
うちの子VroidでLoRAを作ってみよう(wd14-taggerで楽してキャプション付け)

※生成モデルはunlimited使用。説明わりと投げっぱなしです。
※LoRAぜんぜんわかんない!!!!!!!!
4/9 追記(変更箇所は記事下部へ)
LoRAってなに?
ざっくりいうと、画像生成AIで使えるファインチューニング(ネット上では追加学習とも呼ばれています)の手法の1つです。
自キャラのスクショからLoRAファイルを作成し、画像生成時に一緒に使うと、生成される絵にキャラクターの特徴を反映させることができます。
「この絵をこういう風にしてね」と指示するファイルを別途作成する感じです。ゲームでいうところの追加MODと考えるとわかりやすいかも?

ファインチューニングにはdreambooth、Hyper-Network等様々な方法がありますが、LoRAは優れたグラフィックボードを持っていなくても追加学習ができることや、学習時間の短さ(当社比)、作成されるデータサイズの軽さ等から幅広く使われています。
うちの子作るのにLoRAって必須?
こんな記事書いといてなんですが、だいたいの特徴が言葉で表現できるならプロンプトだけでも十分いけます。
金髪ツインテールでセーラー服のキャラクターなら "blond hair,twintail,blue sailor collar"という感じでどんどん特徴を挙げていきましょう。
Automatic1111's WebUIを使用している方は拡張機能を使うことをオススメします。画像から説明文(キャプション)を作成する拡張機能を使えば、うちの子プロンプトを簡単に作れますよ!
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
単語区切り型のキャプションを生成する拡張機能。
waifu-diffision等向け。
https://github.com/Tps-F/sd-webui-blip2
自然言語型のキャプションを生成する拡張機能。
文章型のプロンプトを作りたい方に。

しかし、プロンプトでの再現には限界があります。
キャラクターの特徴的な要素(独特な髪飾りなど)を反映させたい
キャラデザに忠実にしたい
こういうときにLoRAを用いるのがいいとです。
ただし、LoRAであってもグラフィックボードの性能はある程度必要です。nvidia社のGeForce RTX の3000番台なら問題ないと思いますが、それ以前のグラボなら様子を見て、動かなかったらgoogle colabを検討したほうがいいかもしれません。
(google colabについては説明しません。Googleで……ググれ!)
LoRA作りたい! どうやるの?
下の記事の手順に沿うのがいいのぜ!!!!
執筆してくださったぶっちーさんに深く感謝します。この記事なかったら冗談抜きで永遠にできなかったよ……。
ちなみにwin12ユーザーは、Pythonのインストールは出来るのになぜかPythonコマンドが正常に動かないことがあります。
そのときはWindowsの設定で「アプリ実行エイリアスの管理」と検索し、Pythonのエイリアスをオフにするといいみたい。私はコレで直りました。
よっしゃ!次行くぜ!
VroidでLoRA作ってみよう
Vroid studioのスクショからLoRAがいい感じに作れるか、試してみましょう!
なお、本項はVroidでのファインチューニングがうまくいくかどうかの検証になります。
いいから結論をさっさと教えやがれという方は「LoRA検証・結論」に、
いいからwd14-taggerの使い方教えやがれという方は「wd14-taggerで楽してLoRA用キャプションをつけよう」に飛んでください。
最初の学習状況は下記の通り。
学習元モデルはstable diffusionV2(なぜか私の環境だとSDV2・CJD以外は失敗します。なんでや)
解像度512×512、dim128、alpha128
スクショ30枚程度
背景は全透過
●学習用データセット1

LoRAで生成した結果はこんな感じ。


これはこれでカワイイけど……あんまり似てないって感じの画像が出がちですね。髪のツヤがいつも同じ位置に固定されていることも気になります。
ざっくり再現したいときにはこれでもいいけど、せっかくだからもっと精度が良くできないか色々試してみましょう。
ざっくりLoRA検証
15枚程度で、差をつけた画像データセットを用いて比較しました。
違いが分かりやすいようショートヘアにしてます。
all白背景です。
(体感的に学習の効き具合は、白背景>透過>>>背景あり って感じ)
●学習用データセット2
・アウトラインをオフに
・異なる髪テクスチャでのスクショも混合

●学習用データセット3
・ほぼ変化なし

●学習用データセット4
・データセット2の強化版
・アウトラインをオフに
・異なる髪テクスチャを混合
・一部の画像に髪だけimg2img

●学習用データセット5
・異なる髪テクスチャを混合しつつ、とにかく枚数を増やしてみる(30枚)

●学習用データセット6
・バストアップにimg2imgした画像を混合
(ラク~に髪の塗りの幅が出せないかな~と目論み)

まとめ
学習用データセット②は、アウトライン無し
学習用データセット③は、アウトライン有り
学習用データセット④は、②のパワーアップ版。髪の変化が大きい
学習用データセット⑤は、枚数が多い
学習用データセット⑥は、塗りを変えたバストアップ画像を混合
この中でどれが一番いい感じになるのか……
出力した結果がコチラ!
(クリックで拡大してね)



やっぱり枚数多いほうがいいっすねッー!!!
⑤が一番セヌ子さんの雰囲気が出ています。
学習枚数少なめの②③と比べて輪郭が安定してるし、眉もちゃんとピンク。watercolor(水彩風)にも対応できています。
髪テクスチャを変えたスクショを混合するだけで、髪のツヤ固定化現象がマシになるのは意外でした。
データセット⑤は最初のLoRAとそんなに変わらないはずなんですが、最初はキャプション付けをしっかりやっていなかったので、そこも大きかったのかなと思います。
意外と良かったのはデータセット④。特徴を抑えながら雰囲気が変わるので、イラストのテイストを変えたいときに重宝するかも。
元になった生成絵のニュアンスが残っているのがよかね。
データセット③も数が少ないわりも健闘しているので、30枚撮る元気がなくても、15枚あればうちの子再現はなんとかなりそう。
一方、データセット⑥は期待していたほどの効果はなし。
少数の例外を混ぜ込むのはあまり意味がなさそうです。
やってて思ったのは、まったく変わらない部分は残りやすいということですね。
すべて口を閉じた状態のスクショで学習すると、open mouthというプロンプトを入れても口を開けてくれません。
どういう画像を生成したいか、変えてほしくない特徴はどこか。
学習用データを作成するときはしっかり意識したほうがよさそうです。
LoRA検証・結論
安定した結果を得たいなら、枚数をとにかく増やす
動かせる部分は動かすと出力の幅が広がる。変わってほしくない部分はそのままにする。
3Dモデルでの機械学習を行う際は、異なる髪テクスチャを用いたスクショを混合すると髪のツヤの固定化を抑えられる
背景は単色。できれば白がよし。
キャプションはしっかり入れる
3Dモデルはテクスチャを用いる分、イラストと違って画のブレが出にくいのが固定化につながっている気がします。
3Dモデルを用いた機械学習においては、多様性を出したい部分には意識して変化をつけることが大事そうです。
一方、3Dモデルはスクショで画像を用意できるうえ、意識して変化づけが出来るので、機械学習とはかなり相性がいいかもな~と思いました。
wd14-taggerで楽してLoRA用キャプションをつけよう
いざしっかりLoRAファイルを作ろうとすると、学習用画像データ1枚1枚にキャプションを入れたtxtファイルをつける必要があります。
でも1枚1枚作るのは大変ですよね。
wd14-taggerでいい感じのキャプションファイルをまとめて作成しましょう!
説明の前に、「プロンプトとキャプションの違いって何?」と思われているかもしれませんので簡単に説明しますね。
キャプションは「画像の内容を説明するテキスト」。
プロンプトは「テキストで画像を生成するためのテキスト」です。

……ぜんぶ同じじゃないですか!!!!
キャプションファイルにはその学習用画像を再現できそうなプロンプトを入れればいいわけです。
というわけで、wd14-taggerを見てみましょう。
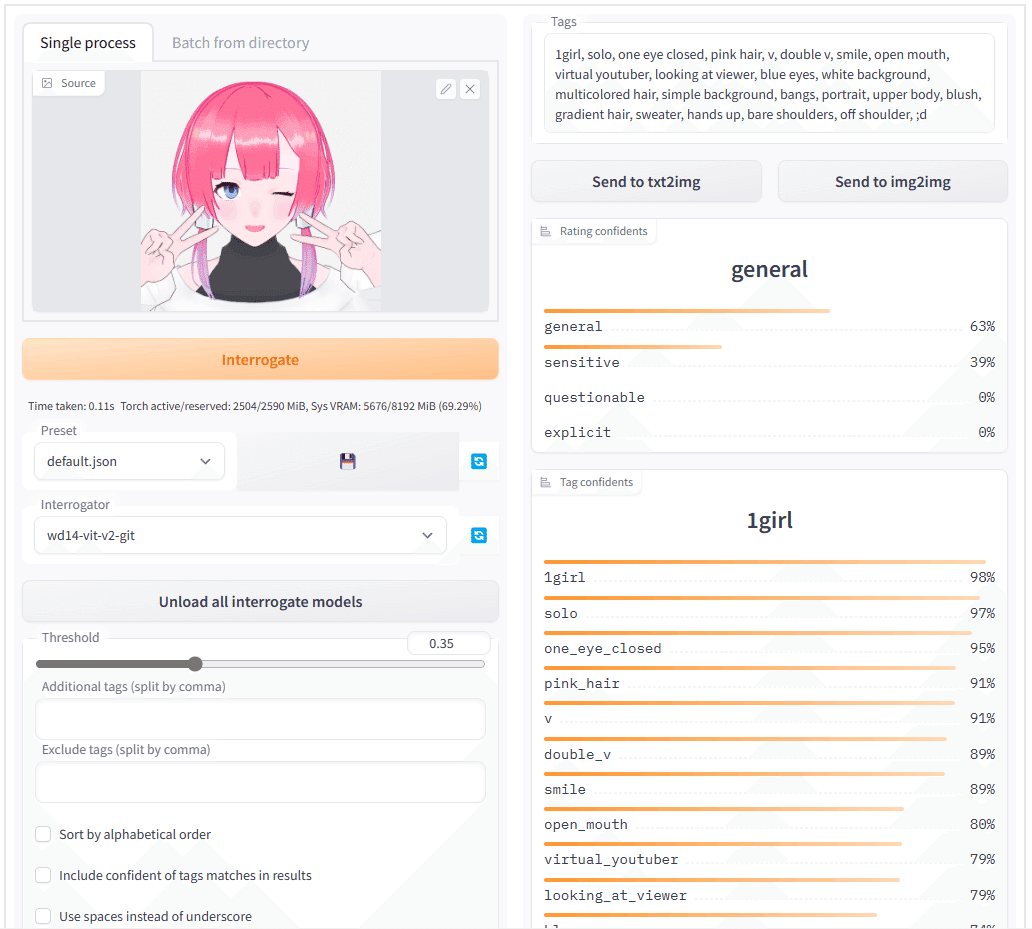
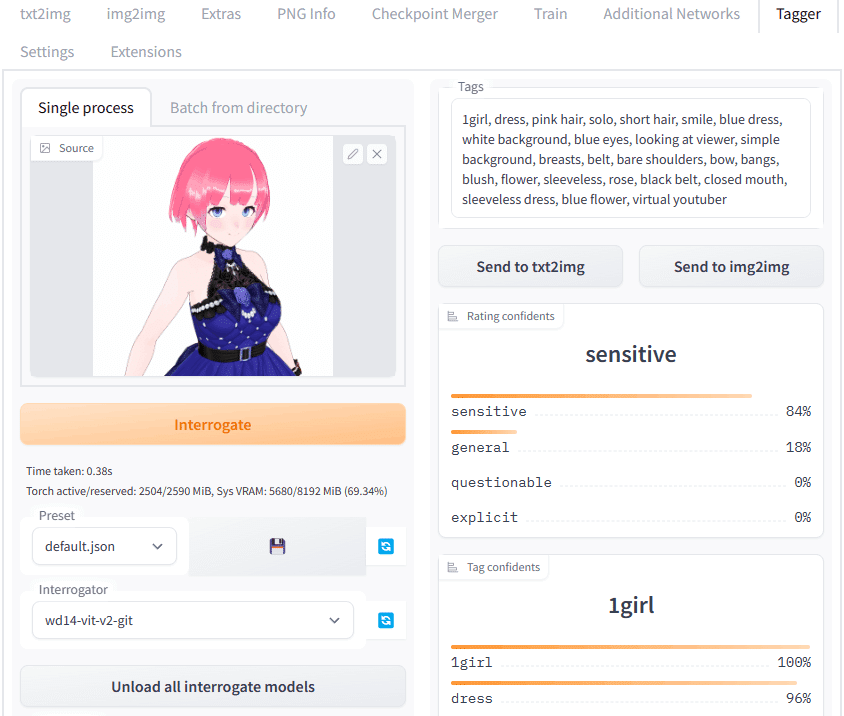
"tags"、"tag confidents" からうちの子の特徴を抜き出してみましょう。
セヌ子さんの特徴はこんな感じ。
pink_hair,virtual_youtuber,blue_eyes,bangs,multicolored_hair,streaked_hair,purple_eyes,blue_hair,blunt_bangs,gradient_hair,sidelocks,breasts,medium_breasts,multicolored_eyes,gradient,short_hair
上位にあったものからそれっぽいのを抜き出しています。
さてこれをキャプションに――入れません!!
むしろ省きます!!
どういうことかというと、学習させたい要素をLoRAに入れるためです。
「○○がセーラー服を着て立っている」の「○○」の部分がLoRAに入るので、「セーラー服を着て立っている」の部分だけキャプションに入れるんですね。
以上を抑えつつ、キャプションファイルを一括で作っていきます。
「single process」タブの隣、「Batch from directory」を開きましょう。
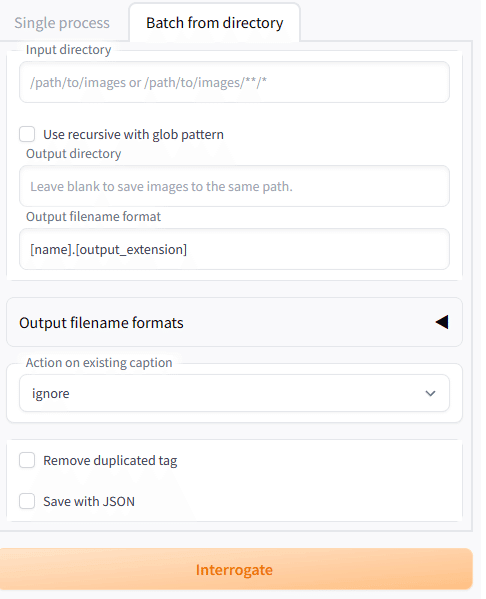
Input directory に学習用画像があるフォルダのパスを入力してください。
Action on exsiting caption で既存のキャプションファイルがあるときどうするか指定できます。ignoreは「上書きしない」です(たぶん)
上書きするcopyを推奨。
Interrogate(キャプション作成)を実行する前に、下へスクロール。

Additional tags で全てのキャプションにタグが追加できます。
LoRAを作るときはあんまり被らないワードのタグを入れるといいみたいです。私は「senukosan」というタグを入れています。
そして最重要項目。Exclude tags にさっき抜き出した特徴全部入れます。
pink_hair,virtual_youtuber,blue_eyes,bangs,multicolored_hair,streaked_hair,purple_eyes,blue_hair,blunt_bangs,gradient_hair,sidelocks,breasts,medium_breasts,multicolored_eyes,gradient,short_hair
こんな感じでまるっと入れてください。ここを入れておくことで、すべてのキャプションからこれらのワードが省かれます。
「セーラー服を着て立っている」の部分だけ残せるんですね。単語の区切りにスペースを使うときは「Use spaces instead of underscore」にチェックを入れること。4/9追記 改めて確認したところ、私の環境ではスペース込みではここにチェックを入れても正常にタグが除外されませんでした! _(アンダーバー)を使ったほうがいいかもです!!!!
最後に、キャプション作成のしきい値 Threshold を0.3~0.25ぐらいにしてください。しきい値が低ければ低いほどキャプションの量が増えます。
Exclude tagsを使うとタグが減ってしまうので、デフォルト設定のままだとキャプションがすかすかになっちゃうよ!
用意ができたらInterrogateを実行!
これだけで学習に必要なキャプションがすぐに作成できます。
もちろん1つ1つ手作業で編集するのがベストですが、手軽さからこの方法がオススメです。
がんばってうちの子の最強LoRAを作ってみましょう!
さいごに
ざっくりスクショを用意して、キャプションを用意すれば、LoRAは意外となんとかなります!
うちの子vroidだけでなく、プリセットvroidで自キャラに寄せて、そこからLoRAを作るという芸当も可能でしょう。
うまく活用して、AIが描いたうちの子を眺めてニヤニヤしてくださいね。
Vroidで機械学習する際は利用規則に注意してください。
Vroidのプリセットで学習する分は大丈夫ですが、boothなどでダウンロードしたデータを用いる場合は利用規則を読み、AI関係についての記載がなければ、事前に製作者様に確認したほうがいいでしょう。
画像生成AIは急速に広まった技術であり、あらゆる界隈でも利用規則などの整備が追い付いていません。どんなことができるのか・どんなことができないのかもまだハッキリしておらず、人によって捉え方も様々です。
迷惑をかけない程度に超!エキサイティング!!しましょうね。
4/9追記
・LoRAを「追加学習」の手法の1つと紹介していましたが、「追加学習」というのは俗称であり正確には「ファインチューニング」と言うそうです。
間違ったこと言ってましたすみませんー!!
・Exclude tagsについて、単語の区切りにスペースを使いたいときはチェックを入れると良いと書きましたが、私の環境では_(アンダーバー)でないと動きませんでした。
もし動かなかった人いたらごめんなさい、アンダーバー使ってください!!
・ついでに学習用データの設定追記しました。
解像度512*512、dim128、alpha128でやっています。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?