
【無料ローカルLLM実行環境】LM Studio【Windows】

想定している読者
ローカルで大規模言語モデルを実行したい人
(Dockerやwebアプリでなく)Windows 通常アプリで利用したい人
はじめに
Linux 上の ollama + open-webui を利用したLLMローカル実行の話をしましたが、
ローカルで実行するだけなら LM STUDIO の方がより簡単です。※ ただし 個人的には UI が独特でわかりにくいです。
LM Studio インストール
公式ページから「Download LM Studio for Windows」を選択するとインストール用の実行ファイルをダウンロードできます。
実行するとプロファイルフォルダ以下の「AppData\Local\LM-Studio」にインストールされます。ショートカットはデスクトップに表示されます。
ショートカットをダブルクリックするとアプリが起動します。
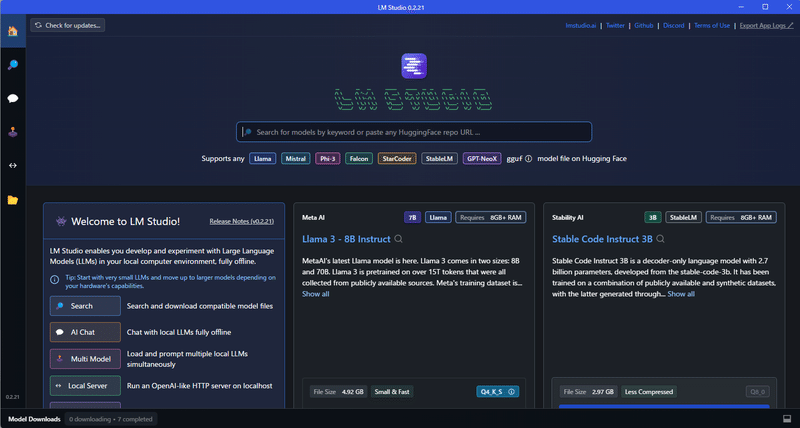
UIは Discord ライクで独特です。機能タブに相当するのは、左側の「ホーム」「虫眼鏡」などのアイコンです。ホームでは、おすすめモデルが表示されています。
まずは、最初に表示されている Meta の Llama 3 8B Instruct モデルをダウンロードしましょう。(筆者が試した限りだと、公開されているオープンソースモデルで、一般的なチャット利用において最も優秀でした)
GGUF モデルのファイル名について
LM Studio では、家庭パソコンなどの小規模なシステム向けにパッケージ化された GGUF 拡張子の LLM モデルファイルを利用できます。Ollama も同じです。
GGUF ファイル名や下部に表示されているアイコンの説明もします。
Llama 3:モデルファイルの名称です
8B:パラメータの数です 8 Billion なので、80億です。
Instruct:Instruct チューニングを行ったモデルです。Chat 用途では Instruct モデルを利用するのが一般的です。
Q4_K_S:量子化(離散化)の程度を表すものです。数字の小さなものは品質を犠牲にしてより高速でより省メモリになります。たとえば、7B/8B の Q4_* モデルは GPU メモリ8GBあればGPUのみで実行できますが、Q8_* モデルは一部を CPU に頼る事になります。少しでも CPU 利用になると、動作速度が半分以下に落ちます。
K は量子化手法の名前で S や M はサイズです。 SmallやMedium?
Stable Diffusion とは異なり、LLM の場合は効率よくメモリを分散させられるようで、筆者環境の 1660ti(6G) + 1650(4G) 二枚刺しパソコンでも 6+4=10 GB のメモリが利用できます。また、GPU は必須ではなく、CPU 単体でも(1/3程度の実行速度ですが)実行可能です)
Llama3 のダウンロードが終了すれば、左側の「フォルダアイコン」をクリックします。ダウンロードしたものが一覧表示されます。
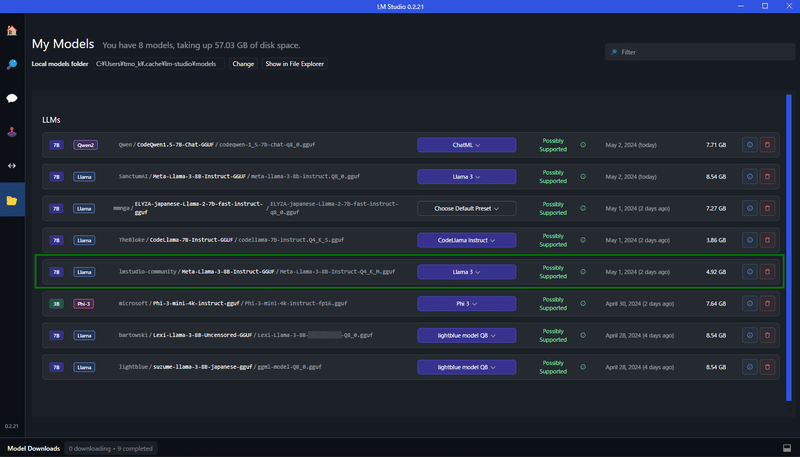
プリセットの作成
LLM の利用には、それぞれの用途などに応じたプロファイルを作成して紐つけるのが一般的です。
まずは最上部の青いボタンからダウンロードした「lmstudio-community Meta Llama3 Instruct 7B Q4_K_M gguf」を選択します。
今回ダウンロードした GGUF モデルは、あらかじめ用意された Llama3プリセットがあるため、それが自動で紐付いています。
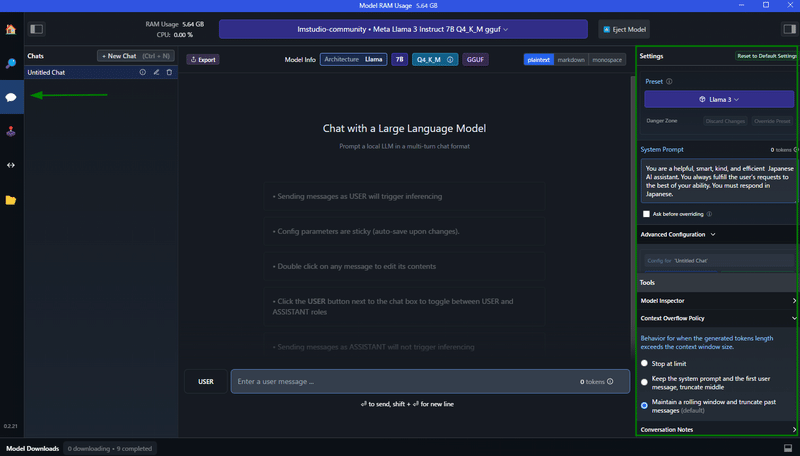
左の AI Chat アイコンをクリックするとチャット画面になります。右側にプリセットの設定欄があるので、設定していきます。
System Prompt
ChatGPT でもありますが、どのような用途で利用するか予め指示しておきます。例として次の指示を記述しておきます。日本語で返答するという意味を入れておけば、英語で返ってくる頻度が減ります。※ 日本語で記述しても理解してくれますが、英語記述の方が(気持ち程度)正しく理解してくれるように思います
You are a helpful, smart, kind, and efficient Japanese AI assistant. You always fulfill the user's requests to the best of your ability. You must respond in Japanese always.
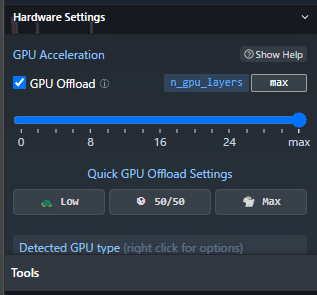
GPU Acceleration
NVIDIA 製 GPU が搭載されているパソコンであれば、GPU を利用する事ができます。全部で33層あるレイヤーのいくつを利用するか指定します。たとえば、8B Q4_* モデルの場合、8G以上の GPU メモリがあれば GPU ですべて処理できます。つまり max に設定できます。高性能な GPU なのに、反応が遅いなと感じる場合は、この設定を見直してください。逆に CPU だけで実行したい場合は、0 を選択します。
その他の設定
返答のバリエーション幅を決める Temperature などの設定もありますが、基本的にモデル作成者側が適切な値を入れているので、その他の値は特に弄る必要はありません。
設定が終われば、右上の「Override Preset」で保存します。プリイン・プリセットである「Llama3」を壊したくない場合は、少し下に「New Preset」ボタンがあるので、新しく名前をつけて保存します。
チャットの開始
あとはチャットを始めるだけです。下記画面例では設定を忘れていますが、表示を plaintext でなく、markdown 形式にしておくと整形された表示になります。
虫眼鏡アイコンから huggingface の 様々な GGUF モデルを直接ダウンロードできます。最近公開された Microsoft の Phi3 モデルもありますので、ぜひ試してみください。
この記事が気に入ったらサポートをしてみませんか?