ラビットチャレンジ:Stage3実装演習レポート

ここから深層学習の本格的な学習が開始
深層学習Day1
Section1:入力層~中間層
・入力層
データを最初に処理する層。一つの情報(例えば画像)を複数の数字の組(画像であれば、各ピクセルの色のRGB表現など)で表現したものを入力として扱う。入力値をXとして、N個の数字の組で表現される場合
X = ( x1, x2, x3, ・・xN)
というN次のベクトルとしてあつかう
・中間層
入力層から受け取ったベクトルに対し、重みWを掛け合わせて新たな出力を生成する。N次のベクトルに対してはN個の重みを用意し
W = ( w1, w2, w3, ・・wN)
と表現すると、中間層の出力は
u = w1*x1 + w2*x2 + w3*x3 + ・・・ + wN*xN
で表現されるが、ここにどのxiにも影響されない重み(バイアス)を加えて
u = w1*x1 + w2*x2 + w3*x3 + ・・・ + wN*xN + b
もしくは、bをw0と表現し
u = w0 + w1*x1 + w2*x2 + w3*x3 + ・・・ + wN*xN
と書き表すこともある。
演習:


確認テスト


Section2:活性化関数
確認テスト
線形と非線形の違い

活性化関数とは、ある層の出力を一定の大きさに整えるために利用する関数。以下のような関数が用いられる。
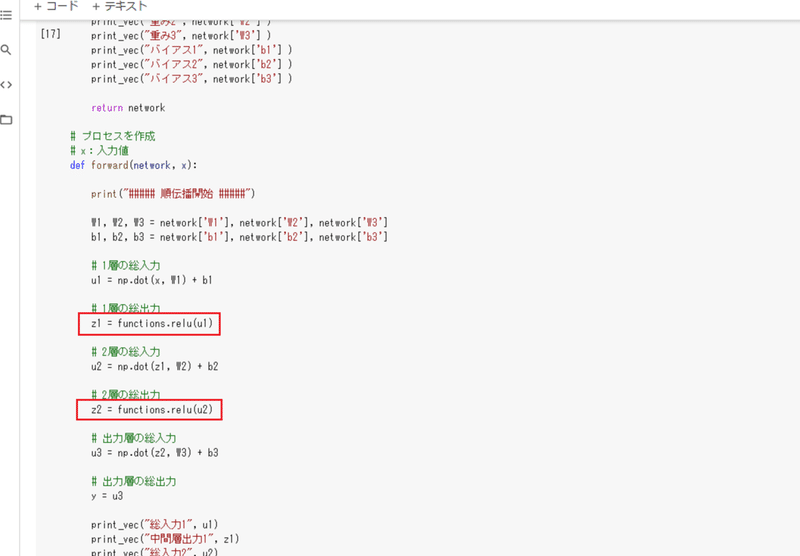
・ReLU関数
f(x) = x ( x > 0 ) or 0 ( x ≦ 0 )
・シグモイド関数(ロジスティック関数)
f(x) = 1 / ( 1 - exp(-x) )
・ステップ関数
f(x) = 1 ( x > 0 ) or 0 ( x ≦ 0 )
確認テスト
# ReLU関数
def relu(x):
return np.maximum(0, x)Section3:出力層
中間層の計算結果をもとに最終的な結果。主に予測結果などの人間に対しての出力。(※中間層まではあくまでも次の層への入力に使うための出力)
活性化関数を用いて、確率として表現するなど人に対して情報が伝わる数値を出力する必要がある。
誤差関数
出力層の出力結果とあらかじめ用意された正解値を比較し、その誤差を表現する関数。深層学習では、誤差をより小さくするために各入力層の重みを更新することで、モデルの精度を上げる。
誤差関数は、平均2乗誤差や交差エントロピーを用いる
活性化関数
出力層では中間層と異なる活性化関数が使用される
・ソフトマックス関数
f(i,x) = exp(xi)/Σexp(x)
# ソフトマックス関数
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # オーバーフロー対策
return np.exp(x) / np.sum(np.exp(x))・恒等写像( f(x) = x )
・シグモイド関数(ロジスティック関数)
確認テスト
2乗する理由:誤差全体の合計を算出する際に打ち消しあわないように必ず正の値をとるようにするため。
1/2の意味:微分したときに係数を1にして計算を楽にするため。
平均2乗誤差のコード
# 誤差関数
# 平均二乗誤差
def mean_squared_error(d, y):
return np.mean(np.square(d - y)) / 2交差エントロピーのコード
# クロスエントロピー
def cross_entropy_error(d, y):
if y.ndim == 1:
d = d.reshape(1, d.size)
y = y.reshape(1, y.size)
# 教師データがone-hot-vectorの場合、正解ラベルのインデックスに変換
if d.size == y.size:
d = d.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7)) / batch_size確認テスト1
ソフトマックス関数の説明
①def softmax(x):
関数の定義。数式のiはxの添え字に相当するため、変数としては不要
②np.exp(x)
ベクトルxの個々の要素に対して、exponential(ネイピア数)のx乗を表す
③np.sum(np.exp(x))
ベクトルxの個々の要素に対して、exponential(ネイピア数)のx乗を加算したもの。
数式としてはnp.exp(x)/np.sum(np.exp(x))となっていて、数学的な意味としては、各要素の加重平均を求めている(総和が1になる)事に他ならない。
確認テスト2
交差エントロピーの説明:主に分類問題で使用する誤差関数
①def cross_entropy_error(d, y):
関数の定義。ここで、変数dは数式上のdとは異なり、正解と予想した位置を表す。
②-np.sum(np.log(y[np.arange(batch_size), d] + 1e-7))
yは分類問題の予測値のため、0 or 1の値をとる。
つまりnp.log(y[np.arange(batch_size), d])は log1または log0 となるが、log0は対数の定義ではx > 0 に限られるため、ごく小さな値1e - 7を加算して値を算出する。つまり
log(1 + 1e -7 ) ⇒ ほぼ0
log(1e -7) ⇒ ‐∞
となることから、yiとdiが共に正解を示していれば小さな数となる。
Section4:勾配降下法
誤差関数の出力値を最小化するパラメータ(重みW)を見つけ出す手法。
Wt+1 = W t - ε∇E
Wt+1 ・・・ 新しい重み
Wt ・・・ 現在の重み
ε ・・・ 学習率
∇E ・・・ 勾配(誤差Eを重みWで微分したもの)
勾配降下のイメージ
Wを更新して、徐々に最小になるポイントに近づける

x = -2 の点から開始し、εが適切であれば①に大きすぎると②(遠ざかる)になってしまう

x = -2 の点から開始し、εが適切であれば①に小さすぎると②(進みが遅い)になってしまう。また、小さすぎる場合に局所極小解にたどり着いてしまう可能性がある。
確認テスト:オンライン学習とは?
データを追加しながら学習を進められる手法。対義となる学習方法は「バッチ学習」で、最初から全量を用意する必要がある学習方法で、データを追加した場合には改めて全量を対象として学習をやり直す必要がある。
確認テスト:勾配降下法の視覚表現

徐々に最小に近づいていく
Section5:誤差逆伝播法
Wt+1 = W t - ε∇Eにおける∇E(微分値)をどのように計算するか?
数値微分(微小な数値を使って疑似的に微分値を求める)という手法があるが、計算量が増えてしまう。これを回避するために誤差逆伝播法を利用する。
合成関数の微分の性質(微分の連鎖律)を使うことで再帰的な計算を避けることが出来る。
確認テスト1

確認テスト2
δE/δy*δy/δu
delta2 = functions.d_mean_squared_error(d, y)δE/δy*δy/δu*δu/δw2
grad['W2'] = np.dot(z1.T, delta2)深層学習Day2
確認テスト
dz/dx = dz/dt * dt/dx
z = t^2
t = x + y
dz/dt = 2t
dt/dx = 1
dz/dx = dz/dt * dt/dx = 2t = 2(x+y)Section1:勾配消失問題
微分の連鎖律により、入力層により近い層の重みを算出するが、各微分値が小さい(1未満)となることから、計算を重ねるごとに小さくなり、ほぼ0になってしまう。
結果として誤差伝播による勾配の更新によって重みがほとんど変わらなくなり、学習が進まなくなる問題の事。
確認テスト
sigmoid(x) = 1/(1 + exp(-x))
sigmoid'(x) = (1- sigmoid(x))*sigmoid(x)
sigmoid'(0) = (1 - sigmoid(0))*sigmoid(x)
sigmoid(0) = 1/(1+exp(0)) = 1/(1 + 1) = 1/2
sigmoid'(0) = (1 - 1/2)*1/2 = 1/4 ・・・(2)この問題の解決策は
・活性化関数の選択:ReLU関数の利用
・重みの初期値設定:XavierやHeによる初期値設定。選択する活性化関数によって異なる。
・バッチ正規化
などが考えられる。
確認テスト
重みの初期値に0を設定すると、各重みの値が同じ値で更新されるため重みの意味を成さなくなり正しい学習結果とならない。
バッチ正規化
ミニバッチの単位で入力値のデータの偏りを抑制する手法
確認テスト
・中間層の重みの更新が安定化される。
・過学習を抑えることが出来る。
Section2:学習率最適化手法
・モメンタム
誤差をパラメータで微分したものと学習理の積を減産した後、現在の重みに前回の重みを減算した値と慣性の積を追加する。
Vt = μVt-1 - ε∇E
Wt+1 = W t + Vt
慣性:μ
・AdaGrad
誤差をパラメータで微分したものと、再定義した学習率の積を減算する
h0 = Θ
ht = ht-1 + (∇E) ^2
Wt+1 = W t - ε/{sqrt(ht) + Θ} * ∇E
・RMSProp
誤差をパラメータで微分したものと再定義した学習率の積を減算する
ht = αht-1 + (1 - α)(∇E) ^2
Wt+1 = W t - ε/{sqrt(ht) + Θ} * ∇E
確認テスト
・モメンタム
局所最適解にはならず、大域的最適解となる。
谷間についてから最も低い位置(最適値)に行くまでの時間が早い。
・AdaGrad
勾配が緩やかな斜面(誤差関数が深くない)に対して、最適値に近づける
学習率が徐々に小さくなるので、鞍点問題を引き起こすことがあった
・RMSProp
局所最適解にはならず、大域的最適解となる。
ハイパーパラメータの調整が必要な場合が少ない。
実装:

SGDの学習結果(失敗)

モメンタムの学習結果(失敗)

AdaGradの学習結果(失敗)

RSMPropの学習結果(成功)

Adamの学習結果(成功)

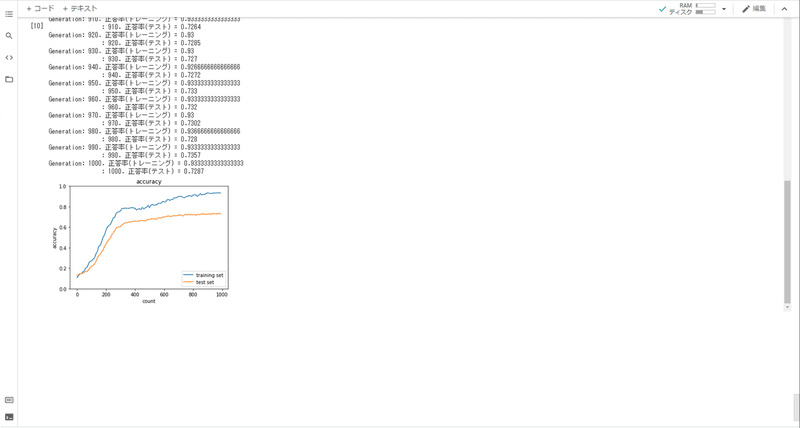
Section3:過学習
訓練データでは誤差(訓練誤差)を小さくできたが、テストデータでは誤差(テスト誤差)の乖離が大きくなる状態。訓練データに特化して学習してしまっていることから、汎用的なモデルとならないもの。
主に
・パラメータの数が多い
・パラメータの値が適切でない
などの理由で発生する
・正則化
ネットワークの自由度(層数、ノード数、パラメータの値など)を制約すること。
確認テスト
L1正則化はLasso推定量に基づく正則化であり、図中右側がL1正則化を表現している。
・ドロップアウト
ランダムにノードを削除して学習させる手法
実装:



Section4:畳み込みニューラルネットワークの概念
次元間でつながりのあるデータを扱うことが出来る。(画像以外でも可)
中間層
畳み込み層、プーリング層、全結合層と呼ばれる各層で構成される
画像の場合
入力層→畳み込み層→畳み込み層→プーリング層→畳み込み層→畳み込み層→プーリング層→全結合層→出力層
畳み込み層の入力値
入力値はピクセルデータのイメージ(N×Nの数字の集まりで一つのデータ)
畳み込み層では、縦、横、チャンネル(例えばRGBの各々でチャンネルを分ける)の3次元のデータをそのまま学習して次に伝える。
演算概念

フィルタと同じサイズの領域に対して、重なる部分の積の総和をとる。
3*3 + 4*1 + 4*2 + 0*8 + 8*7 + 9*5 + 0*5 + 4*4 + 3*1 = 141
これを、既定のストライド幅に従ってずらした領域で実施し、各領域の畳み込み演算の結果にバイアスを加算して最終的な出力画像を得る。(以下ストライド:1の場合)

実装:



プーリング

Maxプーリング:対象領域内の最大値をとる
Averageプーリング:対象領域内の平均値をとる
確認テスト

求め方
{入力画像の幅+パディング × 2 - ( フィルタの幅 - フィルタの余剰分 )} ÷ ストライド
{6+2 - (2 -1)}/1 = 7
よって出力画像は 7 × 7
Section5:最新のCNN
AlexNetのモデル:
・ImageNetの問題を解くモデル
・5層の畳み込み層及びプーリング層など、それに続く3層の全結合層から構成される
・過学習を防ぐ施策として、サイズ4096の全結合層の出力にドロップアウトを使用している
AlexNetは2012年のチャレンジコンテスト(ILSVRC)で1位を獲得した、当時もっともすぐれたモデルであった。
この記事が気に入ったらサポートをしてみませんか?