ガチ初心者がGoogle Colab+RVCで声質変換できるようになるまで(備忘録)

動かすための最低限を、くどいぐらい丁寧に解説することを目指しました。
んなこた分かってんだよ!というものは適度に飛ばしながらお読みください。
また、この記事を読んで作ったけど規約違反や権利侵害で怒られました!とかには対応できません。自己責任で行ってください。
<更新情報>
2023/4/11 公開
2023/4/25 更新されたセルを解説に追加(全4件)・Colab無料版のWebUI利用制限についての項目を追加
2023/10/04 Colab無料版のWebUI利用制限についての項目に追記
2024/01/01 記事の更新・質問対応終了
追記:Colab無料版のWebUI利用制限について
4/21から、無料版ユーザーにWebUIの使用制限が設けられました。
Google Colab no longer allows remote UI according to its TOS. Theoretically, if you use Stable Diffusion on Colab now, you run the risk of having your account banned.
— 𝑨𝒓𝒕𝒊𝒇𝒊𝒄𝒊𝒂𝒍 𝑮𝒖𝒚 (@artificialguybr) April 20, 2023
Reports from some users here:https://t.co/WX1THlprMv pic.twitter.com/2TD8TSzocN
現時点では、無料版でもWebUIの実行自体は可能、実行したユーザーにBAN措置を取る予定も無いようです。
さらに追記(10/4):9月末頃から実行中にランタイムが切断される現象が頻発するようになりました。Colab無料版でのRVCの使用が完全に制限されたと思われます。
有料版では制限されていないので、安心して扱いたいなら有料版に加入して実行しましょう。
1. Colabの導入
この章では以下の事項を説明します。
Google Colabとは
GitHubからRVCのColab用ノートブックを自分のGoogle Driveにコピー
Google Colabとは
ざっくりめに言うと、ブラウザでPythonを動かせるすごいやつです。
Pythonで機械学習をするには、色々と必要なものがあります(Pythonの環境構築、そこそこ性能の良いGPU…等)。それらを天下のGoogleが無料(機能制限あり)で貸し出してくれるサービスです。便利~。
RVCをColabで導入する
では、早速本題のRVCを導入してみましょう。
RVCは以下のリンク(GitHub)からダウンロードできます。
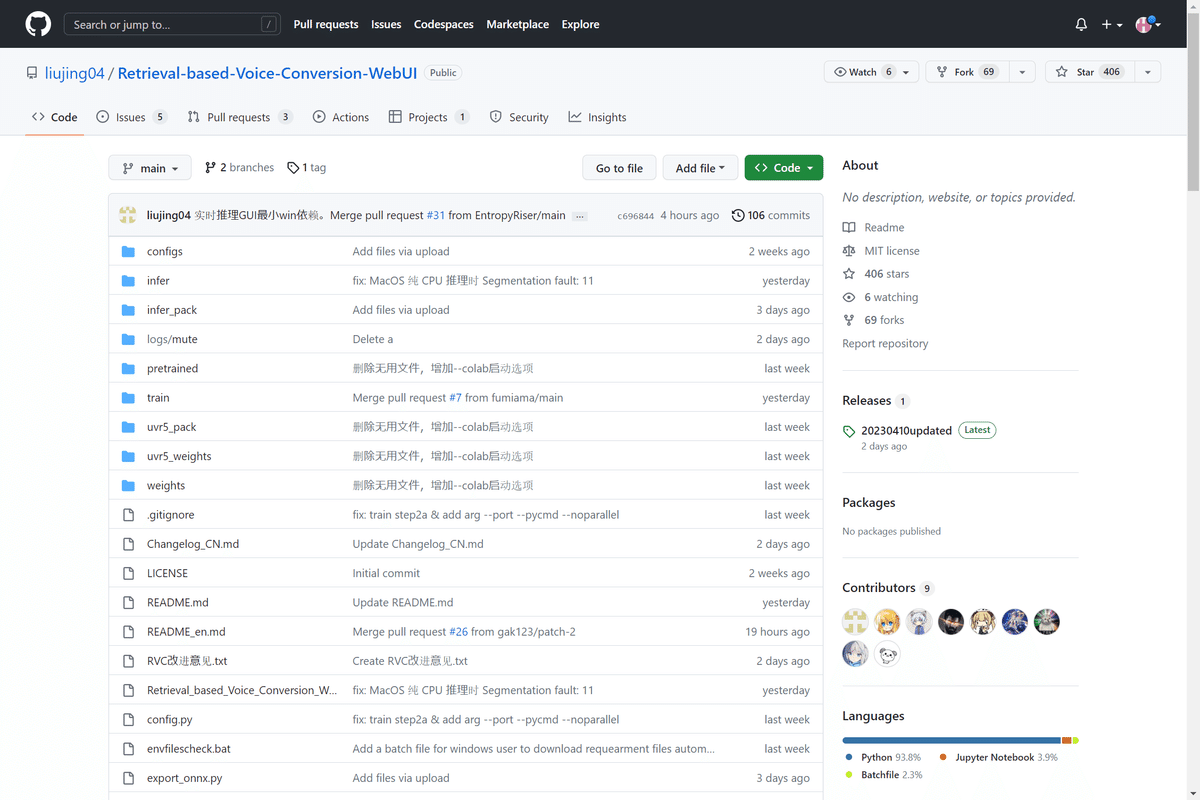
なにやら中国語や英語で書いてありますが、気にせずスクロールし、真ん中ぐらいにある「COLAB」ボタンを探します。
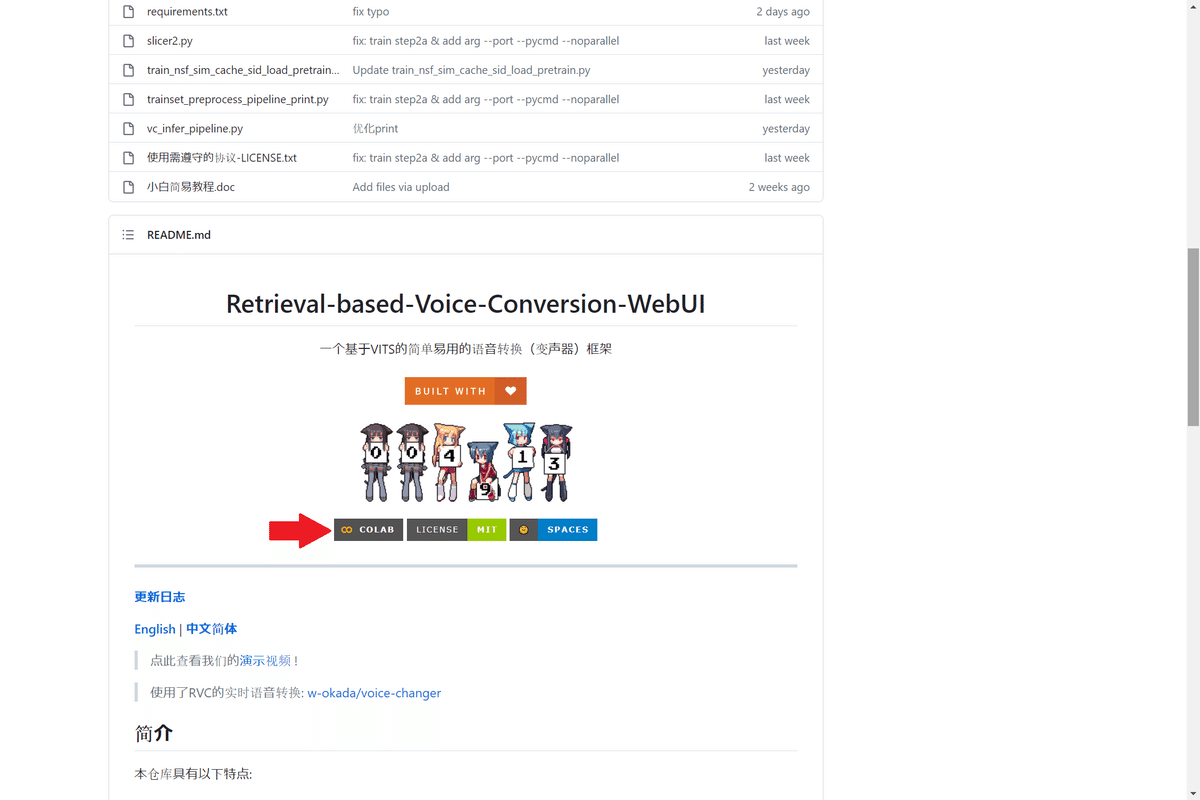
「COLAB」ボタンを押下すると、Google Colabの画面が開きます。
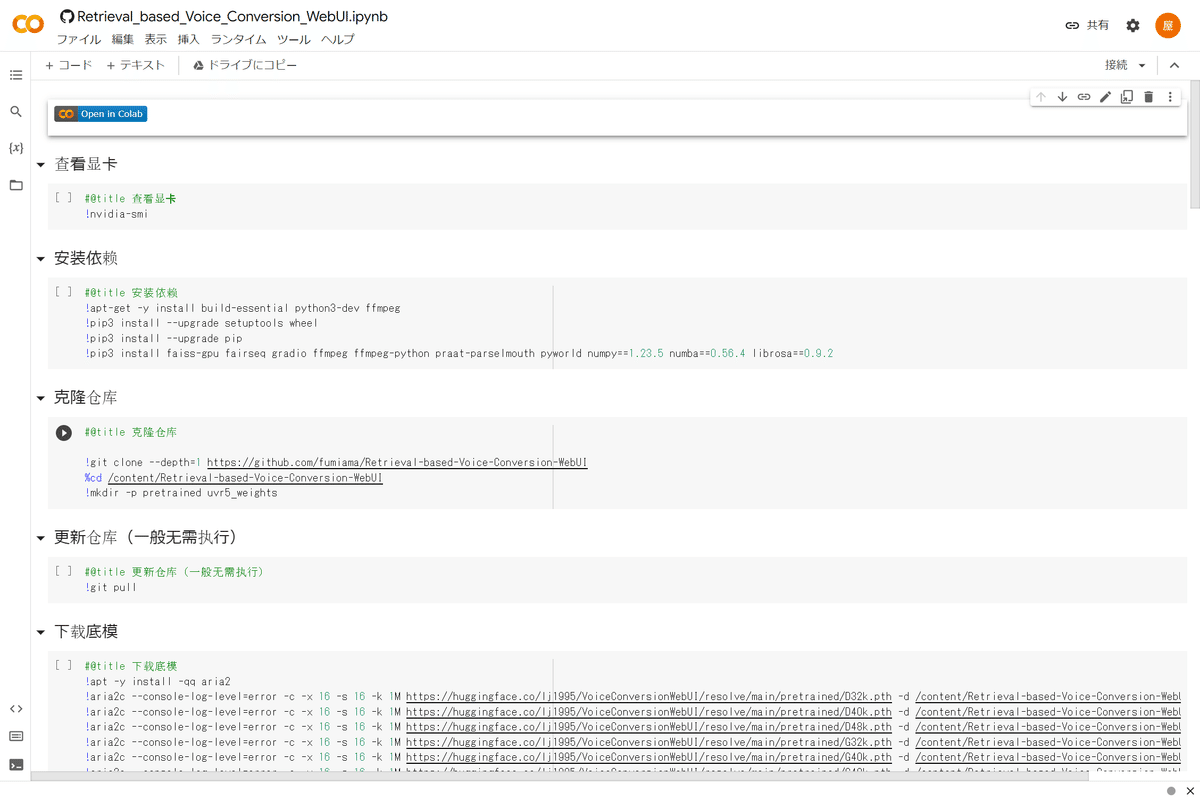
これまた中国語ですが、気にせずツールバーの「ファイル」→「ドライブにコピーを保存」でコピーを作成します。

「ドライブにコピー」からでもコピーを作成できます。
すると新しいタブで、先程と同じような画面が開きます。
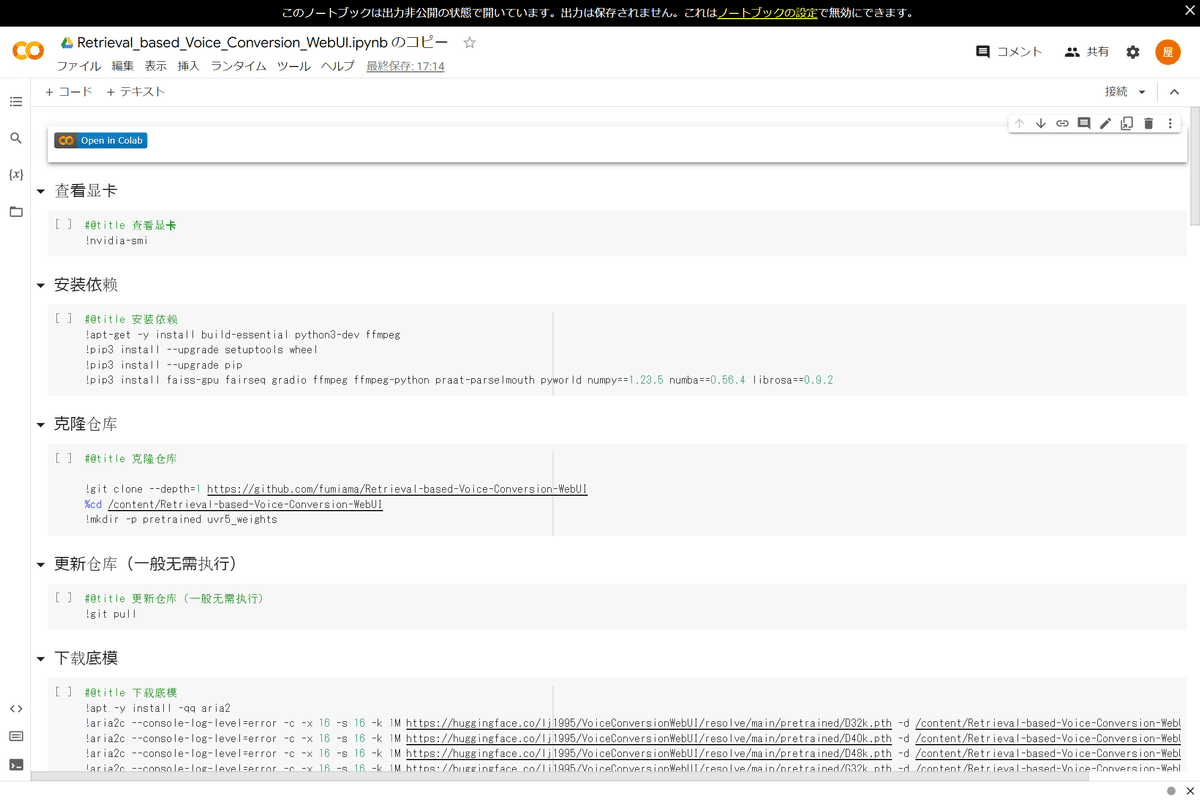
これであなたのGoogle Driveにノートブックがコピーできました。Google Driveを確認すると、「Colab Notebooks」というフォルダの中にノートブックが作成されています。
2. データセットの用意
この章では以下の事項を説明します。
データセットに適した音源とは
音源の用意
用意したデータセットをzip化してGoogle Driveにアップロード
データセットに適した音源とは
RVCで声質変換をするには、(当たり前ですが)変換元となる音源が必要です。例えば、録音した自分の声をずんだもんの声に変換したい、となったら、「録音した自分の声」のwavファイルと、「ずんだもんの声」のwavファイルが必要になります。さらに、より多くの「ずんだもんの声」を学習させれば、変換の精度が上がります(より「ずんだもんの声」に近くなります)。
この大量の「ずんだもんの声」を「データセット」と言います。
RVCでは、以下のような音源がデータセットに適しています。
wavファイルである
発話ごとに区切られている
無音部分やBGMがない(声だけのファイル)
ノイズが少ない
短時間(~10秒ぐらい?)の音源を複数
モノラル音源
(?がついているものは推測 長時間のファイル1個でもできますが、精度は落ちるそうです。)
音源の用意
ここはやり方も資料もたくさんあるのでやんわりと紹介します。それぞれの詳しい使い方は別途検索してください。
- 既存のデータセットを使う
音声合成用のデータセットは配布されているものもあります。
例として、「ITAコーパスマルチモーダルデータベース」を紹介します。
東北イタコ、ずんだもん、四国めたん、九州そらがITAコーパスおよびROHAN4600を読み上げたデータになります。
口の動きの画像データ、口の動きの座標をまとめたデータ、音声データ、音声の境界などが入ったラベルデータがあります。
以下のリンクからTwitterにログインすることでダウンロードできます。
配布されているデータセットを扱う際は、利用規約をよく読み、遵守して使用するようにしましょう。
- 歌やアニメの音源から抽出してデータセットを作成する
BGMやinstを消し、声だけの状態にする
発話ごとに区切り、無音部分やノイズを削除する
以上の手順が必要です。
カラオケ音源がある歌音源の場合
アイマスなど、CDにカラオケ音源がついてくる場合は、歌声りっぷなどの古くから音MADなどで用いられてきたソフトで声だけを抜き出すことができます。コーラスがある場合は音きりすを駆使するとなんとかなります。
カラオケ音源がない歌音源・BGMがあるアニメ音源の場合
カラオケ音源がある歌音源だけど上記の方法で上手くいかなかった場合
ボーカル抽出ソフトを使いましょう。
私がよく使うのはspleeterです。GUIが無かったりpythonやffmpegを導入しなければならなかったりととっつきにくいですが、使えるようになればコマンドを打つだけで声を抽出してくれます。
最新のものでは、UVR(Ultimate Vocal Remover)というものもあります。GPU必須ですが、かなり精度良く声を抽出します。
声だけの状態の音源が用意できたら、発話ごとに区切り、無音部分を削除します。普段使っているDAWソフトがあるならそれを使いましょう。なんぞそれという方はAudacityやReaperなどを使えばいいと思います。
それぞれwavファイルで一つのフォルダにまとめて出力します。
よく分からないよ~;;という場合
まずは上記で紹介したITAコーパスを使ってみましょう。学習はすぐに終わるので、一度試してみることも大切です。以降の手順が上手く行ったら、ITAコーパスのwavファイルはどうなっているのか参考にしながら作ります。
用意したデータセットをGoogle Driveにアップロード
作成した音源ファイルを1つのフォルダにまとめます。
※ファイル名やフォルダ名に「スペース」が入っていると、実行時にエラーが発生します。スペースは入れずに作成してください。(アンダーバー「_」やハイフン「-」で代用します)※
まとめたフォルダを選択して、ツールバーから「共有」を選択し、出てきた「Zip」ボタンを押下し、zipファイルを作成します。

(zipファイル>wavが入ったフォルダ>wavファイルという構成になっていればOKです。)
ブラウザでGoogle Driveを開き、マイドライブに作成したzipファイルをD&Dして、Google Driveにアップロードします。
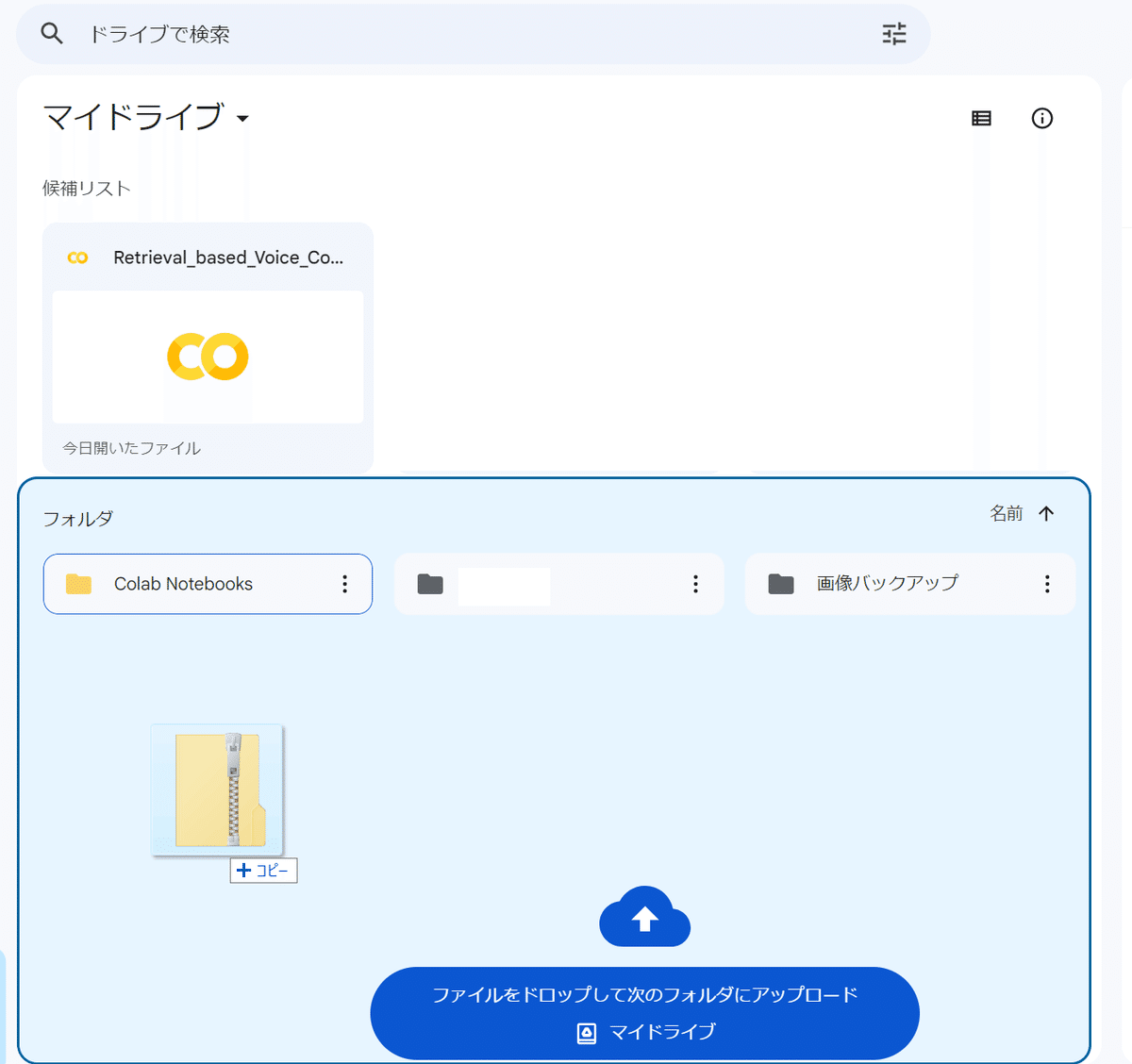
以上でデータセットの用意は完了です。お疲れ様でした。
3. ColabでWebUIを起動
この章では以下の事項を説明します。
Colabの基本操作
ColabでRVCのWebUIを起動する(RVCのアップデートも)
WebUIを起動する
1で作成したノートブックのコピーを開いてください(タブを閉じてしまった場合は、Google Driveの「Colab Notebooks」フォルダから開きます)。
まずは一番上のセル(コードが書かれている枠)を実行してみましょう。
セル左上の[ ]をクリックすることで、そのセルを実行します。
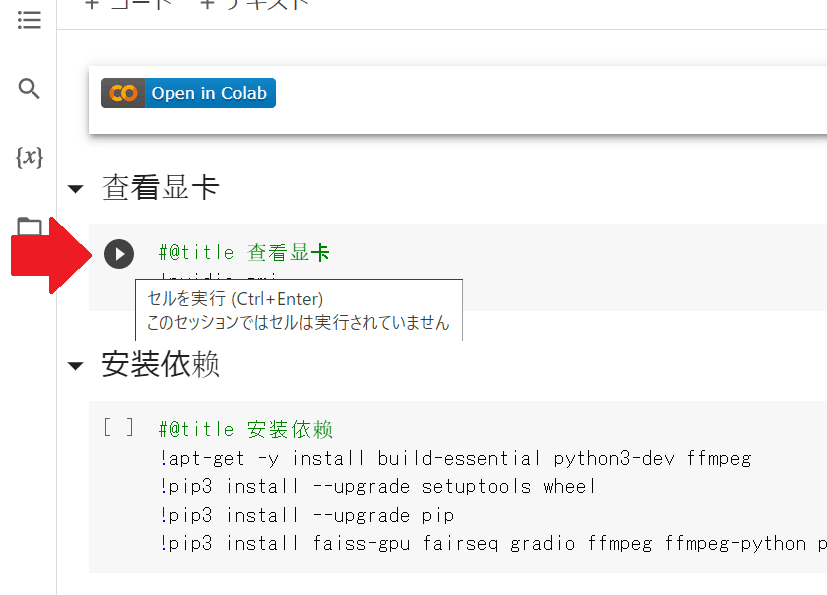
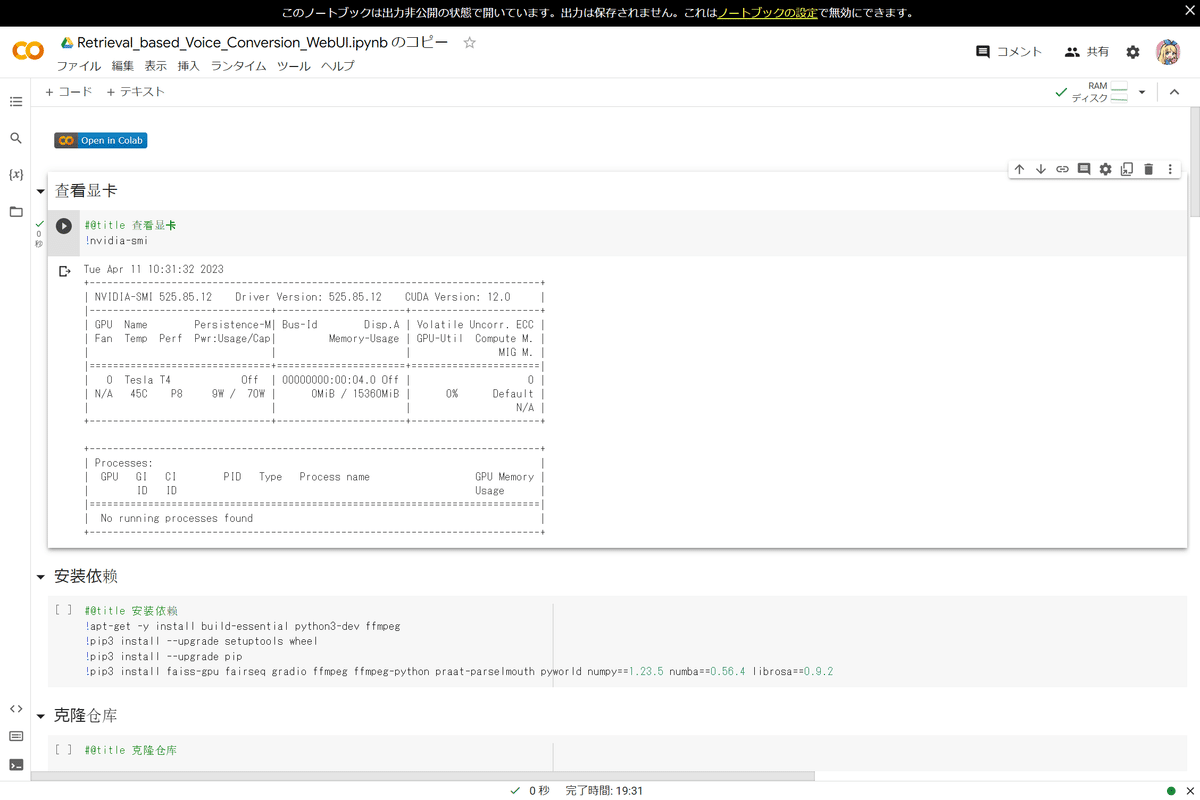
表を見ると、「Tesla T4」と書かれています。現在はこのGPUに接続されているようです。有料版のColabを使うと、性能の良いGPUが優先して選ばれるようです(無料版でも、運が良ければ良いやつに当たります)。
このようにセルを一つずつ実行していきます。次のセルも実行してみましょう。以下に実行するセルのタイトルと訳文を示します。
安装依赖(依存関係のインストール)
克隆仓库(リポジトリのクローン)
安装aria2(aria2のインストール)
下载底模(カウンターをダウンロード)
下载人声分离模型(音声分離モデルをダウンロード)
下载hubert_base(hubert_baseをダウンロード)
挂载谷歌云盘(GDriveをマウント)
実行すると、何やらダウンロード・インストールが始まります。

最後のセルを実行すると、ポップアップが出ます。

これはColab内でドライブのファイルにアクセスするために必要な許可です。「Googleドライブに接続」をクリックし、Googleアカウントにログインして、アクセスを許可してください。
実行が完了すると、左のファイルタブに「drive」フォルダが追加されます。フォルダ名の左にある三角マークをクリックし、中身のフォルダを開いていくと、「MyDrive」の中に用意したデータセットのzipファイルがあります。
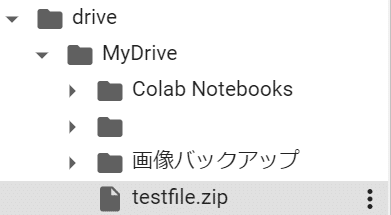
zipファイルにカーソルを合わせて、左に出てきた「︙」をクリックし、「パスをコピー」を選択してください。
クリップボードにこのzipファイルの場所がコピーされます。
コピーしたパスを「从谷歌云盘加载打包好的数据集到/content/dataset」のテキストボックスにペーストします。

では、いよいよ最後のセルを実行しましょう。実行するセルと訳文を以下に示します。
从谷歌云盘加载打包好的数据集到/content/dataset(データセットを/content/datasetに読み込む)
启动web(WebUIの起動)
実行すると、ログにURLが出ます。
「Running on public URL:」の隣にある長いURLをクリックし、WebUIを開きます。


これでついに、RVCを使う準備がすべて整いました!
4. 学習と推論
この章では以下の事項を説明します。
WebUIで学習する(声質変換モデルを作成する)
WebUIで推論する(声質変換を行う)
RVCを用いて学習する
WebUIの「训练」タブを開きます。

触るのは画像の赤枠部分です。それぞれ解説します。
输入实验名(モデル名):分かりやすい名前をつけます。
目标采样率(目標サンプリングレート):サンプリングレートを決めます。迷ったら40kで良いです。
模型是否带音高指导(唱歌一定要,语音可以不要)(モデルにはピッチガイドが付属しているか(歌唱は必要、音声は不要)):基本的には是の方が良いと思います。喋ってる音声に変換したいなら否でもできます。
输入训练文件夹路径(トレーニングパスを入力):データセットのパスを入力します。ドライブにあるzipファイルではなく、/content/dataset内にある解凍されたフォルダのパスを入力します(「/content/dataset/データセットフォルダの名前」)。
以上が設定できたら、下の「一键训练」ボタン(大きいボタンの一番左)を押下します。
しばらく待って、隣のログに「全流程结束!」と表示されたら学習完了です。
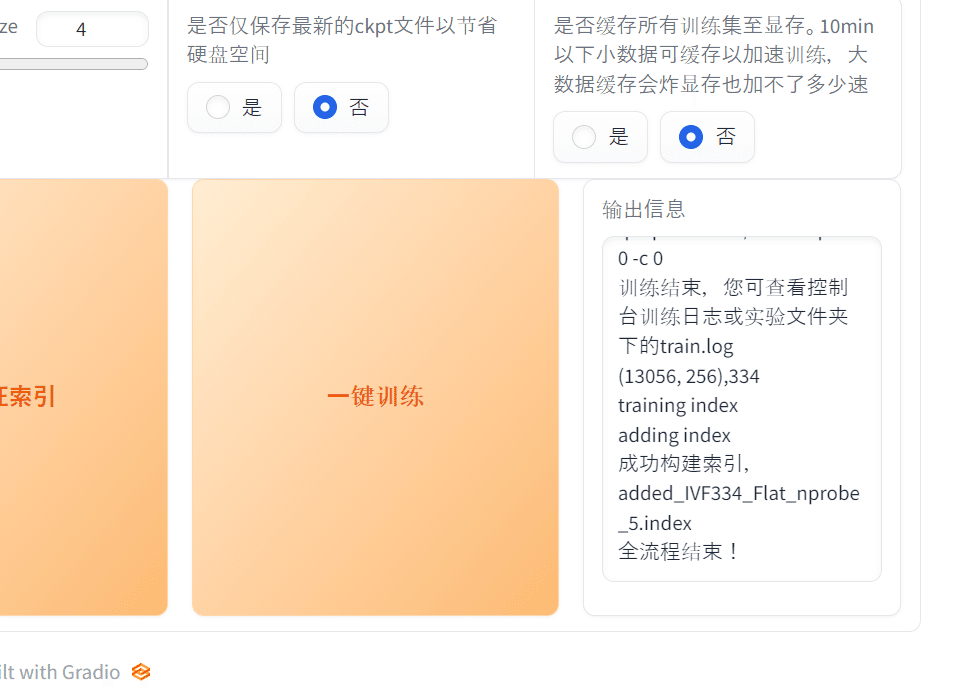
さらに、インデックスファイルを作成します。
すぐ隣にある「训练特征索引」を押下します。ログに「成功构建索引」と表示されたら完了です。

以上で学習は完了しました。
RVCを用いて推論する
まずは変換前の音源を用意します。
wavファイルのままGoogle Driveにアップロードし、Colabでパスをコピーします。
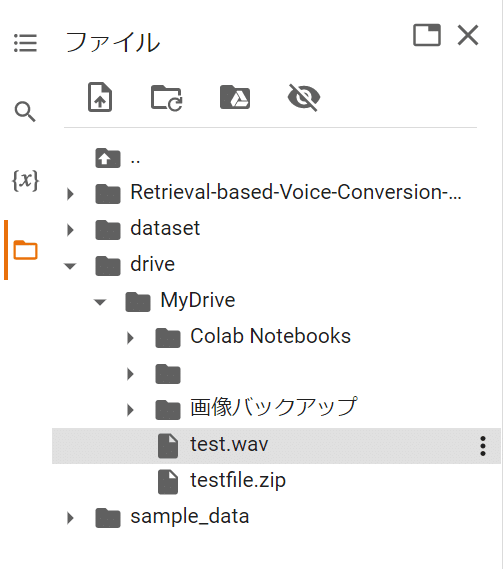
WebUIの「模型推理」タブを開き、「刷新音色列表」ボタンを押下します。

触るのは画像の赤枠部分です。それぞれ解説します。
推理音色:モデルを選択します。
输入待处理音频文件路径(默认是正确格式示例)(処理する音源ファイルのパスを入力します(デフォルトは正しいフォーマットの例)):Colabでコピーした変換前の音源のパスをペーストします。
特征检索库文件路径(インデックスファイルのパス):ColabでRetrieval-based-Voice-Conversion-WebUI>logs>モデル名のフォルダの中にある、「added_IVFXXX_Flat_nprobe_5.index」のパスをコピペします(「XXX」は数字)。
特征文件路径(特性ファイルパス):上と同じフォルダにある「total_fea.npy」のパスをコピペします。
检索特征占比(インデックスの割合):大きいとモデルの声に近くなる代わり、(吐息なども表現してくれる分)滑舌が悪くなります。お好み。
以上が設定できたら、右の「转换」ボタンを押下します。

少し待つと音声が出力されます。これで声質変換完了です!お疲れ様でした。
なんか上手く行かないよ~;;
WebUIの問題で上手く行かない場合があるようです。再読み込みするとエラーが解消される時があります。
また、WebUIが開いて直ぐに操作すると上手く行かないことがあります。一呼吸置いて操作すると、動作が改善する場合があります。
5. おまけ
RVCが使いやすくなる(日本語化など)Tampermonkeyスクリプトを作成してくださっている方がいます。
RVCのWebUIを日本語ローカライズするTampermonkeyスクリプトを作りましたhttps://t.co/kGvVVmwZB6
— hetima (@hetima) April 10, 2023
ChromeにTampermonkeyをインストールし、GitHubからスクリプトをインストールします。
RVC含むAI合成音声について情報交換できるDiscord鯖を作ってくださった方がいます。
AI音声についてdiscordに日本語で情報交換できる場所を作りました。
— にこら@AITuber💙Nicola AIvtuber🇯🇵 (@NicolaJPN) April 5, 2023
so-vits-svc、RVC、リアルタイムボイスチェンジャーその他AI合成音声の情報共有、作品公開チャンネルもあります。
他サーバーで先日荒らし事件が発生したみたいなので、参加したい方はこちらのDMまでご連絡下さい。
#sovitssvc #RVC
有識者の方々のお話を聞くことができます。最新情報もキャッチできます。すごく勉強になります。いつもありがとうございます。
以上です。ありがとうございました。何かあればTwitter(@zesei_)にお知らせください。頑張って対応します。有料化・日本語の情報増加によりそろそろ需要もあんまり無いかな? となったので、勝手ながら記事の更新と質問対応を終了させて頂きます。お付き合いいただきありがとうございました!
この記事が気に入ったらサポートをしてみませんか?