index=False)
# display(pd.read_sql('select * from sample_table', conn))
# conn.close()
#検索する会社一覧
targets = ['キーエンス', 'ファナック', '中外製薬', 'サントリーHD', 'アサヒビール', '武田薬品工業', 'ソニーグループ',
'味の素', 'サントリー', 'アドバンテスト', '富士フイルム', '任天堂', 'ファーストリテイリング', 'JFEスチール (JFEHD)', '三菱ケミカル',
'千代田化工建設', 'オリンパス', 'エーザイ', '日本ペイントHD', 'JT(日本たばこ産業)',
'積水化学工業', '日立製作所', '協和キリン', '住友化学',
'キリン(KIRIN)', 'アシックス', '三菱重工業', '出光興産', '東京応化工業', '富士通', '王子HD', '塩野義製薬',
'トヨタ自動車', '日揮', '信越化学工業','ディー・エヌ・エー', 'オムロン',
'ユニ・チャーム', '島津製作所', '三井化学', 'ニトリ', '江崎グリコ', '日産化学', 'NEC', 'ニコン', '日産自動車',
'三菱電機', 'AGC', 'ヒロセ電機', 'クボタ', '花王', 'ローム', 'デンソー',
'アイシン', '東ソー', '関西ペイント', '本田技研工業']
#指定する検索日
def generate_date_sequence(start_date: str, end_date: str = None) -> list:
if end_date is None:
end_date = datetime.now().strftime("%Y-%m-%d")
start = datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.strptime(end_date, "%Y-%m-%d")
date_list = []
current_date = start
while current_date <= end:
date_list.append(current_date.strftime("%Y-%m-%d"))
current_date += timedelta(days=1)
return date_list
import tabula
#有価証券報告書のPDFから平均年間給与を抽出
def get_wageAvg(path_pdf:str):
dfs = tabula.read_pdf(path_pdf, pages='all', lattice=True)
for idx, df in enumerate(dfs):
# DataFrameが空でないことを確認
if not df.empty:
# カラム名に '平均年間給与(円)' が含まれている場合
if any(['平均年間給与' in col for col in df.columns]):
return df
# 1 行目に '平均年間給与' が含まれている場合
elif (df.iloc[0].astype(str).str.contains('平均年間給与')).any():
# 1 行目をカラム名に設定し、2 行目からのデータを抽出
df.columns = df.iloc[0]
df = df.iloc[1:].reset_index(drop=True)
return df
# 条件に一致するデータフレームが見つからない場合
return None
#平均年間給与から数値を円単位で抽出(千円単位の場合は1000倍)※表がずれるため最終列を抽出する
def __extract_wage_value(df: pd.DataFrame):
target_column = None # カラム名を格納する変数
for col in df.columns:
if '平均年間給与' in col: # カラム名に '平均年間給与' の文字列が含まれているカラムを探す
target_column = col
break
if target_column is None:
return None
# '千' が含まれている場合は 1000 をかける
f = lambda x: int(x.replace(',', '')) # カンマを削除+int型に変換する関数
if '千' in target_column:
return f(df[target_column].iloc[0]) * 1000
else:
return f(df[target_column].iloc[0])
def extract_wage_value(df: pd.DataFrame):
df_output = df.copy() # 入力データフレームをコピー
df_output = df_output.dropna(how='all', axis=1) # 全ての値が欠損値の列を削除※一部のデータで一番右にNaNが入るため
target_column = None # カラム名を格納する変数
for col in df_output.columns:
if '平均年間給与' in col: # カラム名に '平均年間給与' の文字列が含まれているカラムを探す
target_column = col
break
if target_column is None:
return None
# '千' が含まれている場合は 1000 をかける
f = lambda x: int(x.replace(',', '').replace('円', '').replace('千', '')) # カンマ+不要な文字を削除+int型に変換する関数
if '千' in target_column:
return f(df_output.iloc[0, -1]) * 1000
else:
return f(df_output.iloc[0, -1])
def remove_PDFfiles(path='output/'):
for file in glob.glob(path+'*.pdf'):
os.remove(file)
def get_Companydata(df, namekey:str, docDescKey='有価証券報告書'):
if len(df):
df = df[df['filerName'].str.contains(namekey, na=False, regex=False)] # regex=False を追加
df = df[df['docDescription'].str.contains(docDescKey, na=False, regex=False)] # regex=False を追加
df.reset_index(drop=True, inplace=True)
#欲しい情報だけ抽出
df = df[['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription']]
return df
else:
return []
def getPDF_EDINETAPI(df_company, verbose=False):
#個別の会社のデータ抽出
docid = df_company.loc[0].docID
company_name = df_company.loc[0].filerName
#APIのURL
url = endpoint_base + 'documents/' + docid
# 書類取得APIのリクエストパラメータ(EDINET API仕様書 P40)
params = {"type" : 2}
# 出力ファイル名
_date = datetime.strptime(df_company.loc[0].submitDateTime, '%Y-%m-%d %H:%M') #提出日の文字列をdatetime型に変換
submit_date = _date.strftime('%Y%m%d') #datetime型を文字列に変換
filename = f'{company_name}_{submit_date}.pdf'
# 書類取得APIの呼び出し
res = requests.get(url, params=params, verify=False)
# ファイルへ出力
if res.status_code == 200:
with open('output/'+filename, 'wb') as f:
for chunk in res.iter_content(chunk_size=1024):
f.write(chunk)
if verbose:
print(f'output/{filename}出力完了')
return filename
def insertData_toSQL(conn, df: pd.DataFrame, table_name: str) -> None:
# 新しいデータフレームのdocIDを取得
new_doc_id = df.loc[0, 'docID']
company_name = df.loc[0, 'filerName']
# docIDがデータベースに存在するかどうかを確認
existing_doc_id = pd.read_sql(f"SELECT docID FROM {table_name} WHERE docID = '{new_doc_id}'", conn)
# docIDが存在しない場合にのみデータを挿入
if existing_doc_id.empty:
df.to_sql(table_name, conn, if_exists='append', index=False)
print(f"Data inserted.:{new_doc_id} {company_name}")
else:
print(f"Data already exists.:{new_doc_id} {company_name}")
def extractData_fromSQL(DB='database/sample_database.db', tablename='sample_table'):
conn = sqlite3.connect(DB)
output = pd.read_sql(f'SELECT * FROM {tablename}', conn)
conn.close()
return output
# EDINET API
endpoint_base = "https://disclosure.edinet-fsa.go.jp/api/v1/"
endpoint = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"[OUT]
3-2.前準備
事前に下記を実行しました。
必要なライブラリの呼び出し
処理中の警告を非表示
PandasのDataFrameの列数制限の設定
[IN]
#EDINETから有価証券報告書のデータ抽出
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
import os
import glob
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime, timedelta
import sqlite3
import time
import urllib3
import logging
import warnings
logging.getLogger("tabula.environment_info").setLevel(logging.ERROR) #tabulaのログを非表示にする
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
pd.options.display.max_columns = 30[OUT]
-3-3.フォルダ作成
EDINET-APIで抽出したPDFの保存およびDatabase用ファイルの保存フォルダを作成します。
[IN]
#フォルダ作成
if not os.path.exists('output'): os.mkdir('output')
if not os.path.exists('database'): os.mkdir('database')[OUT]
-
3-4.DataBaseの初期化:SQLite3
最終的なデータは下記のように保存します。今回は小規模データのため、データ保存をファイルで簡単にできるSQList3を使用しました。
DBファイル名やテーブル名は自分が好きなように設定可能です。

[IN]
conn = sqlite3.connect('database/sample_database.db')
columns = ['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription', '平均年間給与(円換算)']
df_original = pd.DataFrame(columns=columns)
# データベースにテーブルを作成
df_original.to_sql('sample_table', conn, if_exists='fail', index=False)
display(pd.read_sql('select * from sample_table', conn))
conn.close()[OUT]
-
3-5.検索する会社を設定
検索する会社を設定しました。例えばトヨタではグループ会社がたくさんあるため”トヨタ自動車”まで記載しております。
とりあえず適当に会社を見繕いました。
[IN]
targets = ['キーエンス', 'ファナック', '中外製薬', 'サントリーHD', 'アサヒビール', '武田薬品工業', 'ソニーグループ',
'味の素', 'サントリー', 'アドバンテスト', '富士フイルム', '任天堂', 'ファーストリテイリング', 'JFEスチール (JFEHD)', '三菱ケミカル',
'千代田化工建設', 'オリンパス', 'エーザイ', '日本ペイントHD', 'JT(日本たばこ産業)',
'積水化学工業', '日立製作所', '協和キリン', '住友化学',
'キリン(KIRIN)', 'アシックス', '三菱重工業', '出光興産', '東京応化工業', '富士通', '王子HD', '塩野義製薬',
'トヨタ自動車', '日揮', '信越化学工業','ディー・エヌ・エー', 'オムロン',
'ユニ・チャーム', '島津製作所', '三井化学', 'ニトリ', '江崎グリコ', '日産化学', 'NEC', 'ニコン', '日産自動車',
'三菱電機', 'AGC', 'ヒロセ電機', 'クボタ', '花王', 'ローム', 'デンソー',
'アイシン', '東ソー', '関西ペイント', '本田技研工業'][OUT]3-6.日付の連番作成:generate_date_sequence()
APIに渡すためのdateの連番を作成する関数です。これで各提出日におけるデータをAPIで抽出していきます。
[IN]
#指定する検索日
def generate_date_sequence(start_date: str, end_date: str = None) -> list:
if end_date is None:
end_date = datetime.now().strftime("%Y-%m-%d")
start = datetime.strptime(start_date, "%Y-%m-%d")
end = datetime.strptime(end_date, "%Y-%m-%d")
date_list = []
current_date = start
while current_date <= end:
date_list.append(current_date.strftime("%Y-%m-%d"))
current_date += timedelta(days=1)
return date_list
start_date = "2023-04-20"
date_sequence = generate_date_sequence(start_date)
date_sequence[OUT]
['2023-04-20',
'2023-04-21',
'2023-04-22',
'2023-04-23',
'2023-04-24',
'2023-04-25',
'2023-04-26',
'2023-04-27',
'2023-04-28',
'2023-04-29',
'2023-04-30']3-7.会社データ抽出:get_Companydata()
APIの処理:requests.get(endpoint, params=params, verify=False)で取得したデータから指定の会社データのみを抽出します。出力前後の結果は下記の通りです。
多数のカラム・会社のデータの中から指定の会社の特定情報のみ抽出しました(書類ID, Code番号、会社名、提出日、書類詳細)。
[IN]
def get_Companydata(df, namekey:str, docDescKey='有価証券報告書'):
if len(df):
df = df[df['filerName'].str.contains(namekey, na=False, regex=False)] # regex=False を追加
df = df[df['docDescription'].str.contains(docDescKey, na=False, regex=False)] # regex=False を追加
df.reset_index(drop=True, inplace=True)
#欲しい情報だけ抽出
df = df[['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription']]
return df
else:
return [][IN]
# 書類一覧APIのリクエストパラメータ
params = {
"date" : "2022-06-23", #test:2019-03-25
"type" : 2,
}
res = requests.get(endpoint, params=params, verify=False)
results = json.loads(res.text)['results']
df = pd.DataFrame(results)
df_toyota = get_Companydata(df, 'トヨタ自動車')
display(df)
display(df_toyota)[OUT]

3-8.EDINET-APIでPDF抽出:getPDF_EDINETAPI()
EDINET-APIで指定した会社の有価証券報告書のPDFを抽出してoutputフォルダに保存します(必要なdocIDは前節のデータを利用)。出力は次の工程に渡せるように保存PDFのPATHを返します。
なお有価証券報告書には”訂正有価証券報告書”もありこれには年収情報は記載されてないため、本処理時には「訂正」の文字がある場合は処理しないようにしています。
[IN]
def getPDF_EDINETAPI(df_company, verbose=False):
#個別の会社のデータ抽出
docid = df_company.loc[0].docID
company_name = df_company.loc[0].filerName
#APIのURL
url = endpoint_base + 'documents/' + docid
# 書類取得APIのリクエストパラメータ(EDINET API仕様書 P40)
params = {"type" : 2}
# 出力ファイル名
_date = datetime.strptime(df_company.loc[0].submitDateTime, '%Y-%m-%d %H:%M') #提出日の文字列をdatetime型に変換
submit_date = _date.strftime('%Y%m%d') #datetime型を文字列に変換
filename = f'{company_name}_{submit_date}.pdf'
# 書類取得APIの呼び出し
res = requests.get(url, params=params, verify=False)
# ファイルへ出力
if res.status_code == 200:
with open('output/'+filename, 'wb') as f:
for chunk in res.iter_content(chunk_size=1024):
f.write(chunk)
if verbose:
print(f'output/{filename}出力完了')
return filename
# 書類一覧APIのリクエストパラメータ
params = {
"date" : "2022-06-23", #test:2019-03-25
"type" : 2,
}
res = requests.get(endpoint, params=params, verify=False)
results = json.loads(res.text)['results']
df = pd.DataFrame(results)
df_toyota = get_Companydata(df, 'トヨタ自動車')
filename = getPDF_EDINETAPI(df_toyota, verbose=True)
print(filename)[OUT]
output/トヨタ自動車株式会社_20220623.pdf出力完了
トヨタ自動車株式会社_20220623.pdf
3-9.PDFデータから平均年収を抽出:get_wageAvg
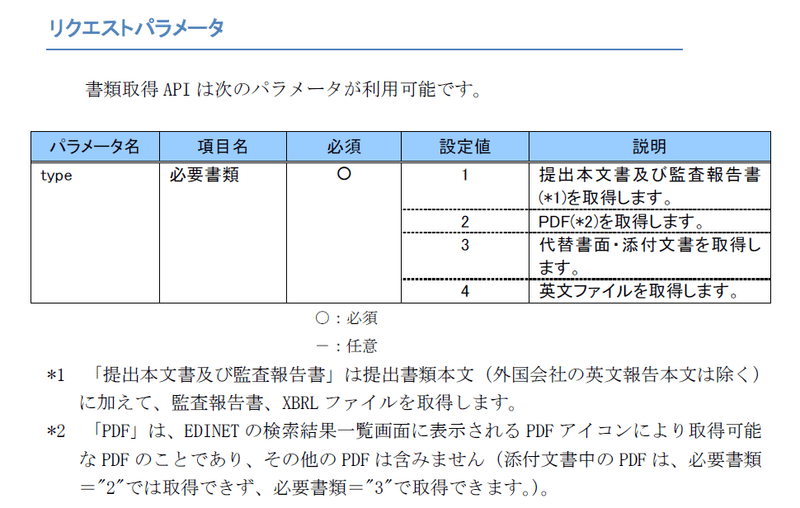
tabula-pyを使用して取得したPDFの有価証券報告書から、下表の「提出会社の状況」部分を抽出します。
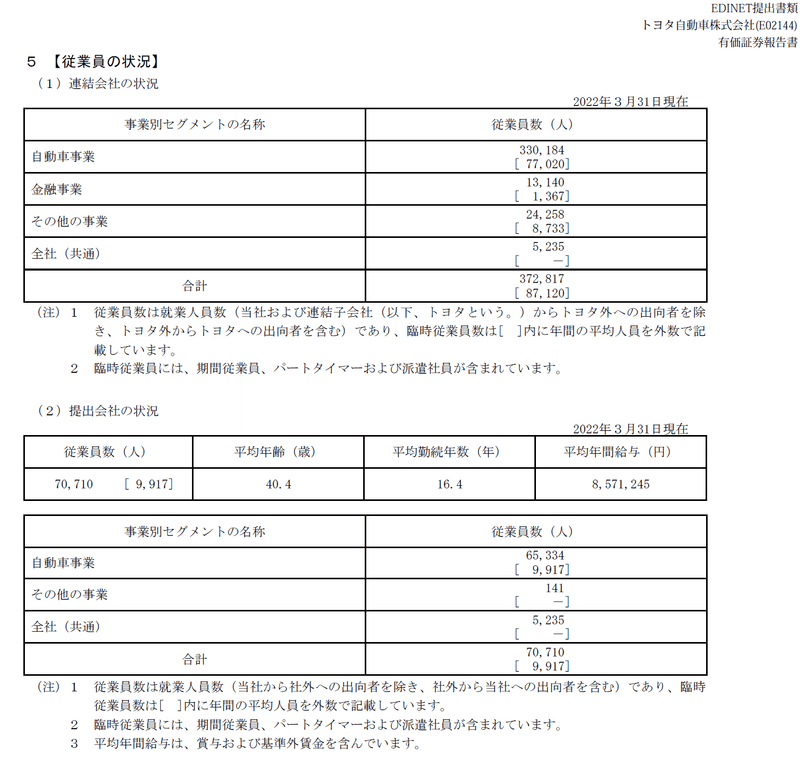
tabulaのフォントに関する警告が出ますが、特に問題はなさそうなので無視します。
[IN]
#有価証券報告書のPDFから平均年間給与を抽出
def get_wageAvg(path_pdf:str):
dfs = tabula.read_pdf(path_pdf, pages='all', lattice=True)
for idx, df in enumerate(dfs):
# DataFrameが空でないことを確認
if not df.empty:
# カラム名に '平均年間給与(円)' が含まれている場合
if any(['平均年間給与' in col for col in df.columns]):
return df
# 1 行目に '平均年間給与' が含まれている場合
elif (df.iloc[0].astype(str).str.contains('平均年間給与')).any():
# 1 行目をカラム名に設定し、2 行目からのデータを抽出
df.columns = df.iloc[0]
df = df.iloc[1:].reset_index(drop=True)
return df
# 条件に一致するデータフレームが見つからない場合
return None
df_wage_toyota = get_wageAvg(f'output/{filename}')
df_wage_toyota[OUT]
-
なお別のPDFだと下記のようになり常に同じ形式で取得できるとは限りません。よって、後処理では一番後ろの数値(かつNanで無いもの)を抽出するようにしました。

3-10.DataFrameから値の抽出:extract_wage_value()
理想はPDFから抽出した表を結合したいのですがtabula-pyの性能上100%同じ形では抽出できないため途中でエラーが出ます。
妥協案として「平均年間給与」だけでも抽出できるようにしました。有価証券報告書に記載の体裁が微妙に異なるためif文やlambda関数で前処理を加えたりしています。
[IN]
def extract_wage_value(df: pd.DataFrame):
df_output = df.copy() # 入力データフレームをコピー
df_output = df_output.dropna(how='all', axis=1) # 全ての値が欠損値の列を削除※一部のデータで一番右にNaNが入るため
target_column = None # カラム名を格納する変数
for col in df_output.columns:
if '平均年間給与' in col: # カラム名に '平均年間給与' の文字列が含まれているカラムを探す
target_column = col
break
if target_column is None:
return None
# '千' が含まれている場合は 1000 をかける
f = lambda x: int(x.replace(',', '').replace('円', '').replace('千', '')) # カンマ+不要な文字を削除+int型に変換する関数
if '千' in target_column:
return f(df_output.iloc[0, -1]) * 1000
else:
return f(df_output.iloc[0, -1])
df_wage_value_toyota = extract_wage_value(df_wage_toyota)
df_wage_value_toyota[OUT]
85712453-11.SQLへデータ保存:insertData_toSQL()
「平均年間給与」が抽出できたらDatabaseに追加します。SQLの詳細は後述しますのでここではコードのみ紹介となります。
[IN]
def insertData_toSQL(conn, df: pd.DataFrame, table_name: str) -> None:
# 新しいデータフレームのdocIDを取得
new_doc_id = df.loc[0, 'docID']
company_name = df.loc[0, 'filerName']
# docIDがデータベースに存在するかどうかを確認
existing_doc_id = pd.read_sql(f"SELECT docID FROM {table_name} WHERE docID = '{new_doc_id}'", conn)
# docIDが存在しない場合にのみデータを挿入
if existing_doc_id.empty:
df.to_sql(table_name, conn, if_exists='append', index=False)
print(f"Data inserted.:{new_doc_id} {company_name}")
else:
print(f"Data already exists.:{new_doc_id} {company_name}")[OUT]3-12.フォルダ内のPDF削除:remove_PDFfiles
欲しいデータをDB移動後はPDFは不要となります。outputフォルダに仮保存したすべてのPDFファイルを削除しました。
[IN]
def remove_PDFfiles(path='output/'):
for file in glob.glob(path+'*.pdf'):
os.remove(file)[OUT]
-
4.実装編:実行処理
実行は下記ループ処理を行います。
各日付におけるデータを取得
調べたい企業が抽出したデータ内にあるか調べて、存在するならデータ抽出、年収値取得、Databaseへ保存を実行
サーバーへの負荷を考慮してtime.sleep()を追加
なお本コードは「df_wage = get_wageAvg(f'output/{filename}')」の部分で処理がよく止まります。対応としては止まったdateから再度処理を実行しなおしました。
原因はPDFファイルが保存されていないためですが、再度実行するとうまくいくためおそらく処理が間に合っていないと思われます。処理速度に合わせてtime.sleep()の時間を延ばすと安定するかもしれません。
[IN]
# 開始日を指定し、終了日は現在の日付を使用する
# start_date = "2019-03-20"
# start_date = "2021-06-27"
# start_date = "2022-03-07"
# start_date = "2022-06-20"
start_date = "2022-09-25"
start_date = "2022-11-27"
date_sequence = generate_date_sequence(start_date)
conn = sqlite3.connect('database/sample_database.db')
for date in date_sequence:
print(f"Processing date:{date}")
params = {"date": date, "type": 2}
res = requests.get(endpoint, params=params, verify=False)
#データがない場合はスキップ
try:
results = json.loads(res.text)['results']
df = pd.DataFrame(results)
df.append(df)
except (json.JSONDecodeError, KeyError):
print(f"Error: Unable to parse JSON or 'results' key not found for date {date}")
continue
for idx, target in enumerate(targets):
if df is not None:
df_company = get_Companydata(df, target)
#会社名が一致するものがあれば処理
if len(df_company):
#もし"docDescription"の値が全て訂正を含む場合はスキップ
if df_company['docDescription'].str.contains('訂正').all():
continue
filename = getPDF_EDINETAPI(df_company, verbose=True)
time.sleep(1.5) #APIの負荷軽減のため0.2秒待機
df_wage = get_wageAvg(f'output/{filename}')
if df_wage is None: #有価証券報告書の訂正報告書の場合はスキップ
continue
wage_value = extract_wage_value(df_wage)
df_company['平均年間給与(円換算)'] = wage_value
table_name = 'sample_table'
insertData_toSQL(conn, df_company, table_name) #DataBaseに格納
remove_PDFfiles() #DataBaseに格納したらPDFファイルは削除[OUT]
・
・
・
Processing date:2023-04-27
Error: Unable to parse JSON for date 2023-04-27
Processing date:2023-04-28
Error: Unable to parse JSON for date 2023-04-28
Processing date:2023-04-29
Error: Unable to parse JSON for date 2023-04-29
Processing date:2023-04-30
Error: Unable to parse JSON for date 2023-04-305.実装編:データ保存(SQL)
抽出したデータはSQLでデータベースに保存しました。本章ではSQliteでの処理内容を紹介します。詳細は下記記事に記載済みのため、今回は動作のみを簡単に紹介します。
5-1.DBファイル作成/テーブルの追加:初期化
SQliteではDatabaseをdbファイルで管理します。そのdbファイル内にテーブルを作成してデータを管理します。
DB接続/作成:sqlite3.connect(path):sqlite3はSQLの「CREATE DATABASE <DB名>」という操作はなく、dbファイルでDBを管理します。DB接続はsqlite3.connect(filepath)です。もし指定パスにファイルがなければ新規作成となります。
DB切断:conn.close():DB接続を切断する場合はconn.close()を使用します。DB接続中はメモリを使用するため基本的に処理完了後にDBは切断します。
[IN]
conn = sqlite3.connect('database/sample_database.db')
columns = ['docID', 'edinetCode', 'filerName', 'submitDateTime', 'docDescription', '平均年間給与(円換算)']
df_original = pd.DataFrame(columns=columns)
# データベースにテーブルを作成
df_original.to_sql('sample_table', conn, if_exists='fail', index=False)
display(pd.read_sql('select * from sample_table', conn))
conn.close()[OUT]
5-2.Databaseからデータ読み込み:extractData_fromSQL()
まずSQliteの特徴として「カーソル取得(Cursor):conn.cursor()」を実施することでCursorに直接SQL文を記載してデータ抽出が可能です。
ただし今回のデータ構造はすでに分かっており、複雑なSQL文を記載する必要性もないためPandasの「df.to_sql()」を使用して簡単にDataFrame型で抽出します。
データ量も少ないため「SELECT * FROM <テーブル名>;」で全データを一括抽出します
[IN]
pd.read_sql('select * from sample_table', conn)
[OUT]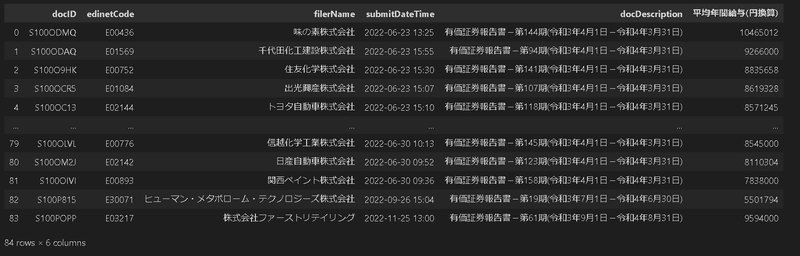
毎回DBの接続/切断コードを記載するのも手間のため、抽出コードを記載しました。DBのパスとテーブル名は自分が作成した値に変更してください。
[IN]
def extractData_fromSQL(DB='database/sample_database.db', tablename='sample_table'):
conn = sqlite3.connect(DB)
output = pd.read_sql(f'SELECT * FROM {tablename}', conn)
conn.close()
return output
df_SQL = extractData_fromSQL()
df_SQL [OUT]
同上の結果6.実装編:可視化
6-1.データの前処理1:不適な値除去(remove_low_wage)
前章で前処理を加えたはずなのですが一部のデータで①円単位への換算が出来ていない、②Nanが混ざる、③なぜか文字列で抽出される 問題が発生しています。
[IN]
df_SQL = extractData_fromSQL()
display(df_SQL.describe())
print(df_SQL['平均年間給与(円換算)'].isnull().sum())
print(f'平均年間給与(円換算)のデータ型:{type(df_SQL["平均年間給与(円換算)"].loc[0])}')[OUT]
1
平均年間給与(円換算)のデータ型:<class 'str'>
とりあえず、前処理を加えてほしい値だけ使用できるようにしました。
[IN]
def remove_low_wage(df: pd.DataFrame, wage_column: str = "平均年間給与(円換算)", threshold: int = 10000) -> pd.DataFrame:
# 平均年間給与を整数に変換(変換できない場合は None にする)
df[wage_column] = pd.to_numeric(df[wage_column], errors='coerce')
df_filtered = df[df[wage_column].notnull()] # 平均年間給与が None のデータを除去
df_filtered = df_filtered[df_filtered[wage_column] > threshold] # 平均年間給与が 10000 円以下のデータを除去
return df_filtered[OUT]
処理前:(84, 6), 処理後:(82, 6)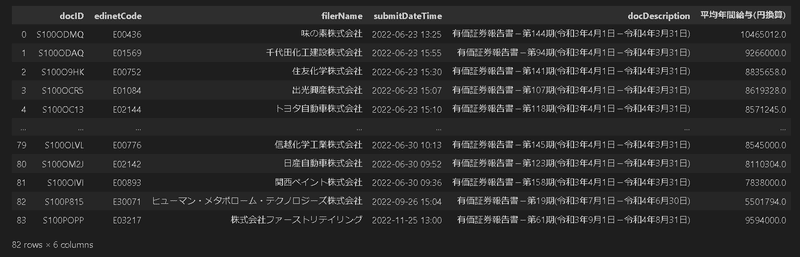
6-2.データの前処理2:欲しいデータの抽出
準備はできたため欲しいデータを抽出していきます。なおSQL文が記載できる人は5章においてSQliteのクエリに直接記載するのもOKです。
今回のデータ抽出は2022年以降、かつ同じ企業のデータが複数あるなら新しい方のみを残して残りは削除します。
処理完了したらプロット用に値でソートしておきます。
期間で抽出:pd.to_datetimeでdatetimeに変換して条件抽出
重複削除:df.drop_duplicatesで企業の重複を削除
前処理:前節で作成した前処理関数:remove_low_wage()を実行
ソート:df_filtered.sort_valuesで年収を元にソート
[IN]
# submitDateTime を datetime 型に変換
df_SQL["submitDateTime"] = pd.to_datetime(df_SQL["submitDateTime"])
# 2022年度以降のデータのみ抽出
df_filtered = df_SQL[df_SQL["submitDateTime"].dt.year >= 2022]
# 同じ会社が抽出された場合、新しいほうのデータだけを残す
df_filtered = df_filtered.drop_duplicates(subset=["filerName"], keep="first")
df_filtered = remove_low_wage(df_filtered)
df_filtered.sort_values("平均年間給与(円換算)", ascending=True, inplace=True)[OUT]
-
6-3.横棒グラフの作成:plot_colored_barh()
年収を横棒グラフで作成しました。体裁調整は下記の通りです。
x軸はカンマ付き整数表示
縦軸の補助線追加
希望年収(閾値:threshold)を設定して色分け可能:default=1,000万円
[IN]
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def plot_colored_barh(df: pd.DataFrame, threshold: int=1e7):
fig, ax = plt.subplots(figsize=(15, 10), facecolor="white")
red_label_added = False
blue_label_added = False
for index, row in df.iterrows():
is_above_threshold = row["平均年間給与(円換算)"] >= threshold
color = "red" if is_above_threshold else "blue"
label = None
if is_above_threshold and not red_label_added:
label = f'{int(threshold):,}以上'
red_label_added = True
elif not is_above_threshold and not blue_label_added:
label = f'{int(threshold):,}未満'
blue_label_added = True
ax.barh(row["filerName"], row["平均年間給与(円換算)"], color=color, label=label)
ax.set(xlabel="平均年間給与(円換算)", ylabel="会社名")
ax.xaxis.set_major_locator(ticker.MultipleLocator(1000000)) # 100万円単位で目盛りを設定
ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda x, pos: f'{int(x):,}'))
ax.grid(axis='x', linestyle='--', alpha=0.7) # 縦軸に補助線を追加
ax.legend(loc='upper right')
plt.tight_layout()
plt.show()[OUT]
-7.データ分析
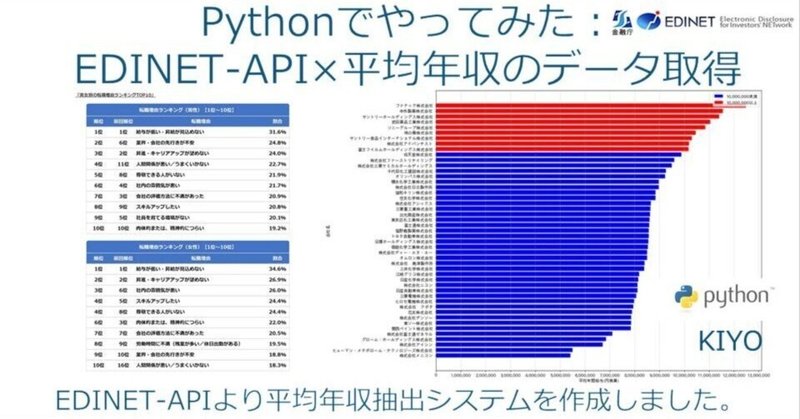
完成したコードを実行します。あくまで全会社ではなく指定した会社内の比較ですが、1,000万円を超える会社は比較的少なかったです。
[IN]
df_SQL = extractData_fromSQL()
# submitDateTime を datetime 型に変換
df_SQL["submitDateTime"] = pd.to_datetime(df_SQL["submitDateTime"])
# 2022年度以降のデータのみ抽出
df_filtered = df_SQL[df_SQL["submitDateTime"].dt.year >= 2022]
# 同じ会社が抽出された場合、新しいほうのデータだけを残す
df_filtered = df_filtered.drop_duplicates(subset=["filerName"], keep="first")
df_filtered = remove_low_wage(df_filtered)
df_filtered.sort_values("平均年間給与(円換算)", ascending=True, inplace=True)
plot_colored_barh(df_filtered, threshold=1e7)[OUT]
-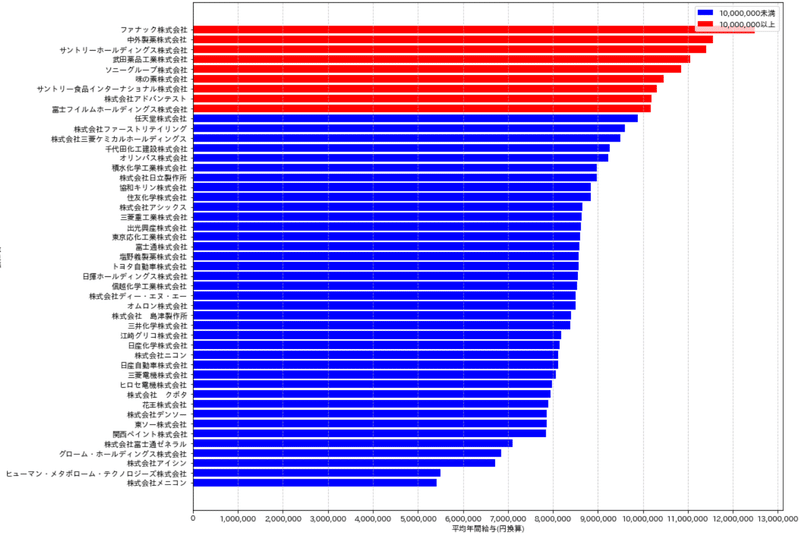
ちなみにファナック本社は山梨にあるため田舎が無理な人には合わないかもしれません。
8.所感
今回のデータ抽出システムは指定した会社しか選択できないため、業界の年収比較くらいまでしか使えません。全会社・業界の中で年収の高い順となると結構大変な処理になります。
なお初期目的とは異なりますが働く目的はお金だけでなく、残業時間(自由な時間)、スキルアップなどの理由もあるため一概に「高年収=幸福度」ではありません。ただ「給与が高い」とは人事的なA~D評価や口だけの賞賛だけでなく、定量的な評価であるため軽視はできません。
年収を基準にするときの業界年収の比較、提示額との大きなずれ確認などには使えると思います。
【コード編】
本当は時間軸で年収推移も確認したかったのですが、うまく取得できませんでした。HTTP処理量が多いとブロックされるのかもしれません。
それにしても、このAPIの目的は実際何なんだろうか?(ファイルのダウンロードだけ??直接データ抽出はうまくやればできるのか?)
参考資料
あとがき
有価証券報告書の記載方法が微妙に違っているので思った以上に時間かかった。せっかくのGWの時間が消えていく・・・・・
この記事が気に入ったらサポートをしてみませんか?