
Vit(VisionTransformer)について理解を深める第二部[EncoderからMLPヘッドについて理解する]

1.第一部のおさらい

TransfomerからEncoderのみを活用したとて分かりやすいモデルであるVisionTransfomer(以後Vitとする)ですが、前回までは主にパッチとEmmbedingについて詳しく説明したと思います。
今回説明するのは、上の図であるTransfomer Encoderの部分からMLP HEADです。
Encoder、そしてMulti-Head-Self-AttentionがVitの根幹と言えるでしょう。
Transfomerでは、その次のdecoderというものも存在するのですが、Vitではそれは活用しません。
それでは早速解説していきます。
2.Normは何をしているのか?
まずは、Normから説明していきます
名前の通り、正規化を意味する処理ですが
有名な正規化手法にBatch Normarizationというものが存在します。
その前に、そもそも正規化はなぜ必要なのでしょうか?
それは、ニューラルネットワークにおける勾配消失問題を防ぐ
ものです!
2.1 勾配消失問題とは
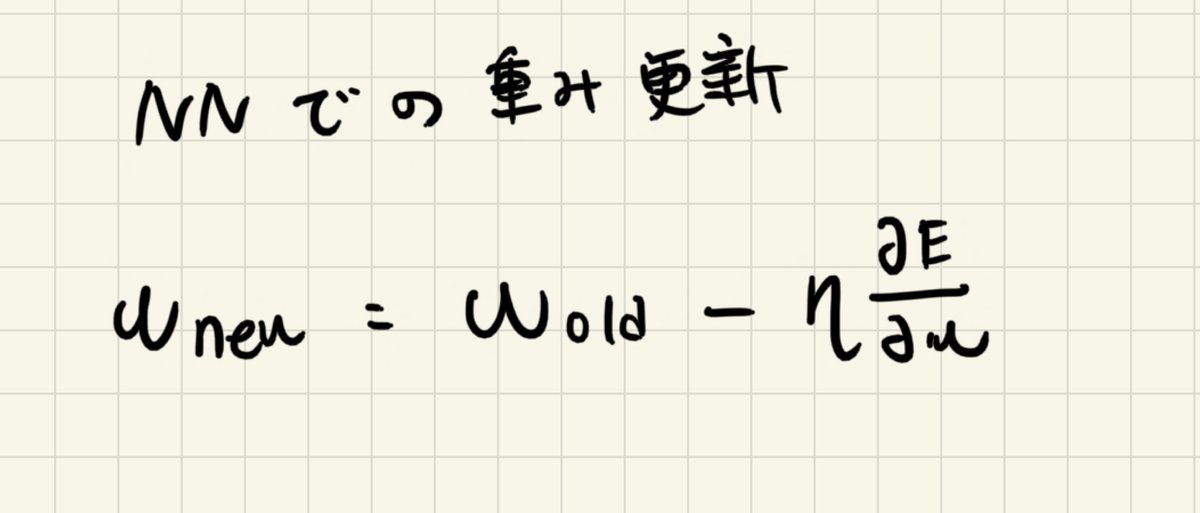
元々の重みに対して、
ロスEに対しての重みの偏微分を学習係数をかけて更新していくものでした。
勾配消失というのは、名前の通り勾配がなくなるという問題です。
0になってしまったら、第二項目の偏微分も当然0になってしまう。
つまり、重みの更新がされなくなってしまうのです。
なぜこのような問題が起きてしまうのでしょうか?
一つ目は、大きな学習係数をかけてしまったが故の勾配消失
ηがあると思いますが、これを大きくしてしまうと、新しい重みがとても小さな値になってしまいます。
そして次の更新でその小さな値を用いて更新が行われていくので、勾配が少なくなってしまうのです。
二つ目は、活性化関数のsigmoidを用いることによる勾配消失
三つ目は、初期値の重みの依存による勾配消失です
より詳しく知りたい方は別途調べてみてください。
そこで、Batch Normarizationを用いるとどうなるのでしょうか
例として、何かしらの関数F1, F2から計算できる損失関数を考えます。この時の各関数のパラメータθ1とθ2を損失関数が小さくなるように最適化するのが今やりたいことだとします。

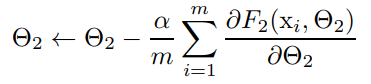
更新幅は、F1の出力(=x)を入力とした時のF2の誤差の微分から計算されるため、当然F1の分布がF2の計算に影響を及ぼします。この時、F1(=x)の各次元のスケールが合っていないと勾配降下法を使う場合、中々収束しない(=学習が非効率になる)問題が起きる可能性があります。
BatchNormarizationは、その各ノード毎に正規化することで
学習を効率的にする手法です。
パラメーターのスケールが正規化されるので、学習率を高くしても問題なくなります。
画像のNNだと、BatchNomarizationでも意外と問題なかったりします。
が、自然言語処理のNNだとどうなるでしょうか。
次の絵を見てみてください。

画像だったら、NNにInputする前にあらかじめResizeを行なって、形を整えますが、言語の場合だったらバッチ内の大きさが必ずしも均一ではないですよね。
バッチによって、平均、分散が大きく変わってしまうというのが弱点でした。
そこで現れたのが、Layer Normalizationです。
言葉で説明すると、各データごとに正規化をするという意味になります
これでバッチ間のデータの大きさによらずに正規化が可能になったということです。

機械翻訳モデルとして提案された元々のTransfomerもこのLayerNomalizationを用いられていたためか、VitでもこのLayerNomalizationが使われています。
3.Attentionについて
3.1 Self-Attentionの概念理解
これが結構大事な場面といえます。
まずはSelf-Attentionについて説明します。
まずは図をご覧ください

まずは、Emmbedingされたデータをq(Question),k(Key),v(Value)
に分割します。
そこで、分割する前に再度埋め込みを行い、異なる値を取っています。(学習可能にさせている)
その後に、qとkの転置で内積を計算しています。
なぜ内積を取っているのか。
それは、一部で少しフライングして説明した類似度を算出するからです。
どのパッチがどのパッチと似ているかを計算しているんですね。
これがCNNと違う良さなのです。
CNNは近しいパッチの特徴をよく捉えられますが、
離れたパッチの特徴をうまく捉えることができないのが弱みでした。
内積を算出することによって、遠い存在との関係性を捉えられるようになったってわけですね。
なんだかロマンがあります。
その次にvとの加重和を取ってあげれば完了です。
他にも細かい処理が中で入ってはいますが、捉えやすいように簡潔に説明しました。
後の数式説明する際に細かい部分は説明しようかと思います。
3.2 Multi-Head-Self-Attentionの概念理解
Self-Attentionでは、各パッチ間の関係性を捉えることができたと説明しました。
Self-Attentionにおいては、パッチ同士の関係は1つのみのAttention Weightが保持しています。
このAttention Weightが複数あれば、各パッチ間の関係を、複数捉えることができます。
ではどうすれば良いのでしょうか。
下の図のようにして、複数表現を可能にするのです!

このようにして、各パッチ間の関係性を複数のAttention Weightを作成して表現力を高めていったのです。
では次に数式表現をしていきます
3.3 Attentionの数式表現

p , k , v に分割する際に、それぞれ線形層を用意して埋め込みを行います
そこで、内積を取る際に、内積の結果の合計が1になるように
行方向にsoftmax関数を作用させます
ここで、内積の結果に対してデータの行数分で除しています。
これはなぜ行うのかというと、Dhが大きくなればなるほど内積の合計が大きくなってしまうことを防いでいます。
そして、図の通り、内積の計算ができたら、加重和を計算します。
ここは普通に行列式になります。

MHSAは、このSAの結果が分割個数分表されることになるので、
MHSAの結果は以下のように結合された形となります。

これでMHSAも完成しました。
4.他のエンコーダーブロックの性質
基本的には、Vitの大事な考えはこのAttension機構になります。
他には、スキップコネクションやMLPも組み合わせてEncoderブロックは処理されます。


5.MLP HEADについて
MLP HEADはシンプルな性質を持っています。
まず入力ですが、一部で説明したように、CLSには画像の情報が圧縮されたものと説明しました。
Encoderを処理したあとは、そのCLSのみを出力し、
MLP HEADに入力します。
MLP HEADの出力はクラス数と同じベクトルの長さになります。

5.まとめ
以上でVitの実装は終了になります。
高階層のCNNと違ってとてもシンプルなモデルでした。
これでもって高い精度を出せることについてはとても感動しました。
次回は、Pytorchで実際にVitを記述してみたいと思います。
それではまた。
この記事が気に入ったらサポートをしてみませんか?