
日刊 画像生成AI (2022年9月1日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために個人的に日々まとめている業界変化、新表現、思考、問題、技術を投稿していこうと思います。あまりの変化の速さに個人的に毎日まとめていたものを友達に公開したところ反応がよかったため、このような経緯となりました。
今日から毎日投稿です。
次の号はこちら
(見てくれる人どんどん増えてて嬉しい。)
技術
DALL・E 「Outpainting」追加
これまで他の画像生成と比べ、キャンバスが小さい問題があったDALL・E。今回のアップデートで大きく変わります。以下Openaiが出してた公式事例です。すごい、期待しかない。



DALL·E: Introducing Outpainting
— AK (@_akhaliq) August 31, 2022
Extend creativity and tell a bigger story with DALL-E images of any size
blog: https://t.co/dBRzCXWDYF pic.twitter.com/9sOyDMPEb7
個人的に使ってみました。
クリムトさんの新しい絵を生み出し、それをoutpaintingでどこまで行けるか試してみます。





やばいから見て..... DALL・EがアップデートでOutpaintingしやすくなったので、新しいクリムトさんの絵を生成して超拡大してみた。 画質もクオリティも超高いし、ここまでの密度のAIアートは初めて見て、超感動した。 人間の絵画より絶対こっちの方がいい。 #dalle2 #dalle #AIart pic.twitter.com/P5YOLJO0AX
— やまかず (@Yamkaz) September 1, 2022
📝 豆知識
https://patch-e.com/
PATCH・Eというサービスがあり、同様のことができました。
ただ、いちいちDALL・Eの生成画像ダウンロードして、トリミングして、アップロードしてを繰り返して..と面倒な作業をせねばならずでしたが、これも不要になりましたね。嬉しい。
Stable Diffusion v1.5 テスト実施
昨日10:00から始まりました。Stable Diffusionチェックポイント1.5を、Discord botを使い、テスト中。プロポーションがかなり優れており、奇妙に歪んだ顔を生成しなくなったそうです。
(Midjourneyの--upbeta, --beta, --creativeのテストと似てる。)
Stable Diffusion Discordはこちらから。

StableDiffusionの アップデート版ver1.5がベータ始まった。細部のエレメントや縦横比のことなる画像の安定度が上がったかな?
— 深津 貴之 / THE GUILD / note.com (@fladdict) August 31, 2022
画質の話はムーアの法則的に改善するので、ダメ出ししてもあんま意味ない感。#stablediffusion pic.twitter.com/YTQoyFGQm3
ERNIE-ViLG公開
※ 8/29に公開されていたっぽい。
中国製の画像生成AIが話題に上がっています。
今日のワンクリックはこちら(中国の画像生成AI「ERNIE-ViLG」が1〜2分で生成した画像) pic.twitter.com/XsQYmnto8u
— 小猫遊りょう(たかにゃし・りょう) (@jaguring1) September 1, 2022
中国AIのERNIE-ViLGは100億パラメータのクロスモーダルGANモデルでデータセットにはMS-COCOとかCOCO-CNとかAIC-ICCとか食ってるの。性能としてはOpenAIのDall-E(2ではなく)に近いのかな。XMC-GANに関しては去年の5月頃に中国人著者の論文が公開されとる。
— あぶぶ@健全 (@abubu_newnanka) September 1, 2022
表現
KAREN X CHENG チュートリアル公開
映像監督 KAREN X CHENGさんが先日バズったAIを用いた映像のチュートリアルを公開。
AI Fashion Tutorial -
— Karen X. Cheng (@karenxcheng) August 31, 2022
A more detailed breakdown of yesterday's video. (Btw turn sound on for more context in the voiceover)#dalle2 #dalle #ArtificialIntelligence #digitalfashion #virtualfashion pic.twitter.com/B9PlWXQa6O
img2img:顔をイケメンに加工
※ 8/31の情報です。
img2imgを使って、プロフィール写真をかっこよく変える実験をしている方がいらっしゃいました。
Tip: Use #stablediffusion img2img to slightly enhance your profile pictures pic.twitter.com/VPvI009RLT
— Twisted Mentat Matt (@moridinamael) August 30, 2022
踊る珊瑚礁?
another test from yesterday #stablediffusion pic.twitter.com/WEBkiBmti3
— Infinite Vibes (@Infinite__Vibes) August 31, 2022
蝋人形の美しい表現
Wax sculptures.
— doppiad_ML (@Doppiad_ML) August 31, 2022
Generated in #stablediffusion pic.twitter.com/KU3Cw25ZKV
開発
Deforum Stable Diffusion v0.2公開
※ 8/31の情報です。
色々Google Colabでツールが出ていますが、正直。
Stable Diffusion for Kirita 開発
※ 8/31の情報です。
If you want to start exploring the img2img capabilities of #stablediffusion I have created an open-source plugin for #krita pic.twitter.com/zjHBCcAJVZ
— nousr (@nousr_) August 31, 2022
KiritaはmacOS、Linux、windows対応。
kiritaはここからダウンロードできます。
AIピカソリリース
※ 8/31の情報です。
スマホアプリとしてStableDiffusionを実装した方が現れました。
AIお絵かきアプリ 「AIピカソ」をリリースしました🎉
— Toshiki Tomihira (@tommy19970714) August 31, 2022
文章を入力すると、AIが画像生成してくれるモバイルアプリです!
しかもラフ画を書くと、思った通りの絵や写真をAIが描いてくれます✏️
ぜひ使ってみてくださいー!拡散してもらえると泣きます😭
ダウンロードはこちらhttps://t.co/vmv8KoWnRF pic.twitter.com/YI1GFQET52
KREA.ai登場
Lexica.artが、現状Stable Diffusionの過去の制作物を見るのに最適でしたがこれはsaveボタンがありかなり良い印象。modifierで検索できるのでかなり優秀。しばらくこれを利用しそう。


研究
美学評価モデルを利用し、ランダムなプロンプトを美的に進化させる進化的アルゴリズムを構築。(Stable Diffusion)
Given the speed of #stablediffusion 's generation, automated image/prompt curation is becoming a necessity.
— Magnus Petersen (@Omorfiamorphism) August 30, 2022
I've been using @RiversHaveWings aesthetics rating model to build an evolutionary algorithm that evolves a random prompt population to become more aesthetic. 1/x pic.twitter.com/XLSZRzbfte
Sampler と Stepsの研究事例
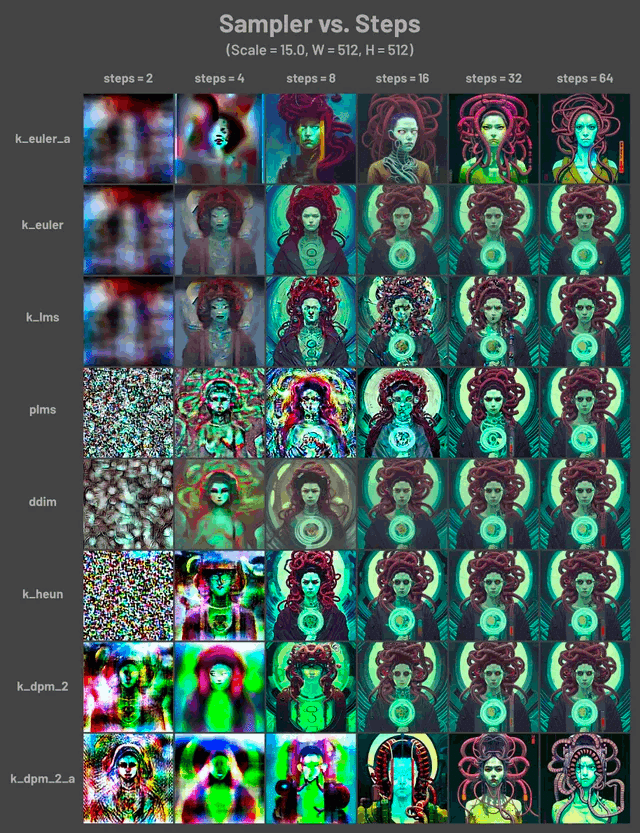
img2img&フォトバッシュ複合ワークフロー
画像生成AIのゴールは言われた通りに描き、またここ治してと話せば直してくれるいわゆる対話型を目指しているというお話を見たことがありますが、現状AIはまだまだクオリティが低い状態です。その状態の中でより思い通りのものを作られています。

ムーブメント
生成画像でアートコンペ優勝
Midjourneyで画像生成し、そのまま誰にも気づかれず優勝してしまった事例が注目が集まってます。

画像自動生成AIと著作権について
一昨日〜今日くらいまでかなりホットな話題である「mimic」。こちらに沿ってネット上では様々な議論が飛び交いました。その流れか柿沼さんがわかりやすく、情報たっぷりのブログを書いてくださっています。是非。
先日反響が大きかった「画像自動生成AIと著作権」の問題、より詳細な解説記事を書きました。
— 柿沼 太一 (@tka0120) August 31, 2022
疲れた。。。。https://t.co/ckozXuiqnm
思想
2023年のクリエイティブの求人市場
AIコンテンツ作成ツールで、一時期バズってたRunwayのCEOの方のツイート。シニアプロンプトアーティスト、モデル トレーニング アート ディレクターってなるかは分からないですが、何かしらの形で専門家が生まれると思います。
Job market for creatives, 2023:
— Cristóbal Valenzuela (@c_valenzuelab) August 31, 2022
- Senior Prompt Artist
- Generative Video Supervisor
- Model Training Art Director
- Senior Model Strategist
- Associate Dataset Curator
- Hyper-targeted Ad Director
What else?
画像生成AIの創造性
これは確かにそうですね、カメラと同じと考えると諸々の細かい設定をできる、それに詳しいということは価値がありそうだし、そこに創造性がある。
色々いじってみてるとプロンプトの設定・パラメータの調整・多数の出力結果からの選定etcが絡むので、AI生成だからと言って即創造性が無いとは言えないと思う。(写真でも「適当に1回シャッター押しただけ」と「場所や照明や画角を吟味しながら大量に撮影したものを現像して選び出す」は違うはず)
— Kenji Iguchi (@needle) September 1, 2022
最後に
いやとにかく最近..画像生成AIの注目度やばいですね。
Midjourneyでイラスト大量バズに続き、Stable Diffusionのトレンド入りから、mimmicが話題に上がったり..、ひたすら毎日ニュースがありすぎて楽しい日々です。
前書いていたnoteもお陰様で反応やコメントを頂けて嬉しかったです。
🖋 書きました。
— やまかず (@Yamkaz) August 21, 2022
やばすぎるAI画像生成サービス「Stable Diffusion」始まる。【簡単解説 & 応用 & Prompt付生成事例集】#note #stablediffusion #midjourney https://t.co/cn9aPkh4wU
Twitter、毎日製作したアートや、最新情報、検証を載せているのでよかったらフォローしてね
https://twitter.com/Yamkaz
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます