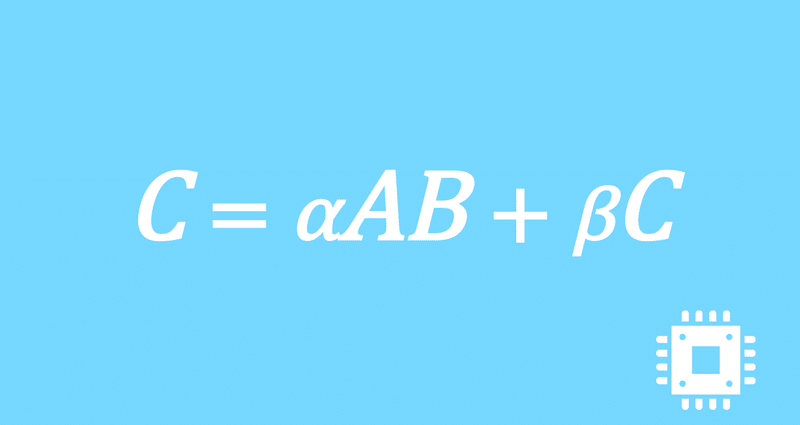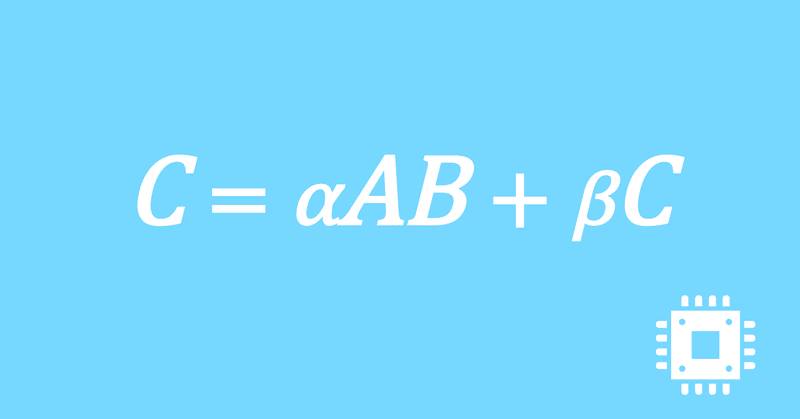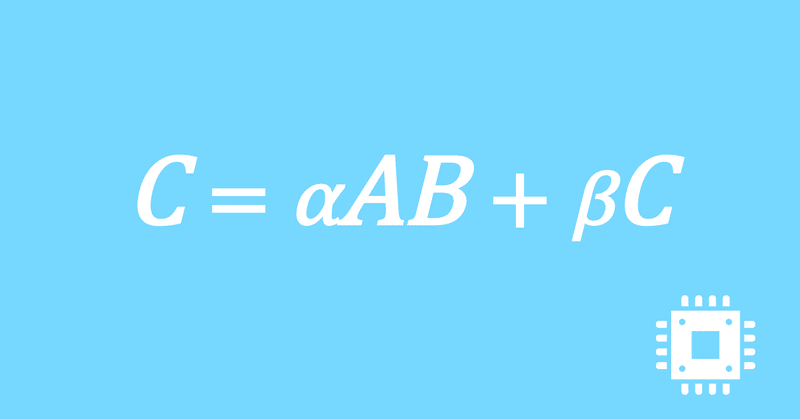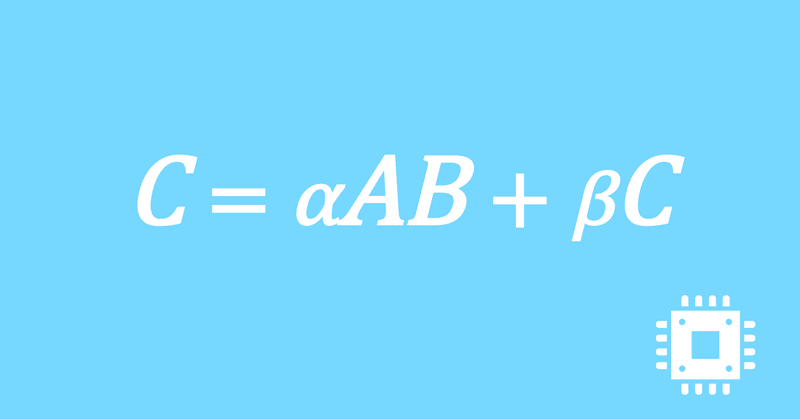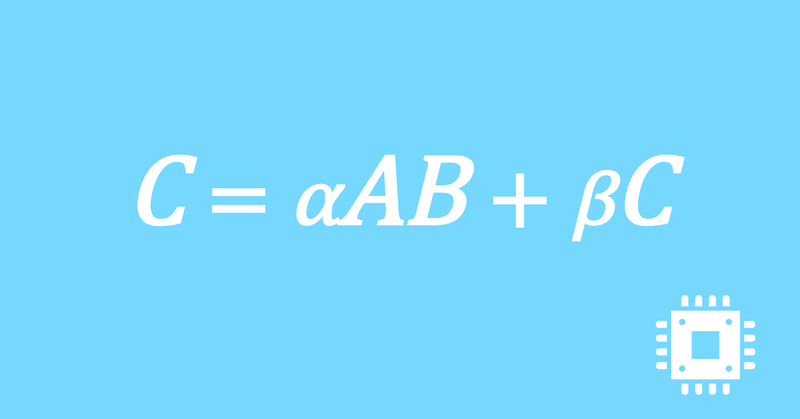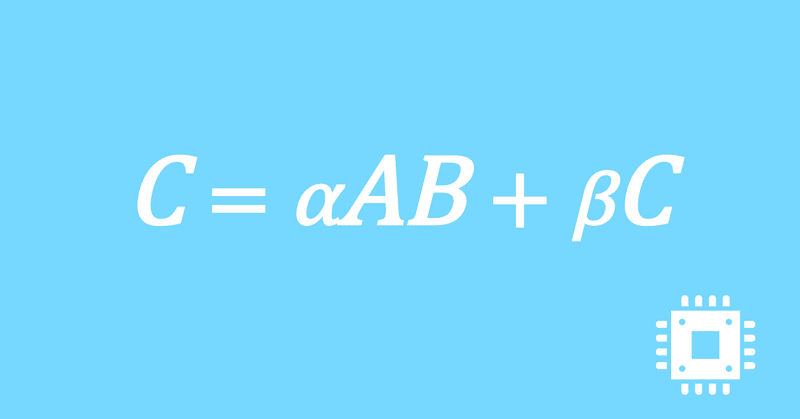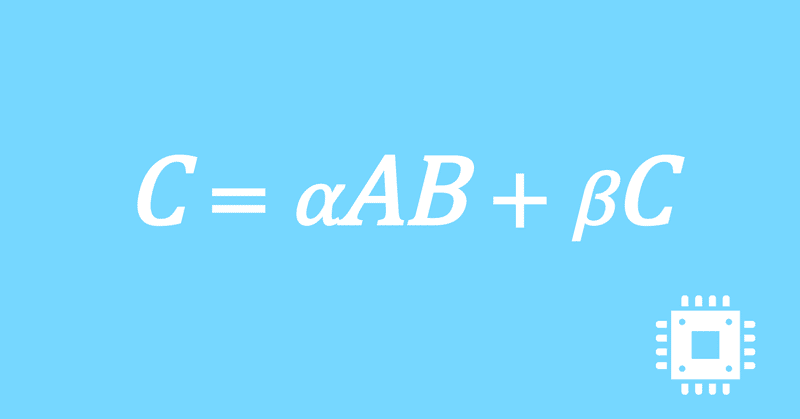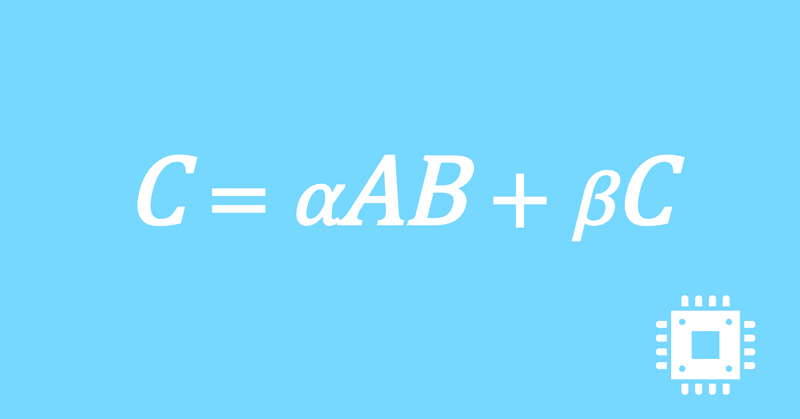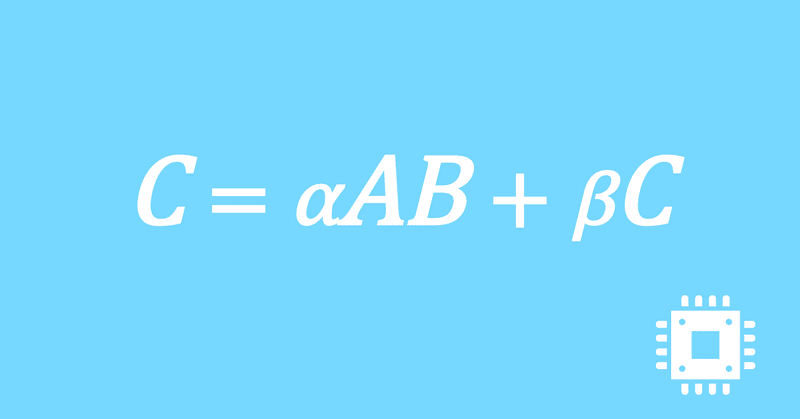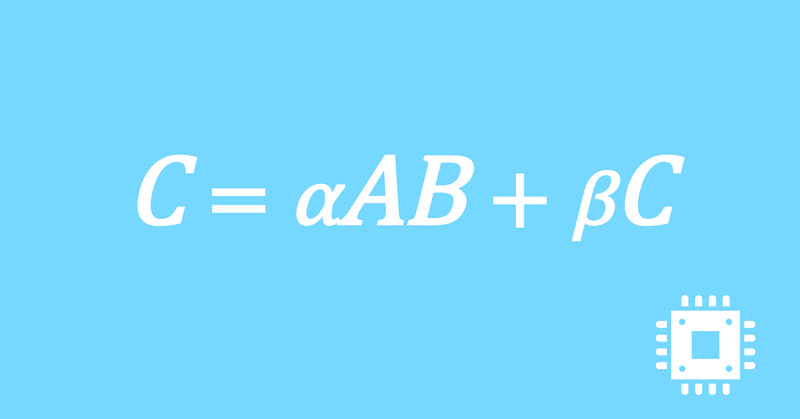行列積の性能測定|行列積高速化#24
この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
以上で、行列積DGEMMの最適化手続きは全て完了しました。思ったよりも性能は出ませんでしたが、いったんこの記事は終了にします。
それでは、最終的にどの程度高速化できたのかを確認します。
計算速度の行列サイズに対する依存性を見るために、NxNの正方行列を対象として基本周波数の理論ピーク性能比を、N=16,32,...,2048で測定しました。