
匿名加工の手法から進め方までのステップバイステップガイド

はじめに
はじめまして、私はスタートアップでデータプロダクトの、プロダクトマネージャーを担当しているものです。匿名加工情報について調べる機会があったので、あらためて整理します。
以前、「【個人情報保護法】匿名加工情報の定義を確認する。」の記事で匿名加工情報について整理しましたが、この記事では、匿名加工の基本的な手法から具体的な進め方まで、わかりやすく解説します。データエンジニアからビジネスオーナーまで、匿名加工に関わる人に役立つ情報をめざします。
想定読者
データエンジニアやデータサイエンティスト
個人情報を取り扱う企業や組織の担当者
プライバシーに関心がある一般のインターネットユーザー
法律や規制に関心がある方
本記事で分かること
基本から応用まで: 匿名加工の基礎から高度な手法までを網羅的に学べます。
実践的な知識: 具体的な進め方やツールの使い方も紹介するため、すぐに実践できます。
法的リスクの軽減: プライバシーに関する法的要件を満たす方法を理解でき、リスクを軽減できます。
データ活用の促進: 匿名加工を適切に行うことで、データをより安全かつ効果的に活用できます。
注意事項・免責
本記事は文末の参考文献を元に整理したものです。詳細はそちらをご確認ください。
掲載している内容は個人の見解であり、所属する組織を代表するものではありません。
掲載されている内容は、可能な限り正確な情報を記載するように努めておりますが、100%を保証するものではありません。誤りが混在する場合や最新の情報ではない可能性があります。
情報の最新性や正確性を考え、予告なしで情報の更新や削除を行うこともあります。
本記事の利用や、参考は、ご自身のご判断と責任においてご利用頂ますようお願い致します。掲載した内容により何らかのトラブル・不利益・損害・損失等が発生しても一切の責任は負いかねます。
1. 匿名加工の法的背景
プライバシー保護の法的要件にどのように対応するか、具体的な法律とその適用例を紹介します。この章で、法的リスクを最小限に抑えるための基本的な知識を説明します。
1.1. 匿名加工と法律
匿名加工は、個人情報を特定できない形に加工する手法ですが、これには法的な基準が存在します。例えば、日本の個人情報保護法では、匿名加工情報の作成にあたっては特定の基準に従う必要があります。このセクションでは、そのような法的基準と、それがどのように匿名加工に影響するのかを詳しく説明します。
1.2.法律(匿名加工情報の作成等)を確認
個人情報保護法 第四章 個人情報取扱事業者等の義務等 >第4節 匿名加工情報取扱事業者(匿名加工情報の作成等)には、下記の定義があります。
第四十三条 個人情報取扱事業者は、匿名加工情報(匿名加工情報データベース等を構成するものに限る。以下この章及び第六章において同じ。)を作成するときは、特定の個人を識別すること及びその作成に用いる個人情報を復元することができないようにするために必要なものとして個人情報保護委員会規則で定める基準に従い、当該個人情報を加工しなければならない。
つまり、基準に従い加工しないといけない。と言われています。
2 個人情報取扱事業者は、匿名加工情報を作成したときは、その作成に用いた個人情報から削除した記述等及び個人識別符号並びに前項の規定により行った加工の方法に関する情報の漏えいを防止するために必要なものとして個人情報保護委員会規則で定める基準に従い、これらの情報の安全管理のための措置を講じなければならない。
安全管理措置を講じる責任がある
3 個人情報取扱事業者は、匿名加工情報を作成したときは、個人情報保護委員会規則で定めるところにより、当該匿名加工情報に含まれる個人に関する情報の項目を公表しなければならない。
匿名加工情報を作成したときには、何を加工したか公表すること。
4 個人情報取扱事業者は、匿名加工情報を作成して当該匿名加工情報を第三者に提供するときは、個人情報保護委員会規則で定めるところにより、あらかじめ、第三者に提供される匿名加工情報に含まれる個人に関する情報の項目及びその提供の方法について公表するとともに、当該第三者に対して、当該提供に係る情報が匿名加工情報である旨を明示しなければならない。
第三者提供する場合、項目と提供方法を公表する。
また、提供先の第三者に対して、当該提供にかかる情報が匿名加工情報であることを知らせる。
5 個人情報取扱事業者は、匿名加工情報を作成して自ら当該匿名加工情報を取り扱うに当たっては、当該匿名加工情報の作成に用いられた個人情報に係る本人を識別するために、当該匿名加工情報を他の情報と照合してはならない。
匿名加工情報と、本人を識別するために元の個人情報と照合はNG。
6 個人情報取扱事業者は、匿名加工情報を作成したときは、当該匿名加工情報の安全管理のために必要かつ適切な措置、当該匿名加工情報の作成その他の取扱いに関する苦情の処理その他の当該匿名加工情報の適正な取扱いを確保するために必要な措置を自ら講じ、かつ、当該措置の内容を公表するよう努めなければならない。
これは、匿名加工を行っている内容を公表する必要がある。
1.3.法律(匿名加工情報の提供、識別行為の禁止、安全管理措置等)を確認
上記は、個人情報取扱事業者でしたが匿名加工情報取扱事業者についても同様に守るべき法律が存在します。基本的には個人情報取扱事業者と同様のことが求められれます。
(匿名加工情報の提供)
第四十四条 匿名加工情報取扱事業者は、匿名加工情報(自ら個人情報を加工して作成したものを除く。以下この節において同じ。)を第三者に提供するときは、個人情報保護委員会規則で定めるところにより、あらかじめ、第三者に提供される匿名加工情報に含まれる個人に関する情報の項目及びその提供の方法について公表するとともに、当該第三者に対して、当該提供に係る情報が匿名加工情報である旨を明示しなければならない。
(識別行為の禁止)
第四十五条 匿名加工情報取扱事業者は、匿名加工情報を取り扱うに当たっては、当該匿名加工情報の作成に用いられた個人情報に係る本人を識別するために、当該個人情報から削除された記述等若しくは個人識別符号若しくは第四十三条第一項若しくは第百十六条第一項(同条第二項において準用する場合を含む。)の規定により行われた加工の方法に関する情報を取得し、又は当該匿名加工情報を他の情報と照合してはならない。
(安全管理措置等)
第四十六条 匿名加工情報取扱事業者は、匿名加工情報の安全管理のために必要かつ適切な措置、匿名加工情報の取扱いに関する苦情の処理その他の匿名加工情報の適正な取扱いを確保するために必要な措置を自ら講じ、かつ、当該措置の内容を公表するよう努めなければならない。
匿名加工取扱事業者も個人情報取扱事業者と同様に、匿名加工情報を第三者提供する場合には、公表の義務があります。
識別行為は禁止されます。そのため加工方法について情報収集したり、他の情報と照合は禁止されます。
苦情処理や取扱のための措置が求められます。また公表も必須です。
2.匿名加工情報が生まれた背景
プライバシー保護データ流通のための匿名化手法には、下記の記述がある。
要約すると、プライバシーの安全性とデータ利活用のバランスを取ることが目的である。
2017年の改正個人情報保護法の全面施行により、匿名加工情報という情報の類型が示された。これはパーソナルデータから特定の個人が識別される要素を排除したデータを、簡易的な手続きで第三者提供可能とする枠組みを認めたものである。
このような、パーソナルデータから個人のプライバシー侵害が発生する要素を排除して利用者に提供する技術として「プライバシー保護データパブリッシング(PPDP:Privacy Preserving Data Publishing)」がある。これはいわゆる、パーソナルデータに匿名化技術を適用した「匿名データ」を流通させる技術であり、「出力プライバシー(Output privacy)」ともよばれる。
PPDPでは、公開するデータの安全性基準と、その利活用の目的に沿った加工をバランスよく成立させることを目的としている。しかし個人のプライバシー侵害が発生する条件とその攻撃者は多様であり、パーソナルデータを安全な形に加工する技術と、その安全性指標は、必ずしも明白ではない。
パーソナルデータをプライバシー侵害が発生する要素を排除するもの
これにより第三者提供が可能になり、データ利活用が進む
プライバシーの安全性とデータ利活用のバランスを取ったもの
匿名データを流通させる技術であり、PPDP(Privacy Preserving Data Publishing)がある。
PPDPは、上述した通り安全性と利活用のバランスを目的にしているが、安全な形に加工する技術とその安全性指標は明確になっていないのが現状である。
2.1. PPDPの攻撃者モデル
データ提供者は、データ主体との契約に基づいて正当にデータ処理しており、信頼できるプレイヤーとして考えるが、データを受領者が信頼できるかは不明であるため、すべてを信頼できないプレイヤーとして定義する。
そのため、PPDPはすべてのデータ受領者に匿名データを提供してもデータ主体の安全が保証されるという、制約条件を伴った匿名化技術により実施される。
3. 匿名加工情報の基本的な手法
匿名加工を行う基本的な手法とそのメリット・デメリットを解説します。初心者でも簡単に始められる方法から、より高度な手法までを網羅しています。
3.1. 加工の手法例
個人情報の保護に関する法律についてのガイドライン(仮名加工情報・匿名加工情報編))(別表2)匿名加工情報の加工に係る手法例(※)によると、下記の手法が整理されています。
項目削除/レコード削除/セル削除
加工対象となる個人情報データベース等に含まれる個人情報の記述等を削除するもの。 例えば、年齢のデータを全ての個人情報から削除すること(項目削除)、特定の個人の情報を全て削除すること(レコード削除)、又は特定の個人の年齢のデータを削除すること(セル削除)。
一般化
加工対象となる情報に含まれる記述等について、上位概念若しくは数値に置き換えること又は数値を四捨五入などして丸めることとするもの。 例えば、購買履歴のデータで「きゅうり」を「野菜」に置き換えること。
トップ(ボトム)コーディング
加工対象となる個人情報データベース等に含まれる数値に対して、特に大きい又は小さい数値をまとめることとするもの。 例えば、年齢に関するデータで、80歳以上の数値データを「80歳以上」というデータにまとめること。
ミクロアグリゲーション
加工対象となる個人情報データベース等を構成する個人情報をグループ化した後、グループの代表的な記述等に置き換えることとするもの。
データ交換(スワップ)
加工対象となる個人情報データベース等を構成する個人情報相互に含まれる記述等を(確率的に)入れ替えることとするもの。
ノイズ(誤差)付加
一定の分布に従った乱数的な数値を付加することにより、他の任意の数値へと置き換えることとするもの。
疑似データ生成
人工的な合成データを作成し、これを加工対象となる個人情報データベース等に含ませることとするもの。
4. k-匿名性とその他の高度な手法
k-匿名性をはじめとする高度な匿名加工手法について、その理論と実践的な進め方を解説します。この章を読むことで、より高度なプライバシー保護を実現する方法について学べます。
4.1. k-匿名性とは
k-匿名性は、データセット内でk人以上が同じ属性を持つようにデータを加工する手法です。具体的には、氏名を削除し、住所・年齢・性別などを一般化します。
4.2. k-匿名性以外のその他手法
l-多様性
l-多様性は、k-匿名性の拡張であり、同一の匿名グループ内で特定の属性が多様な値を持つようにします。
t-接近
t-接近は、匿名グループ内と全体のデータセットで特定の属性の分布が近いようにデータを加工します。
5. 匿名加工の実践的な進め方
上述した通り、匿名加工の理論について説明いたしました。この章では、匿名加工を具体的に実施するためのステップを解説します。
本章では、「事業者が匿名加工情報の具体的な作成を検討するにあたっての参考資料(「匿名加工情報作成マニュアル」)(PDF形式:1,405KB)」を参考に整理しております。
5.1. 匿名加工を行うための前提
匿名加工を進める際に必要な用語を定義します。
識別子
個人データを構成する情報。単体で個人を特定する可能性がある情報。
例)氏名、会員番号※1
※1 個人情報に該当しないが、識別子に該当する場合がある。(アカウントIDや端末ID等)個人識別リスクを鑑みて判断する。
属性
下記の全てに該当する情報
個人データを構成する情報
経時的にデータが積み重ねられることがない
他の属性との組み合わせや外部の情報との照合により、個人を特定する可能性がある。
例)性別、年齢、郵便番号、家族構成等
履歴
下記の全てに該当する情報
個人データを構成する情報
個人の行動の履歴を蓄積
経時的にデータが積み重ねられる情報
一般に単体では個人が特定できない
他の属性との組み合わせや外部の情報との照合により、個人を特定する可能性がある。
例)ウェブの閲覧履歴、購買の履歴等
仮ID
匿名加工情報の作成に当たり、復元することができる規則性を有しない方法によりID等の識別子を外の記述等に置き換えた情報。
履歴と属性を結びつける。

5.2.加工方法の手順
下記の4つの検討プロセスから構成されます。
なお、匿名加工の要求レベルは、個人データを取り扱う事業の内容や利用形態等によって判断されるべきものとのことで、普遍的な基準はないとのこと。ケースバイケースで判断が必要。
ユースケースの明確化
識別子、属性、履歴の仕分け
個人識別等に係るリスクの抽出
個人識別等に係るリスクを踏まえた加工方法の検討
5.2.1. ユースケースの明確化
まずはユースケースを明確にします。下記の事項を確認し整理します。
匿名加工情報の作成者における業務・サービスの概要
匿名加工情報の作成に用いる個人情報データベース等のデータ項目、規模等
個人情報DB等によって識別される個人の人数
データ項目の内容
カテゴリなどの離散値
年齢などの整数値
支出などの連続値
燃費などの実数値
データ項目の内容及び取りうる値の集合、最小値、最大値
匿名加工情報煮含める必要のあるデータ項目、規模(件数)
匿名加工情報の利用目的
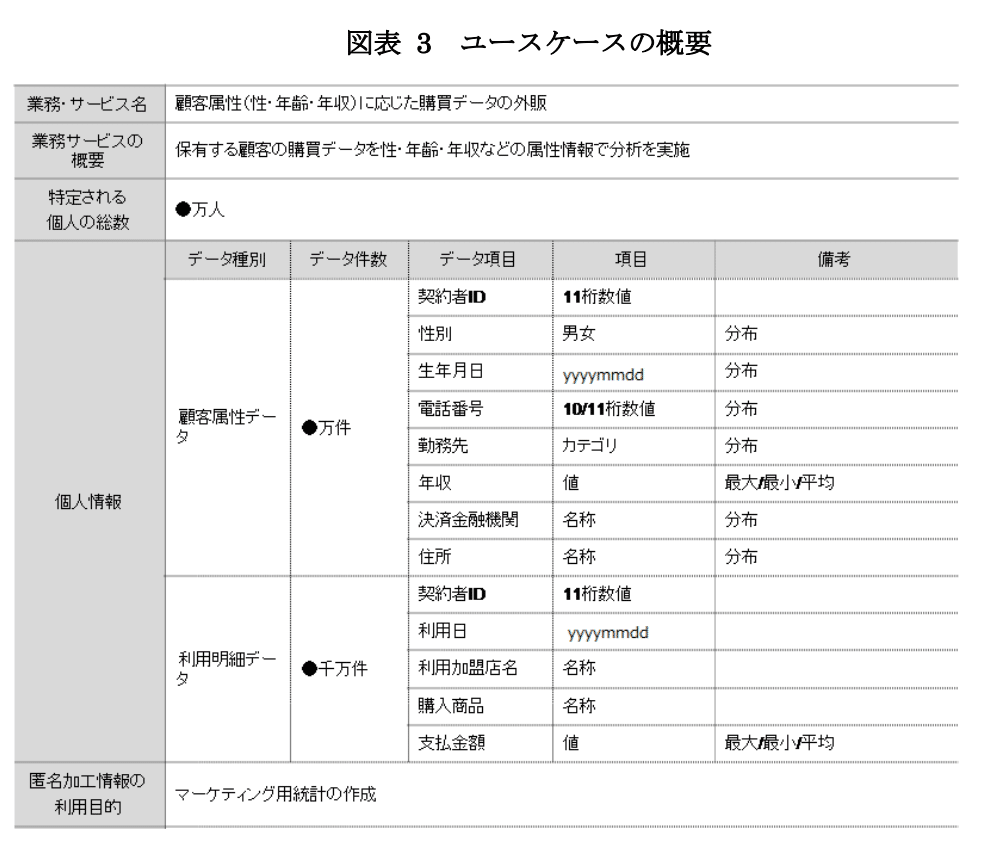
ユースケースを具体的にイメージできるように下記について整理するのが望ましい。
ユースケースの全体イメージ
下記のようにデータの流れと利用者、関連システムに整理します。

取り扱う個人情報DBサンプル
匿名加工前のスキーマと、データサンプルでイメージします。
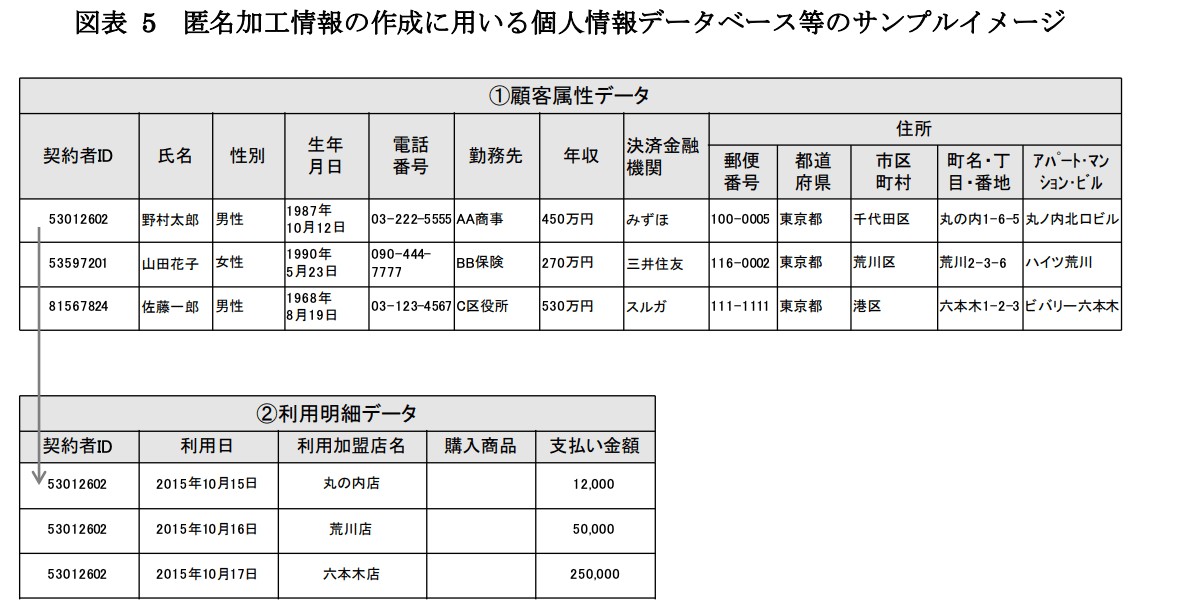
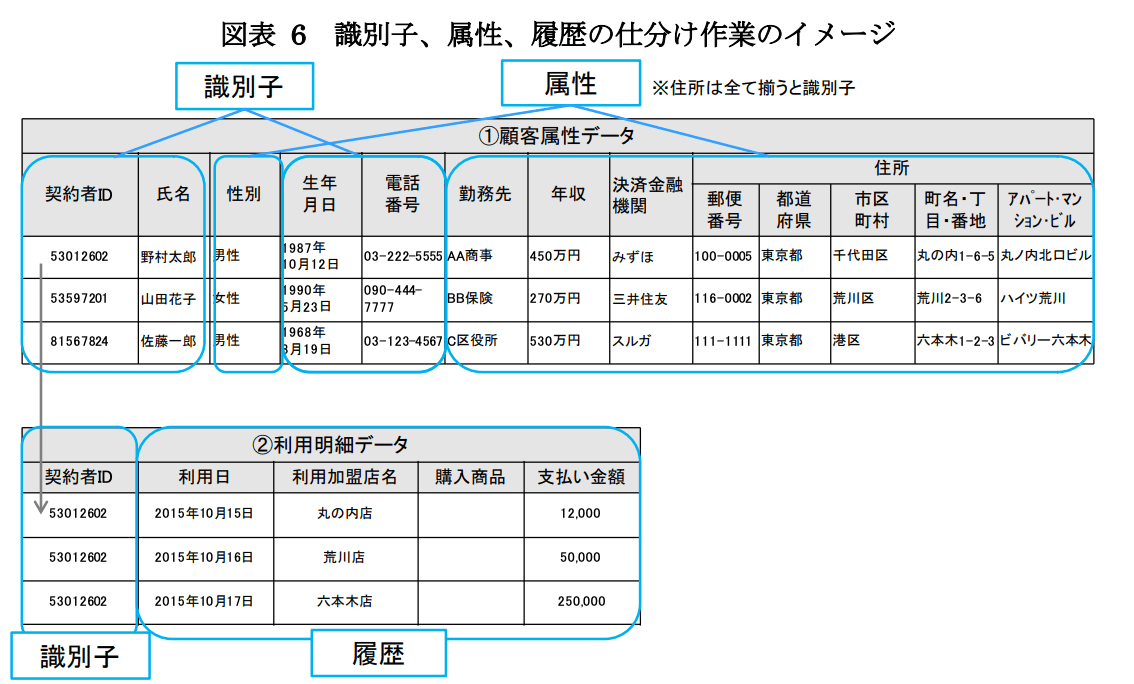
5.2.2.識別子、属性、履歴の仕分け
前プロセスで整理した取り扱う個人情報DB等のサンプルデータにおいて、ケースに応じて必要なデータを抽出して、識別子、属性、履歴に該当するものか仕分けします。
識別子
単体で個人を特定する可能性のある情報を抽出
アカウントID、端末IDなど個人情報に該当しないものでも単体で個人を特定する可能性のある情報は、識別子として仕分けする。
住所は、詳細まで含める場合は、個人を特定する可能性があるため識別子として仕分ける
属性
識別子以外のデータ項目のうち、経時的にデータが積み重ねられることのない情報で、他の属性との組み合わせや、外部情報との照合により、個人を特定する可能性のある情報を抽出する。
住所は、詳細まで含めずに、一定の曖昧さを含めるレベルまで利用する場合は属性として仕分ける
履歴
データ項目のうち、Web閲覧履歴、購買履歴等、個人の行動履歴を蓄積したものを始めとする経時的にデータが積み重ねられる情報で識別子等により属性と結び付けられる情報
一般に属性と組み合わされ、もしくは外部情報との照合がなされない限り個人を特定する可能性のない情報が該当する。
5.2.3.個人識別に係るリスクの抽出
上述したプロセスを経て、個人識別に係るリスクを抽出する。
下記のリスクについて、識別子、属性、履歴の順に抽出と評価を行う。なお、ここでは、1.個人が特定されるリスクに、2と3が含まれる場合もあるが、1が具体化されたものとして別途切り出して評価が行われている。
個人が特定されるリスク
データが他の情報と照合されるリスク
データを用いて本人へアプローチされるリスク
識別子
個人識別リスクが高いもの
原則として削除する。氏名等については評価するまでもなく削除するべき
リスクが認められる場合(識別子)
1. 個人が特定されるリスク
識別子が削除等されてない場合
2. データが他の情報と照合されるリスク
N/A
3. データを用いて本人へアプローチされるリスク
住所等(メールアドレス)の識別子が削除等されてない場合
属性
一般に複数の種類の属性が組み合わされると、個人識別のリスクは高くなる。具体的なユースケースを踏まえて、どの属性とどの属性が組み合われると個人識別リスクが高くなるものかについて評価する。
データセットに対して、属性の値についても評価し、極めて頻度の小さい値がある場合は、個人識別のリスクが高くなる可能性があるものとして抽出する。
他の情報と照合されるリスクは、市販のDBなど、データセットと照合可能な外部情報が存在するか確認する。
例)
住宅地図などの外部情報を用いることにより、住所から切り出した属性と照合される可能性について評価することなどが該当する。
匿名加工を提供する事業者を限定する場合においては、当該事業者が照合可能なデータを有しているかについて評価する。
DMや訪問販売などにより、本人へアプローチされるリスクは、主に位置に関する情報が該当し、自宅や職場の地域が属性を組み合わせることで絞り込まれる場合、リスクとして認識する必要がある。
リスクが認められる場合(属性)
1. 個人が特定されるリスク
複数の種類の属性が組み合わされる場合
極めて頻度の小さい値がある場合
2. データが他の情報と照合されるリスク
照合可能な外部情報が存在する場合(※一般的に入手可能なものを想定)
提供先事業者が照合可能なデータを有している場合
3. データを用いて本人へアプローチされるリスク
自宅や職場等の本人が所在する確率の高い場所が、属性を組み合わせることで絞り込まれる場合
履歴
特異な値や傾向を持つ履歴は、個人識別性が高いものとして特異値に係るリスクとして認識する。
値や傾向が特異であるかは、利用目的やデータの性質、データセットにおける位置づけや割合等を斟酌して個別具体的に判断せざるを得ない。
例えば、非常に高額な商品や希少な商品を購入した場合の購入履歴などが該当する。
一個人に対する長期間のデータ蓄積、または大量のデータ蓄積により、個人の識別性が生じる可能性がある場合、データ規模、期間に係るリスクとして認識する。
履歴を継続的に提供する場合、履歴を照合することで、突合できる場合も考えられるため、履歴の継続的提供を想定するユースケースは、リスクとして認識する。
位置情報に関する情報が個人を識別する可能性がある粒度の場合に、個人が識別されるリスクとして認識する。例えば詳細なGPS情報の履歴を蓄積すると、自宅や職場の場所が識別されるリスクがある。また本人にアプローチされるリスクが生じる。
リスクが認められる場合(属性)
1. 個人が特定されるリスク
特異な値や傾向を有する場合
一個人に対する長期間または大量のデータ蓄積がある場合
位置に関する情報が、個人識別性のある粒度の場合
履歴を継続的に提供する場合
2. データが他の情報と照合されるリスク
履歴を継続的に提供する場合
3. データを用いて本人へアプローチされるリスク
位置に関する情報を含む場合
5.2.4.個人識別に係るリスクを踏まえた加工方法の検討
個人識別に係るリスクを踏まえて、リスク要因を除去するための適切な加工方法を検討する。前プロセスで抽出した個人識別に係るリスクについて、識別子、属性、履歴の順に適切な対処を検討する。
識別子
それ自体を個人データから削除又は福毛することのできる規則性を有しない方法で他の記述等に置き換える。
それだけではリスクを低減できない場合は、識別子に紐づく属性や履歴の加工処理も必要になる。
個人識別に係るリスク
個人が特定されるリスク
データを用いて本人へアプローチされるリスク
加工方法
原則、識別子を削除又は規則性をゆうしない方法により他の記述等に置き換える。
属性に仕分けできるレベルに落とすため、識別子を一部削除
履歴と照合するための仮IDを例外的に用いる場合、仮IDの要件としては下記が挙げられる
仮IDの要件
不可逆
仮IDの生成
Saltを加えてハッシュ化する
仮IDの有効期間
新たに匿名加工を作成する場合は、同一仮IDを使用しない。(仮IDの生成に用いるSaltは一回ごとに切り替える)
属性
データの性質や利用目的等により、識別子の加工だけでは個人識別に係るリスクを十分に低減できない場合がある。そのような場合、当該識別子に紐づく属性の加工も必要である。
個人識別に係るリスク
個人が特定されるリスク
複数の種類の属性が組み合わされる場合
極めて頻度の小さい値がある場合
加工方法
属性同士の組み合わせにより個人識別リスクが高くなるか、組み合わせ数の算定数や、データセットに含まれる個人の数と属性数及び各属性の値の数により評価する。
データセットに対して属性の値がどの程度の分布になっているか評価する。
その上で、置換、一般化、カテゴライズ化、特異値の削除、サンプリング等を行い、属性同士を組み合わせても個人の識別リスクが低減できるレベルまで加工する。このときに、k-匿名性を考慮する。
k-匿名化
データセットに含まれる属性の項目を勘案し、k-匿名性の指標を用いて個人識別に係るリスクを判定する。なお、k値はデータの性質や規模、利用目的により判断する。
判定結果としてk=1の値を有する属性の組み合わせであっても当該属性値の加工を必要としない場合もあり得る。
一般化等
属性に頻度の小さい値のあることが明らかな場合、データの値を広げる一般化、他の値と一体にしてカテゴライズ化を行う。
サンプリング
データセットから無作為にサンプリングを行い、個人識別に係るリスクを低減する。データセットにおける各属性の分布を踏まえてサンプリング比率を調整する。サンプリングによりk−匿名性が損なわれる可能性があるので、適用順序に留意が必要。
データが他の情報と照合されるリスク
照合可能な外部情報が存在する場合
提供先事業者が照合可能なデータを有している場合
加工方法
市販のDBなどの照合可能な外部情報の存在、提供先事業が照合可能なデータを有しているかどうかについて評価する。
例)住宅地図等の外部情報を用いることにより、住所から切り出した属性と照合される可能性について評価する。
上記外部情報等が存在する場合、用意に照合できないレベルまで一般化する。
データを用いて本人へアプローチされるリスク
自宅や職場の地域が属性を組み合わせることで絞り込まれる場合
加工方法
主に詳細な住所や要配慮情報にかかる場所等の位置に関する情報について、当該属性を削除あるいは一般化、グルーピング等を行って、リスクを低減する。
個人識別に係るリスク全般
上述した処理に加えて、履歴レコードを入れ替える(スワッピング)、値にノイズ付加を行うことで、さらに個人の識別リスクを低減することができる
履歴
個人識別に係るリスクを十分に低減できない場合は、識別子や属性の加工に加えて、履歴の加工が必要となる場合もある。
履歴については、一般的に識別子又は属性と組み合わされない限り個人を特定する可能性のない情報が該当するが、履歴であっても必ずしも無加工で利用できるものではないこと十分に留意する必要がある。
個人が特定されるリスク
特異な値や傾向を有する場合
一個人に対する長期間又は大量のデータ蓄積がある場合
加工方法
履歴の記録期間を明らかにし、その期間の長さによりリスクを評価する。
特異値や得意な傾向を持つ履歴の削除(トップ、ボトムコーディング)、置換、一般化、カテゴライズ化等を行う
長期間又は大量のデータであり、かつ、それにより個人が特定されるリスクが高い場合、以下の加工を行い、適宜組み合わせる
(1)リスクに応じて、履歴の期間、蓄積回数の上限を定め、上限を超える場合は、仮IDを更新するなどし、特定の個人が識別できないように加工する。(仮名制御)
(2)日付のランダム化(乱数でずらす)やシフト化(一定期間でずらす)、あるいは日付の間隔のランダム化(順序を保持し、日数の間隔を乱数で一般化する。)(日付・間隔加工)
(3)日付等履歴の削除(トップ、ボトムコーディングを含む)、置き換え、一般化、カテゴライズ化等を行う
(4)さらなるリスクを軽減するため、属性のk-匿名性を確保した上で、仮ID等のスワッピングやノイズを付加する。
個人が特定されるリスク、履歴を継続的に提供する場合、データが他の情報と照合されるリスク、履歴を継続的に提供する場合
加工方法
定期的に仮IDを更新、付替する。
履歴の継続的な提供にあたり、履歴の期間が重ならないように処理する、同じ個人の履歴を連続したデータとして提供しない等により履歴の照合ができないように処理する。
個人が特定されるリスク、位置に関する情報が、個人識別性のある制度の場合、データを用いて本人へアプローチされるリスク、位置に関する情報を含む場合
加工方法
市に関する情報の全部又は一部の削除(起点・終点を落とす等)、一般化(精度を荒くする等)、又はグルーピング等する。
6. 事例集
個人情報保護委員会の匿名加工情報制度についてのページでは、事例集等を公開しています。それらを紹介します。
2020年3月 パーソナルデータの適正な利活用の在り方に関する 実態調査
事例1 生命保険会社による健康データ等の利活用事例
生命保険会社と研究機関の共同研究のためにPPDPを実施した例。

属性データは、k-匿名性をベースとしている。母数が少ないものは削除
保険契約に関する情報では、保険の払込保険料は千円単位に置換、トップコーディングとボトムコーディングにより外れ値を処理
健診データは、身長・体重についてはトップコーディングとボトムコーディングにより外れ値を処理
事例2 医療DB事業者による医療データの利活用事例
医療機関が診療報酬明細書とDPCと呼ばれる診療情報の全国統一データを匿名加工し、医療DB事業者に第三者提供。そこから製薬会社にレポートしている。
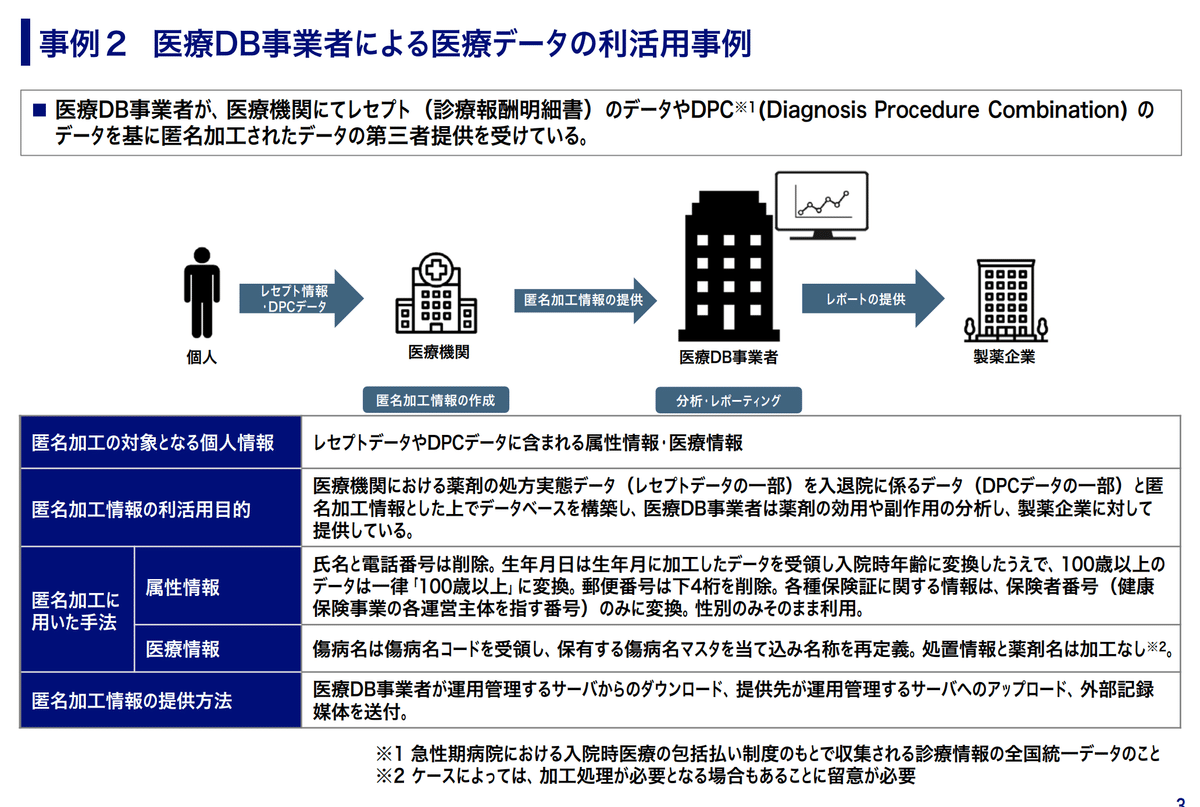
属性情報
氏名と電話番号は削除。
生年月日は生年月まで加工した後、入院時年齢に変換。100歳以上のデータは100歳以上に変換。
郵便番号は下4桁を削除
各種保険証に関する情報は、保険者番号(保健事業の各運営主体を指す)のみに変換
性別はそのまま
医療情報
傷病名は、傷病名コードを受領し、保有する傷病名マスタを照会し名称を再定義
処置情報と薬剤名は加工なし※
※場合によっては加工もあり得る
事例3 製薬企業による医療データの利活用事例
医療DB事業者が作成した匿名加工情報の提供を受けて、データ分析業者に第三者提供したのち、データ分析結果を安全性評価等に使用している

属性情報
氏名と電話番号は削除
生年月日は生年月まで加工した後、入院時年齢に変換。100歳以上のデータは100歳以上に変換。
医療情報
傷病名は、傷病名コードを受領し、保有する傷病名マスタを当て込み名称を再定義
臨床検査結果データは一部の病院から提供されたデータのみ単位を調整。
処置情報と薬剤名は加工なし
事例4 不動産開発事業者によるポイントカードデータの利活用事例
不動産開発事業者が地域限定で発行しているポイントカードの登録情報や利用履歴データを匿名加工し、研究機関に第三者提供している。
研究機関では、ポイントカードの匿名加工情報と、大手SNSにおけるポイントカードが利用されているエリアに関する不特定多数の投稿データを組み合わせて、SNSを用いたキャンペーンによる販促効果の分析を行っている。

属性情報
氏名は削除
生年月日は年齢に変換
住所は都道府県単位に変換
性別、保有ポイント数はそのまま利用
利用履歴
ポイントカードを利用した店舗名は飲食店等の店舗種別に加工
利用日時は時間帯別に加工
商業施設名、購入金額は加工なし
事例5 住宅事業者による電力データの提供事例
住宅事業者が自社の契約住宅から取得したHEMS(Home Energy Management System)データを匿名加工し、データ分析会社等の第三者に販売提供している。
データ分析会社等は、受領データに含まれる消費電力等の電力に関するデータから、消費電力の予測等の分析を行っている。その際に匿名加工情報には含まれない日照量等の統計データと組み合わせて分析することも考えられる。

属性
表示機IDは、ハッシュによる変換で別IDに置換
郵便番号は下4桁を削除
住宅面積は4区分に置換
家族人数は4区分に置換
太陽光発電容量は4区分に置換
分岐ブレーカ名は内部で定めた手順に従い加工
給湯器種別のみそのまま利用
履歴情報
消費電力量と発電量は極めて大きい値の表示器の情報を削除(トップコーディング)
買電量と売電量は加工なし※ 丸め処理、トップコーディングが推奨される事例もあり得るとのこと
結論
匿名加工処理は、プライバシーの安全性とデータ利活用の可能性をバランスを取ったものです。
しかし、匿名加工処理では、一律の安全基準や方法論が定まっていないのが現状で、各社で個別に判断して匿名性を担保しているようです。
参考文献
この記事が気に入ったらサポートをしてみませんか?