
【AIイラスト】30分でできるStable Diffusionの環境構築【Windows】

友達に教えて「環境構築について教えて」と言われたのでその説明をする前の整理と、復習用にnoteを書きましたLinuxでもmac環境でもStable Diffusionの構築は可能ですが、Windows環境を想定して記載します。
このnoteを見ると何ができる?
ローカルPCでStable Diffusionを用いてイラストが生成できるようになります。また、イラスト生成をブラウザで実行しやすくするために作成されているAUTOMATIC1111というものを利用します。
ローカルPCで構築とかよくわからない!めんどくさそう!という方はほかのサービスを利用しましょう。月に1000円くらいかかりますが、安定した画像を出力してくれるNovel AIやMidjourneyを利用すると良いでしょう。
はじめに
この手順は2023/6/17の情報をもとに作成されています。
鉄則です。公式のドキュメントを見ましょう。Googleで検索して個人ブログで書いている内容を探す必要はありません。公式に書いてあるのが正解です。
というのも環境がどんどん変わっていきます。半年前は正しかった情報でも最新では異なっていて、その半年前の情報をもとに書かれた内容通りにやってもうまくいかないという事はよくあります。
そのため、まずは公式ドキュメントを見ることを推奨します。私も現時点では公式ドキュメントの情報をもとに記載しますが、いつ情報が古くなるかわかりません。
ただ、公式ドキュメントではいろいろ前提条件が省略されています。そのため、PC初心者に向けていろいろ補足をしながら「なんでこんなことをするの?」という事も説明しながら進めていきたいと思います。
このGitHubのInstallation and Runningを見ながら進めることができる方はこの記事は不要です。

この1~4の手順について、実行方法を順に説明します。
1.Install Python 3.10.6
AUTOMATIC1111を動かすためにはPythonというものが必要です。
Pythonというのはプログラミング言語です。全く知識が無い方は身構えてしまいそうですが、プログラムを書くわけでは無く、実行するために環境が必要というわけです。Pythonのプログラムが書けるようになる必要はありません。
ダウンロードは以下の公式サイトから行います。

画面上部に「Downloads」とあります。ここでダウンロードできそうですね。ただここで注意なのがPythonにはバージョンがあります。公式ドキュメントで3.10.6で動くと書いてあります。記載時点ではDownloadsにフォーカスを合わせると3.11.4と表示されます。バージョンが違いますね。動くかもしれないですが、公式に言われた通り3.10.6を利用しましょう。
Windowsという場所を選択するとダウンロードのリンクのページに飛びます。

数字がたくさん並んでいますが、この中から「3.10.6」を探します。
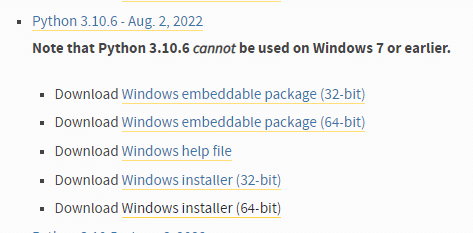
「3.10.6」にもいろいろあります。「Download Windows installer (64-bit)」を選びましょう。そのほうが楽だからです(自力で「環境変数」とか設定できる人は好きにしてください)。
このリンクをクリックするとexeファイルがダウンロードできるので、実行してください。基本全部「はい」とか「肯定」でよいです。
インストールができたかどうかはコマンドプロンプトで確認します。
Windowsの画面下の「ここに入力して検索」に「cmd」と入力してコマンドプロンプトを表示させます。

こんな黒塗りの画面が出てきます。ここに「python --version」と入力し、Enterを押し、「Python 3.10.6」と表示されたらインストール成功です。もし表示されなかった場合は失敗しているのでもう一度読みなおして実行してみてください。

2.Install git.
3.Download the stable-diffusion-webui
今回は最短で実行するための方法を説明するのでGitについては説明を省略します。IT業界で働くとかであれば必須かもしれないですが、一旦動かすだけなら不要です。

> Download the stable-diffusion-webui repository, for example by running git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git.
3の手順に書かれているこの辺りは「Git」という仕組みを使って最新のソースコードを自分のPCにダウンロードをする方法が書かれています。
今回はGitのインストールはせずにダウンロードしましょう。
以下のページにアクセスします。
画面の左あたりに「Code」というものがあります。これをクリックすると次のようにメニューが開かれます。
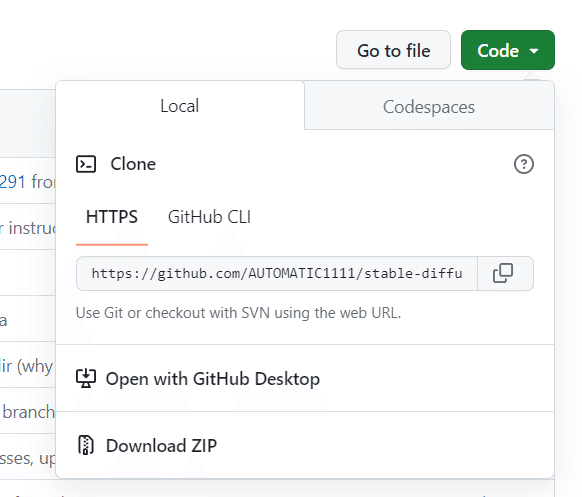
このDowmload ZIPをクリックします。
デスクトップのどこかに配置し、ZIPを解凍してください。ZIPファイルを右クリックして「全て展開」を押せばファイルが展開されます。たくさんファイルが表示されると思います。
4.Run webui-user.bat
実行します。

展開したファイルの中に「webui-user.bat」というものが混じっているので、これをダブルクリックします。
ダブルクリックすると先ほどの「コマンドプロンプト」が表示され、何か動作を始めます。

しばらく待っていると処理が完了します。「Running on local URL: http://127.0.0.1:7860」の文字が表示されれば起動完了です。

ChromeでもEdgeでも何でもよいのでブラウザを起動し、URLに「http://127.0.0.1:7860」を貼り付けます。

このような画面が表示されれば成功です。これで環境構築が完了です。
モデルを取得する
その前に「モデル」という概念を知っておく必要があります。今回環境構築したStable Diffusionは何もないところから絵を生み出すわけでは無く、見本みたいなデータから絵を作成します。
「グラビアアイドルの写真」の見本を元に作成したら、「グラビアアイドル風の写真の様なイラスト」ができますし、「アニメ調のイラスト」の見本を元に作成したら「アニメ調のイラスト」が作成されます。
この見本が「モデル」です。
なので「眼鏡をかけた女性」を描いてと言っても見本が異なれば出力されるイラストは異なります。
例えば「灰色のパーカーを着て、赤いショートカットで、眼鏡をかけた女性」と言ってもモデルによってこれだけ変わります。



全部「灰色のパーカーを着て、赤いショートカットで、眼鏡をかけた女性」ですが、違うのがわかるかと思います。
この「モデル」ですが、いろいろな人が次々に新しいものを発表してるので正直きりがない印象ですし、出力したい絵によっても変わってきます。
モデルは「huggingface」や「civitai」でダウンロードできます。
今回は「SEmix」というモデルを使ってみましょう。
次のURLにアクセスしてください。
タブからFiles and versionsを選択します。

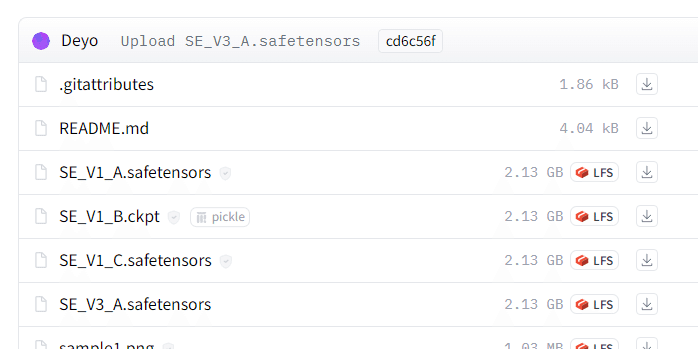
ここにあるckptやsafetensorsというのがモデルです。
今回は「SE_V3_A.safetensors」というものを利用しましょう。この矢印をクリックするとダウンロードできます。

ダウンロード先には3の手順でダウンロードし、解凍したフォルダの中の次のパスの中に保存します。
StableDiffuion\stable-diffusion-webui\models\Stable-diffusion
フォルダがたくさんあって探すのが大変ですが、この中に「SE_V3_A.safetensors」を入れてください。
ダウンロードが完了したらまたブラウザに戻ります。
画面左上の青い更新ボタンを押すと、左側の選択肢に「SE_V3_A.safetensors」が表示されます。
これでモデルを使えるようになりました。
実際に出力してみる。
絵を出力するためには「こういった絵を描いて」とAIに依頼する必要があります。

画面真ん中あたりのこのテキストボックスの中に入力します。
上の箱は「こういった要素で書いて」というものを入力します。これをpromptと呼びます。
下の箱は「こういった要素は除外して」というものを入力します。これをNegative promptと呼びます。
入力は英語で行います。
英語が書けない人はDeepLなどを使うといいでしょう。

今回は公式ページのサンプル通りに入力してみましょう。

上の箱に
「(best quality:1.4),(1girl:1.3),(bob cut:1.2),silver hair,off shoulder white dress,ribbon on side hair, blue eyes,hair ribbon red ribbon on side hair」
下の箱に
「EasyNegativeV2,(worst quality:1.4),(low quality:1.4),(monochrome:1.1)」
と入力します。
Steps: 30
Sampler: DPM++ 2M Karras
CFG scale: 7
Clip skip: 2→これは追加設定が必要でややこしいので省略します
この辺りの情報も入力します。画面中央に対応しそうな箇所があると思うので、入力してください。全部入力しなくてもよいです。見つかった範囲で良いです。
また、それぞれパラメータですが、いったん今回は動かすことが目的なので内容については気にせずそのまま入れます。

このように入力が終わったら画面右のオレンジ色のGenerateボタンをクリックします。
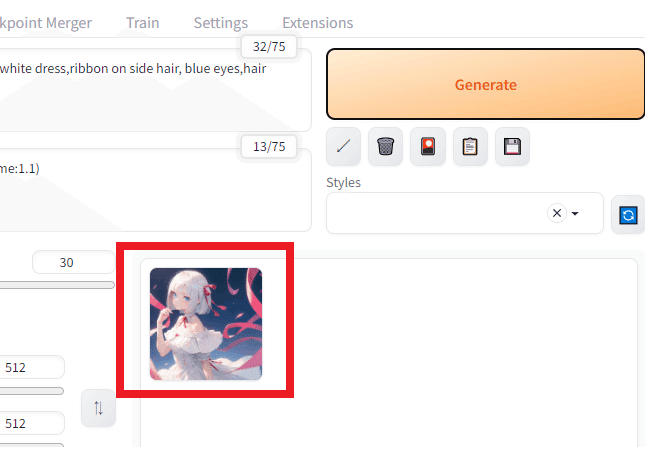
少し待つとここに作成された画像が表示されます。

これで画像の生成が完了です!Generateを押すたびにキャラクターが作成されます。
Promptに「(best quality:1.4),(1girl:1.3),(bob cut:1.2),silver hair,off shoulder white dress,ribbon on side hair, blue eyes,hair ribbon red ribbon on side hair」つまり「(最高品質:1.4),(1girl:1.3),(ボブカット:1.2), シルバーヘア, オフショルダー白ワンピース, サイドヘアにリボン, ブルーアイ, ヘアリボン赤サイドヘアにリボン)」と入力しているので、そのイラストが次々に作成されると思います。
試しにpromt(上の箱。下の箱はそのまま)に「(best quality:1.4),(1girl:1.3),(bob cut:1.2),One girl, grey hoodie, short cut, red hair, wearing glasses.」と入力してみてください。
さっきと異なるイラストが出力されます。

まとめ
これで出力できるようにはなったと思います。お疲れさまでした。
ここから「きれいなイラスト」や「狙ったイラスト」「思った通りのイラスト」を描くには「どのモデルを使うか」であったり、先ほどの「(best quality:1.4),(1girl:1.3),(bob cut:1.2),silver hair,off shoulder white dress,ribbon on side hair, blue eyes,hair ribbon red ribbon on side hair」と入力した「Prompt」や、「Steps: 30」といったパラメータなどを調整していく必要があります。
以下同じpromptでstep数を10と100と数値を変更するとこのように変わります。stepはどれだけ繰り返し作成するかで増やせば情報量が増える傾向にありますが、増やせばよいというものでも無いようです。


ここから先はネット上に転がっている情報をもとに思考錯誤する必要があります。ぜひ有益な情報があればこのブログのコメント欄に記載していただければと思います!
この記事が気に入ったらサポートをしてみませんか?