Amazon Lookout for Visionを試してみた

動機について
実現要望として一枚の画像から複数の不良箇所を判断したいというリクエストをいただいた。そのため、Amazon Lookout for Visionを用い何処まで検証できるのか試してみることにした
Amazon Lookout for Visionとは
まずは公式の説明をみてみる
コンピュータビジョンを利用して、製造された製品の欠陥を大規模に発見する機械学習サービスです
要はAmazon Lookout for Visionを使うと、今まで手作業で行なっていた不良箇所の発見を機械学習(Machine Learning)を通じて自動で行なってくれるというもの
ユースケースについて
部品の損傷を検出
欠落しているコンポーネントの特定
プロセスの問題を明らかにする
ワークショップを通じてLookout for Visionの操作手順を掴む
バケットの作成をS3コンソールから行う(手順は割愛する)

AWS CLIもこの先使うかもしれないので、Configureが設定されているか
S3 コマンドを打って確認しておく

ワークショップの通り進めるため、上記で作成したバケット配下にサブオブジェクトの作成をboto3ライブラリで行う
$ pip install boto3import sys
import boto3
test_preffix = 'test/'
train_preffix = 'train/'
bucket_name = 'lfv-tutorial-bucket'
s3 = boto3.client('s3')
for idx, v in enumerate(sys.argv):
if not idx == 0:
result_train = s3.list_objects(Bucket=bucket_name,Prefix=train_preffix + sys.argv[idx])
if not "Contents" in result_train:
s3.put_object(Bucket=bucket_name, Key=train_preffix + sys.argv[idx])
result_test = s3.list_objects(Bucket=bucket_name,Prefix=test_preffix + sys.argv[idx])
if not "Contents" in result_test:
s3.put_object(Bucket=bucket_name, Key=test_preffix + sys.argv[idx])コマンドラインに作成対象のサブオブジェクト名を渡してプログラムを実行する
$ python3 make_tutorial_obujects.py normal anomalyサブオブジェクトが作成されていることをS3コンソールから確認する


作成が無事行えていることを確認したので、次のステップへ進む
モデル作成に必要なデータを公式のgithubからS3バケットにコピーする
$ git clone https://github.com/aws-samples/amazon-lookout-for-vision.git
cd amazon-lookout-for-visionlookout for visionのプロジェクト作成をLookout for Visionのコンソールから行う。
新規プロジェクト作成時にバケット作成を促されるが、このバケットはLookout for Visionプロジェクト(lookoutforvision-demo)を格納するためのバケットである

モデルの素材にラベルを貼る
手順通り、あらかじめs3にあらかじめアップロードした正常、異常の画像データをもとにlookout for visionのコンソール上でモデルを作成する
モデル作成の過程に至り、本来であればラベルを作業が存在するがLookout for Visionのコンソールではその作業も行ってくれるため、MLの知識がない私でもスムーズにモデル作成まで行うことができた

教師あり学習モデルの作成を行う
モデルの精度がかなり高く、これだけでもLookout for Visionを使うメリットはありそうだと感じた

もう少し詳しくモデルのステータスをみてみる
トレーニングには40分弱費やしたそうだが、それにしてもすごい精度

学習モデルに検証データを与えて評価する
ワークショップの手順に習うため、検証する際に使用するイメージは circuitboard/extra_images/extra_imagesの1~5とする

全ての検証画像に対して、異常(Anormally)と推論できるか、Lookout for Visionのトライアル検出機能を使って推論してみる

20%の確率で異常を正常と捉えてしまったが、比較的精度は高そう
肝心の複数の欠陥箇所をオブジェクトとして取得できるかについてだが、コンソールからではそもそも、JSONレスポンス形式のPredictionは得られなかったので、次はコードベース(Python SDK)で検証を進めてみる
Python SDKからLookout for Visionを操作してみる
SageMakerのNotebookインスタンスを作成する

Notebookインスタンスの設定を行う
ここで留意すべき点はIAMロールの割り当てを行う必要があるということである。今回は新規ロールを作成し、その後にワークショップで指定されているインラインポリシーを追加する方法をとる

新規ロールに切り替えた瞬間onChangeアクションが発生して画面が切り替わってしまうため
勿論、既存のIAMロールを割り当てることができるので、Lookout for Visionのフルアクセス権限が付与されているインラインポリシーが設定されている場合は既存のIAMロールを割り当てるだけで問題ない
IAMロールの新規作成画面


作成した上記のIAMロールのインラインポリシーにLookout for Visionのフルアクセス権限を与える

ワークショップで指定されている以下のインラインポリシーに置き換える
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lookoutvision:*"
],
"Resource": "*"
}
]
}アタッチした結果、LookoutVisionのフルアクセス権限が付与されていることをコンソールから確認する

NoteBookを開く
どうやら、Jyupter NoteBookと Jyupter Labの2種類から選択できるようだ
今回はSDKを試すだけなので、Jyupter NoteBookを選択した
Jyupter NoteBookと Jyupter Labの違いについてはこちらの記事でわかりやすく解説してくれている
SageMakerのコンソールからJupyter Notebookを開く

馴染みのあるプロジェクトリスト画面が表示された。

ここであることに思いついた
ワークショップでJyupter Notebookを推奨しているということはPython SDKを用いてAmazon Lookout for Visionを操作するサンプルリポジトリがあるのではないかと考えた。
予想通り、ドキュメントを読み進めてみると、example notebook という形でサンプルのNotebookプロジェクトが存在した 。
早速ローカルにクローンしてNotebookで開いてみることにした
$ git clone https://github.com/awslabs/amazon-lookout-for-vision-python-sdk.git │
Cloning into 'amazon-lookout-for-vision-python-sdk'... │
remote: Enumerating objects: 87, done. │
remote: Counting objects: 100% (87/87), done. │
remote: Compressing objects: 100% (62/62), done. │
remote: Total 87 (delta 44), reused 65 (delta 24), pack-reused 0 │
Receiving objects: 100% (87/87), 56.28 KiB | 1.41 MiB/s, done. │
Resolving deltas: 100% (44/44), done.プロジェクトのアップロードを行う
見過ごしてしまいそうなところにあるuploadボタンを押下

対象となるPython SDKのサンプルプロジェクトを選択し、アップロードする

Python SDKを使って、モデルの作成から推論まで行う手順が事細かく記述されているノートが表示された

今回はSDKからモデルをもとにして検証画像を推論する最短フローで進めるために手順を整理した
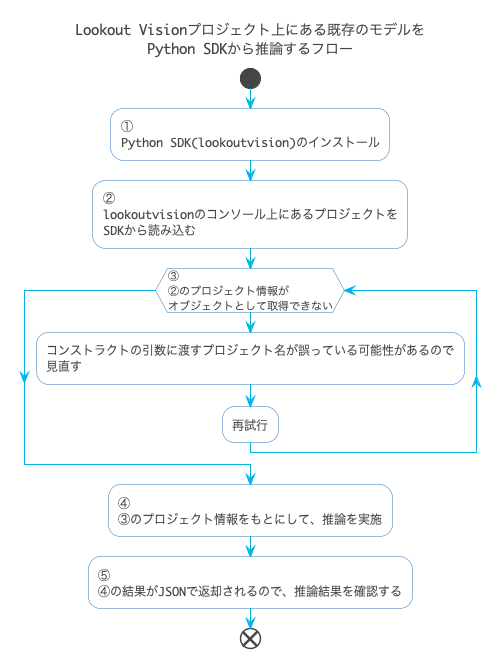
① Python SDK(lookoutvision)のインストール
Notebook上にSDKのインストールを行うため、pipの前に!を付与してあげる
!pip install lookoutvision② Lookout for Visionのコンソール上にあるプロジェクトをSDKから読み込む
from lookoutvision.lookoutvision import LookoutForVision
# コンソール上のプロジェクトを指定
project_name = 'lookoutforvision-demo'
l4v = LookoutForVision(project_name=project_name)
# プロジェクトのオブジェクトIdが表示されることを確認
print(project_name)③プロジェクトが取得できるか確認する

④ プロジェクト情報をもとに推論実施
今回はS3上にある画像を使って検証はせず、ローカル(SageMaker Notebook)上の画像を使って推論を行う方法を取ることにした
使用するメソッド
def _batch_predict_local(self, local_path, model_version=None, content_type="image/jpeg")Notebook上に検証用の画像を含む圧縮済みのフォルダ(zip)を配置する

アップロードしたフォルダ(res)をプログラム から展開する
import zipfile as zf
files = zf.ZipFile("res.zip", 'r')
files.extractall()
files.close()resフォルダが展開されたことをNotebookで確認する

resフォルダの中に検証用のファイルが存在することも確認する

read_sample.txtを使って相対パスでファイルが読み込めるか先に確認する

batch_predict_localメソッドでres配下にある検証用の画像が推論できるか検証する
l4v._batch_predict_local(
# 検証用のディレクトリを指定
local_path='./res',
# プロジェクトの中で作成したモデルの番号を指定する(一つ目のモデルだと1からはじまる)
model_version="1",
content_type="image/jpeg")Errorとなった
原因は恐らくSageMaker Notebook上に自動で生成される.ipynb_checkpointsディレクトリの存在
predictメソッド内の処理を見ると、ディレクトリからファイルリストを取得し、1件ずつ展開する際にディレクトリ(.ipynb_checkpoints)をみてしまってエラーになる。
---------------------------------------------------------------------------
IsADirectoryError Traceback (most recent call last)
Cell In[10], line 1
----> 1 l4v._batch_predict_local(
2 local_path='./res',
3 model_version="1",
4 content_type="image/jpeg")
File ~/anaconda3/envs/python3/lib/python3.10/site-packages/lookoutvision/lookoutvision.py:506, in LookoutForVision._batch_predict_local(self, local_path, model_version, content_type)
504 filename = "{}/{}".format(local_path, file)
505 # ...set obj to bytearray using local image...
--> 506 with open(filename, "rb") as image:
507 f = image.read()
508 obj = bytearray(f)
IsADirectoryError: [Errno 21] Is a directory: './res/.ipynb_checkpoints'resディレクトリ配下に.ipynb_checkpointsを作らないようにできれば解決はできそうだが、現在のNotebook環境はSageMaker上にあるため、少し考える必要がありそう。
と取り敢えず、いったんディレクトリを指定する方法から離れることにして、特定のファイルを指定して推論できるメソッドがないか公式のコードから調べた
ありました ありました
引数に検証したい画像のパスを渡すだけでOKなやつ
def predict(self, model_version=None, local_file="", bucket="", key="", content_type="image/jpeg"):
"""Predict using your Amazon Lookout for Vision model.
You can either predict from S3 object or local images.
Args:
model_version (str): The model version to deploy.
local_file (str): Path to local image.
bucket (str): S3 bucket name.
key (str): Object in S3 bucket.
content_type (str): Either "image/jpeg" or "image/png".
Returns:
json: an object with results of prediction
"""
# If no paths are set return warning:
if local_file == "" and bucket == "" and key == "":
print("Warning: either local_file OR bucket & key need to be present!")
return {"Source": {"Type": "warning"}, "IsAnomalous": None, "Confidence": -1.0}
# If paths for local file AND S3 bucket are set return another warning:
if local_file != "" and bucket != "" and key != "":
print("Warning: either local_file OR bucket & key need to be present!")
return {"Source": {"Type": "warning"}, "IsAnomalous": None, "Confidence": -1.0}
# If method is used properly then...
obj = None
if local_file != "":
# ...set obj to bytearray using local image...
try:
with open(local_file, "rb") as image:
f = image.read()
obj = bytearray(f)
except IsADirectoryError:
print("Warning: you specified a directory, instead of a single file path")
print("Maybe you would like to try '_batch_predict_local' or 'batch_predict_s3' method!")
return
elif bucket != "" and key != "":
# ...or a byte object by pulling from S3
obj = boto3.client("s3").get_object(Bucket=bucket, Key=key)["Body"].read()
else:
# If file not found:
print("Warning: No file found!")
return {"Source": {"Type": "warning"}, "IsAnomalous": None, "Confidence": -1.0}
# Predict using your model:
result = self.lv.detect_anomalies(
ProjectName=self.project_name,
ModelVersion=self.model_version if model_version is None else model_version,
Body=obj,
ContentType=content_type,
)["DetectAnomalyResult"]
return result因みにモデルを変えたい場合は?と思った方もいらっしゃると思うのでサラサラって公式のコードを読んできました
結果としてはモデルバージョンがキーワード引数(model_version)として与えられていない場合は、selfの値を使うという仕様になっていた
これがコンストラクタ
def __init__(self, project_name, model_version="1"):
"""Build, train and deploy Amazon Lookout for Vision models.
Technical documentation on how Amazon Lookout for Vision works can be
found at: https://aws.amazon.com/lookout-for-vision/
Args:
project_name (str): Name of the Amazon Lookout for Vision project to interact with.
model_version (str): The (initial) model version.
"""
# super(LookoutForVision, self).__init__()
self.project_name = project_name
self.lv = boto3.client("lookoutvision")
self.s3 = boto3.client("s3")
self.model_version = model_version
self.describe_project()検証ファイルを直接して推論を実施してみる
l4v.predict(local_file="./res/extra_images-anomaly_2.jpg")またまたErrorが発生
---------------------------------------------------------------------------
ConflictException Traceback (most recent call last)
Cell In[14], line 1
----> 1 l4v.predict(local_file="./res/extra_images-anomaly_2.jpg")
File ~/anaconda3/envs/python3/lib/python3.10/site-packages/lookoutvision/lookoutvision.py:480, in LookoutForVision.predict(self, model_version, local_file, bucket, key, content_type)
478 return {"Source": {"Type": "warning"}, "IsAnomalous": None, "Confidence": -1.0}
479 # Predict using your model:
--> 480 result = self.lv.detect_anomalies(
481 ProjectName=self.project_name,
482 ModelVersion=self.model_version if model_version is None else model_version,
483 Body=obj,
484 ContentType=content_type,
485 )["DetectAnomalyResult"]
486 return result
File ~/anaconda3/envs/python3/lib/python3.10/site-packages/botocore/client.py:535, in ClientCreator._create_api_method.<locals>._api_call(self, *args, **kwargs)
531 raise TypeError(
532 f"{py_operation_name}() only accepts keyword arguments."
533 )
534 # The "self" in this scope is referring to the BaseClient.
--> 535 return self._make_api_call(operation_name, kwargs)
File ~/anaconda3/envs/python3/lib/python3.10/site-packages/botocore/client.py:980, in BaseClient._make_api_call(self, operation_name, api_params)
978 error_code = parsed_response.get("Error", {}).get("Code")
979 error_class = self.exceptions.from_code(error_code)
--> 980 raise error_class(parsed_response, operation_name)
981 else:
982 return parsed_response
ConflictException: An error occurred (ConflictException) when calling the DetectAnomalies operation: Detect cannot be performed when the resource is in TRAINED. The resource must be in HOSTED to perform this action
スタックトレースに沿って、一番したからエラーメッセージを見ていくことにした The resource must be in HOSTED to perform this action
このメッセージより モデルのステータスをHOSTEDにする必要があることがわかった
sh ConflictException: An error occurred (ConflictException) when calling the DetectAnomalies operation: Detect cannot be performed when the resource is in TRAINED. The resource must be in HOSTED to perform this actionそのため、現在のモデルのステータスを確認することにした
結果としてTRAINEDであり、StatusMessageをみると、
The model is ready for hosting ということであったので、Hostingにする準備ができているということがわかった。

SDKからモデルをHosting状態にする
l4v.deploy(
model_version="1",
wait=True)lookoutvisionのコンソールを見ながら「ホスティングを開始中」になるまでしばらく待つ

SDK側で再度ステータスを確認

Statusが「Hosted」になっていることを確認し、再度predicitを実施

無事推論に成功
結論
不良箇所の座標位置などを配列で返していないため、SDKでもAnomalyかnormalyだけしか判定できないことが確認できた
この記事が気に入ったらサポートをしてみませんか?