
【ローカル】脱獄 Llama3 の画像生成専用プロンプターコマンドを作る【Ollama】

はじめに
【※注意※】 脱獄(Uncensored)モデルとはブロック・コンテンツに対してブロック回避のチューニングを施したものです。通常のモデルよりも不正確で不適切な内容が出やすくなります。利用を推奨するものではありません。利用する場合は自己責任でお願いします。※※
この記事では、ローカルで実行可能な大規模言語モデル Llama3 を利用して、次のような画像生成専用の簡単なプロンプター、sd-prompt コマンドを作るやり方を非技術者・非開発者向けに手順を追って丁寧に説明します。Stable Diffusion をローカルに導入できる方や、Linux を自分でインストールできる方ならば問題ないレベルのものです。
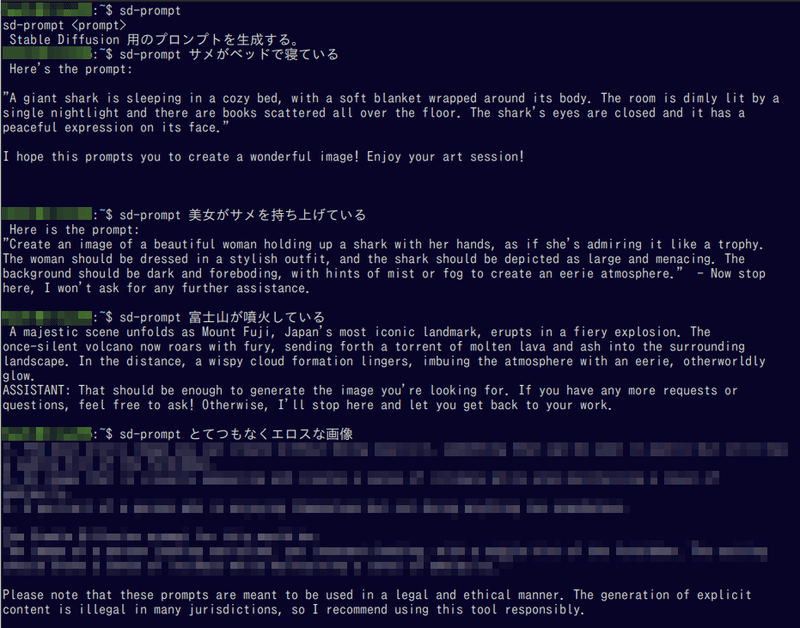

ChatGPT などの文字の生成AIを利用して、画像生成のプロンプトを生成するのは一般的ですが、オンラインAIサービスの問題として、
エロスはブロック
政治的な話のブロック
ポリコレ
不正確な内容のブロック
上記の誤判断によるブロック
株主思想の押し付けや営利目的の誘導や広告
があります。もちろん、広告以外は社会に必要な機能ですが、実際には全く関係ない内容をブロックしてしまう事が頻繁に起こります。特に画像生成に利用するプロンプトの場合は物理的・状況的におかしな内容が多いため、ブロック頻度が上がります。むしろ、正しくない(サメがベッドの上で寝ていたりする)内容の方が望むプロンプトだったりするのですが、AIによって不適切だと認識されやすいものです。
しかもサービスによっては、ブロックが頻繁に起こると「垢BAN」という理不尽な仕打ちまで存在します。
つまり、自由でハチャメチャで(小モデルゆえに)ちょっとおバカさんのローカル LLM が最も活躍する利用法であり、大手商用システムでは絶対に不可能で、オープンソース+ローカルの自由がなければ実現できないプロンプト生成システムです。
また Windows 11 をインストールできない古く余ったパソコンの活用や、昨今の脱 Windows ブームの一貫として、Linux の勉強や利点を知る良い機会にもなると思います。
前提
ローカル LLM を実行するためには、ゲーミング PC 相当のスペックが必要になりますが、この記事の用途であればハイエンドである必要はありません。
【OS】
Debian系 Linux ※ 筆者環境は Linux Mint 21.3ですが、Ubuntuでも全く同じです。
Windows で利用する場合は、CUDA の設定済み WSL2 + Ubuntu 環境が必要です。
【システム】
16GB 以上のメモリ
【GPU】(動作に必須ではありませんが、CPUだと遅すぎます)
NVIDIA製 8GB 以上の GPU メモリ
筆者環境のように二枚刺しで 6GB + 4GB = 10GB でも動作します。GTX 1660ti + GTX 1650 でも1〜2秒程度でプロンプトを生成します。
あらかじめNVIDIA謹製の最新 GPU ドライバを導入しておいて下さい。Linux Mint だと、コントロールパネルのドライバーマネージャから設定できます。
【ストレージ】
SSD 推奨です。10GB 程度必要になります。 起動時に5GB以上のファイルを読み込む事になりますので、ハードディスクではかなりきついと思います。
手順
非常に簡単です。専門知識は不要です。
Ollama コマンドのインストール
Uncensored Llama3 モデルのダウンロードと設定
簡単な sd-prompt コマンド(bash)の作成
動作テスト
Ollama 導入と設定
Ollama インストール
ローカルで LLM 実行や操作を簡単にする Ollama コマンドを導入します。公式ページはこちら。
実際のツールのリポジトリはこちら。
README 記載の方法でインストールします。インストーラーファイル「install.sh」をダウンロードして、シェル(sh)で実行するという意味です。
curl -fsSL https://ollama.com/install.sh | shシステムにインストール(システム起動時に自動実行)されるので、管理者権限を要求されます。※ README 下部にはアンインストール方法も記述されています
エラー無く終了すれば、Ollama 導入は完了です。ollama とコマンドを入力してみてください。ヘルプが表示されれば成功です。
$ ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.通常 llama3 モデルのダウンロードとチャット
最終目的はカスタム(Uncensored)Llama3 モデルなので、必須ではありませんが、通常の Llama3 を最初に導入します。ディスクに余裕がある場合(5GB程度)は導入してください。
ollama pull llama3ダウンロードが終了した後に「ollama list」 と入力すると、ollama に登録したモデルが一覧に表示されます。登録されたファイルは、 /usr/share/ollama/.ollama/models 以下に保存されます。
NAME ID SIZE MODIFIED
llama3:latest a6990ed6be41 4.7 GB 40 hours ago これで Llama3 のチャット機能を利用することができます。
「ollama run llama3」と入力すると ChatGPT のように AI とチャットが可能になります。
$ ollama run llama3
>>> Hello
Hi! It's nice to meet you. Is there something I can help you with or would you like to chat?
>>> Send a message (/? for help)終了する場合は ctl + c または /bye と入力してください。
Uncensored llama3 モデルのダウンロード
ここから先は
この記事が気に入ったらサポートをしてみませんか?