
WandBot: GPT-4 を利用したチャットサポート

本ブログ記事では、自社の製品ドキュメントやコード、過去のブログデータを活用したQ&AボットをGPT-4、Langchain、Weights & Biasesを組み合わせることで構築する方法をご紹介します。
本ブログ記事はAnish Shah, Bharat Ramanathan, Darek Kleczek, Morganによって執筆され、W&B Fully Connectedで公開された"WandBot: GPT-4 Powered Chat Support"の日本語訳です。

はじめに
大規模言語モデル(LLM) がソフトウェアエンジニアリングと機械学習の境界をますます曖昧なものにしつつある昨今、私たちは、この分野に新たに取り組もうとする皆さんに最適なツールを提供するために、この両者が交わる部分の理解を深めることが非常に大切だと考えております。そこで、この新しいワークフローとその問題点をより理解しやすくするために、独自のサポートボット「WandBot」を開発しました。
この記事では、GPT-4、Langchain、OpenAIの埋め込み、FAISSを用いたWeights & Biases(W&B)のQ&Aボットの実装について、わかりやすくご紹介します。実際に試してみたいという方は、Discord の#wandbot チャンネルで実際に運用されていますので、是非とも感想をお聞かせください。
また、WandBot を動かすために使っている実際のコードもオープンソース化しました。Githubリポジトリはこちらでご覧いただけます。皆さんと一緒にこのツールをより良いものにしていくことを楽しみにしています。
この記事では、WandBotの技術的な詳細やオリジナルの実装からのアップデートについて学べるだけでなく、DiscordやSlackなどのプラットフォームで使いやすいQ&Aボットのフロントエンドアプリケーションを作成する方法についても解説しています。これにより、シームレスな統合と幅広いアクセシビリティが実現されます。
データの操作
データ収集と前処理
当初の実装では、CharacterTextSplitter を使用してテキストを分割していました。
MarkdownTextSplitter、PythonCodeTextSplitter、NotebookTextSplitter を使用し、異なる種類のファイルにうまく対応できるようにコードを更新しました。以下にコードとその説明を示します。
from langchain.text_splitter import MarkdownTextSplitter, PythonCodeTextSplitter, NotebookTextSplitter
markdown_splitter = MarkdownTextSplitter()
python_code_splitter = PythonCodeTextSplitter()
notebook_splitter = NotebookTextSplitter()MarkdownTextSplitter:Markdownファイルを解析し処理することで、ボットがこれらのファイル内のコンテンツに関連した理解と応答を生成できるようにします。これはW&Bのドキュメンテーションを扱う際に特に役立ちます。なぜなら、その大部分がMarkdownで書かれているからです。
PythonCodeTextSplitter:Pythonのコードファイルを処理し、ボットがコードスニペットやプログラミングの概念に基づいた理解と応答を生成できるようにします。これは、W&BのAPIとそのPythonプロジェクトでの使用に関連した技術的な質問に対応するために重要です。
NotebookTextSplitter:Jupyter Notebookファイルを扱います。これらはコード、データ、ドキュメンテーションを機械学習コミュニティ内で共有するための一般的な形式です。このスプリッターは、ボットがこれらのノートブック内のコンテンツ、つまりコード、マークダウン、出力に基づいた理解と応答を生成できるようにします。
これらの専用テキストスプリッターを使用することで、Q&A ボットは様々な文書形式をより的確に理解して処理することができ、より正確で関連性のある回答につながります。
データの取り込み
前処理の後、データはLangchainフレームワークに取り込まれます。このコードでは、単純な埋め込みではなく、HydeEmbeddings を使用しています。HydeEmbeddings は、HyDE(Hypothetical Document Embeddings)という手法に基づく、より高度な埋め込みです。キーワードだけでなくChatGPT のようなLLM が生成した仮想の回答を活用して検索結果を改善しようとします。HyDEの埋め込みは、単純な埋め込みと比較して、このプロジェクトに
とって次のような実際の利点があります。
高次元:HydeEmbeddings はより高次元のベクトル空間を使用しているため、単語やフレーズ間のより微妙な関係を把握することができます。
コンテキストを認識:HydeEmbeddings は、コンテキスト情報を取り込むように設計されており、その結果、テキストの背後にある意味や意図をより的確に理解することができます。特定の質問やトピックに基づくLLM で生成された文書を使用することで、HydeEmbeddings は、信頼できるナレッジベース内の類似文書を見つけるのに役立つ関連パターンを把握できます。
堅牢性:HydeEmbeddings はノイズや曖昧さに対する耐性が高いため、複雑な言語構造や多様な文書形式の取り扱いに適しています。HyDE法では、仮想の回答を用いることで、LLM の 「幻覚(hallucination: ハルシネーション)」のリスクを軽減するのに役立ちます。これは、医療など、正確な情報が重要な、機密性の高い用途で特に役立ちます。
from langchain.embeddings import HydeEmbeddings
hyde_embeddings = HydeEmbeddings()
# Ingest data into Langchain framework using HydeEmbeddings
processed_data = []
for document in preprocessed_data:
embedding = hyde_embeddings.get_embedding(document)
processed_data.append({"text": document, "embedding": embedding})HydeEmbeddings を使用することで、Q&A ボットはファインチューニングする必要もトークン制限を超えることもなく、ナレッジベースのコンテキストをフルに活用することができ、全体的なユーザー体験が向上します。HydeEmbeddings を活用することで、Q&A ボットのパフォーマンスとテキストの理解度が向上しました。これらの埋め込みは、メタデータと共にドキュメントを作成し保存するために使用され、ボットの知識と応答生成能力の基盤を形成します。
ベクトルストアで自社ベクトルを格納する
文書埋め込みをFAISS インデックスに格納する
次に、FAISSインデックスを作成します。これは高次元データのための強力で効率的な類似性検索ライブラリで、FAISSはFacebook AI Similarity Searchの略です。
補足のコードにおいて、LangchainのFAISS クラスをサブクラス化し、検索された文書の類似度スコアも返すようにしました。これをFAISSWithScore と呼び、これを用いて文書埋め込みをFAISS インデックスに格納しました。これにより、ユーザーの質問に基づく効率的な文書検索や、類似度スコアに基づく検索文書のフィルタリングを行うことができます。また、Langchainフレームワークの変更に対応するため、ドキュメントとスコアの取得にFAISSインデックスを利用するVectorStoreRetrieverWithScoreにリトリーバーを更新しました。
faiss_index = FAISSWithScore()
retriever = VectorStoreRetrieverWithScore(faiss_index)FAISS インデックスと埋め込みをWeights & Biases Artifact に格納する
移植の容易さと効果的なバージョン管理のため、FAISS インデックスと埋め込みは、1つのWeights and Biases Artifact 内のファイルとして別々に保存されます。このアプローチでは、データへのアクセスや共有が容易にするだけでなく、LLM の進化に伴う、ストア内の利用可能なデータへの変更を追跡することも可能になります。W&B Artifact を活用することで、Q&Aボットは常に最新の状態に更新され、改善され続けることができ、ユーザーの質問に対して最も正確で関連性のある回答を提供できます。
import wandb
# Log the FAISS index and embeddings to W&B Artifacts
artifact = wandb.Artifact("faiss_index_and_embeddings", type="data")
artifact.add_file("faiss_index_file.faiss")
artifact.add_file("embeddings.npy")
run = wandb.init()
run.log_artifact(artifact)
run.finish()WandBot の作成
データセットとFAISSインデックスが整ったところで、Q&Aボットの作成に取りかかりましょう。これは、堅牢なプロンプトの設計、Q&Aパイプラインの作成、そして最終的にチャットインターフェースの開発、という三つの主要なコンポーネントから成り立っています。それぞれの順番で進めていきましょう。
LLM 用の堅牢なプロンプトの設計
言語モデルから望ましい振る舞い(と出力形式)をしっかり得られるように、コードではLangchainのChatPromptTemplate クラスを利用します。このクラスを使用すると、Q&Aボットの具体的な要件に合わせたカスタムプロンプトを設計することができます。ChatPromptTemplate を使用することで、開発者はコンテキストを提供し、望ましい回答形式を指定し、トークン制約を管理できます。これにより、モデルの出力が、関連性があり、適切に構造化されたものとなります。コードは以下のとおりです。
from langchain import ChatPromptTemplate
# Create a custom prompt for the Q&A bot
prompt_template = ChatPromptTemplate(
user_prompt="User: {question}",
assistant_prompt="Assistant: {answer}",
token_constraints={"max_length": 2048}
)Q&A パイプラインの作成
このQ&A パイプラインは、以前のVectorDBQAWithSourcesChain の代わりに、LangchainのRetrievalQAWithSourcesChainWithScore を使って作成されました。このパイプラインは、OpenAI の埋め込みとFAISS インデックスの力を活用し、効率的な文書検索を実現します。RetrievalQAWithSourcesChainWithScore を使うメリットは以下のとおりです。
検索効率の向上: FAISS インデックスとOpenAI の埋め込みを利用することで、パイプラインは大量のドキュメントを素早く検索し、関連する結果を得ることができます。
コンテキストの理解:パイプラインはHydeEmbeddings を組み込んでいるため、コンテキストをより的確に理解することができ、より正確な回答を提供することができます。
スコアリングの仕組み: RetrievalQAWithSourcesChainWithScore クラスは、システムが検索された文書の関連性をランク付けし、類似性スコアによって文書をフィルタリングできるようにする、スコアリングメカニズムも提供します。
Weights & Biases での使用:FAISS インデックスや埋め込みなどのパイプラインコンポーネントをW&B Artifact に格納することで、バージョン管理、コラボレーション、データの移植性を向上させることができます。W&B Artifact を使用することで、パイプラインの更新やチームメンバー間での共有が容易になり、Q&A ボットの継続的な改善を促進することができます。コードでは、パイプラインはrun.use_artifact メソッドを使用してアーティファクトをロードし、必要なデータとコンポーネントにアクセスするプロセスを簡素化します。
# Load FAISS index and embeddings from W&B Artifacts
run = wandb.init()
artifact = run.use_artifact("faiss_index_and_embeddings:latest")
faiss_index = FAISSWithScore.load(artifact.get_path("faiss_index_file.faiss").download())
embeddings = np.load(artifact.get_path("embeddings.npy").download())
# Create the Q&A pipeline
pipeline = RetrievalQAWithSourcesChainWithScore(
retriever=faiss_index.as_retriever(),
embeddings=embeddings,
prompt_template=prompt_template
)このパイプラインは、ユーザーの質問を処理し、データセットに格納された情報に基づいて適切な回答を生成する役割を担います。
チャットインターフェースの作成
コード内のChat クラスは、なんとチャットのインターフェースとして機能し、ユーザーの入力とモデルの回答の状態を保存するストレージを提供します。これは、進行中の会話中にコンテキストを維持するのに特に便利です。Chat クラスを利用するメリットは以下のとおりです。
インタラクティブな体験:状態を保存するストレージは、モデルがユーザーとの以前のやり取りに基づいてコンテキストに対応した応答を生成することを可能にするため、より対話的でダイナミックなチャット体験を実現します。この機能は、本当に必要な答えを得るために、質問を深く掘り下げたり、絞り込んだりするのに適しています。
柔軟性:Chat クラスは、Discord やSlack アプリケーションなど、さまざまなユーザーインターフェースで動作するように簡単に調整できるため、開発者はQ&A ボットをさまざまなプラットフォームにシームレスに統合できます。
from langchain import Chat
# Instantiate the Chat class with the Q&A pipeline
chat = Chat(pipeline)これら3つの要素を組み合わせることで、Q&A ボットはユーザーの質問に効果的に答え、Weights & Biases ドキュメントの情報を求めているユーザーに対して魅力的でインタラクティブな体験を提供できます。
モデル選択とフォールバックメカニズム
モデル選択とフォールバックメカニズムの実装は、信頼性と堅牢性のために極めて重要です。具体的には、次のような利点があります。
サービスの継続性: GPT-4 をプライマリーモデルとして、GPT-3.5 Turbo をフォールバック(代替手段)として使用することで、プライマリーモデルが利用できない場合や問題が発生した場合でも、Q&A ボットを継続的に利用することが可能です。これは、一貫したユーザー体験を維持し、ユーザーの満足度やシステムに対する信頼に悪影響を及ぼすダウンタイムを防止するために特に重要です。
パフォーマンスの最適化:GPT-4 は、自然言語理解・生成において最先端のパフォーマンスを発揮します。デフォルトでは、Q&A ボットはこのモデルを活用して、ユーザーの質問に対して最高品質の回答を提供します。しかし、GPT-3.5 Turbo は、若干性能が劣るとはいえ、高いレベルのパフォーマンスを発揮します。このフォールバックメカニズムを活用することで、プライマリーモデルが利用できない場合でも、Q&A ボットの実効性を維持できます。以下に補足します。
リソース管理:リソースの制約などの要因により、主要モデルであるGPT-4 の利用が制限される場合があります。フォールバックメカニズムを組み込むことで、Q&A ボットはGPT-3.5 Turbo にシームレスに切り替わることができ、リソースの制限による悪影響を受けることなく、ユーザーは質問に対する回答を常に受け取ることができます。
柔軟性とスケーラビリティ:フォールバックメカニズムを取り入れることで、Q&Aボットは基礎となる言語モデルやインフラの変化に対応する柔軟性を持つことができます。これにより、システムの拡張や、新しいモデルやアップデートに対応することが容易になり、ボットが自然言語処理の最新の進歩に対応できるようになります。
このように、モデルの選択とフォールバックメカニズムは、サービスの継続性を確保し、パフォーマンスを最適化し、リソースを効果的に管理し、将来の拡張性とスケーラビリティに必要な柔軟性を提供するため、Q&A ボットの設計において重要な要素となっています。
Discord やSlack にWandBot をデプロイする
Q&A ボットのバックエンドの実装が完了しましたので、いよいよDiscord とSlack にボットをデプロイします。本来の大目的はドキュメントにもっとアクセスしやすくすることなのですが、ドキュメント以外の部分にも簡単にアクセスできるようにすることで、本来の目的をより達成しやすくなります。
Discord との連携
Q&A ボットをDiscord と統合するために、まずDiscord API と対話するPython スクリプトを作成する必要があります。discord.py ライブラリは、ボットをDiscord に接続するプロセスを簡略化するため、この目的のために広く使用されているツールです。Discord 統合のコードは、次のように構造化できます
必要なライブラリをインポートする:discordライブラリと、Q&A ボット実装のChat クラスなど、必要なライブラリをインポートします。
import discord
from qa_bot import Chat2. チャットオブジェクトを初期化する:ユーザーの入力とモデルの回答を管理するために、Chat クラスのインスタンスを作成します。
chat = Chat(**kwargs)3. ボットの振る舞いを定義する:ユーザーからメッセージを受信したときにトリガーする非同期関数を作成します。この関数は、Chat インスタンスを使用してメッセージを処理し、ユーザーに回答を返します。
async def on_message(message):
if message.author == client.user:
return
response = chat.handle_message(message.content)
await message.channel.send(response)4. ボットをDiscord に接続する:新しい discord.Client インスタンスを作成し、イベントハンドラとして on_message 関数を割り当て、Discord Developer Portal から取得したボットトークンを使用してボットを起動します。
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user} has connected to Discord!')
client.run('your_bot_token')Slack との連携
Slackとの統合には、slack-boltライブラリを使用することができます。これにより、Q&Aボットの接続プロセスが簡単になります。コードは次のとおりです。
必要なライブラリをインポートする:slack_bolt ライブラリとそのコンポーネント、およびQ&A ボット実装のChat クラスなど、必要なライブラリをインポートします。
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
from qa_bot import Chat2. チャットオブジェクトを初期化する:ユーザーの入力とモデルの回答を管理するために、Chat クラスのインスタンスを作成します。
chat = Chat(**kwargs)3. ボットの振る舞いを定義する:ユーザーからメッセージを受信したときにトリガーする関数を作成します。この関数は、Chat インスタンスを使用してメッセージを処理し、ユーザーに回答を返します。
@app.event("app_mention") ...
def command_handler(body, say):
message = body['event']['text']
response = chat.handle_message(message)
say(response)4. ボットをSlack に接続する:新しいAppインスタンスを作成し、Slack Developer Portal から取得したSlack アプリトークンとボットトークンを使用してボットを起動します。
app = App()
handler = SocketModeHandler(app, 'your_app_token')
handler.start()Q&A ボットをDiscord とSlack の両方に統合することで、ユーザーは、どちらのコミュニケーションプラットフォームを使用している場合でも、Weights & Biases ドキュメントの豊富な情報に容易にアクセスできます。これにより、Weights & Biases ツールセットに関するサポートを求めるユーザーに対して、より広範囲で魅力的なエクスペリエンスを提供できます。
Weights & Biases Stream Table を使ったロギングと解析
Discord とSlack との両アプリケーションは、Q&A ボットとユーザーのやりとりをWeights & Biases StreamTable に記録するように設計されています。この統合により、パイプラインの分析、デバッグ、継続的な改善において次のような利点がもたらされます。
モデルの分析:ユーザーの質問とボットの回答を記録することで、チームはモデルのパフォーマンスを分析し、改善すべき箇所を特定し、モデルがユーザーのニーズにどれだけ応えているかについての洞察を得ることができます。この情報は、パフォーマンスの改善とユーザー満足度の向上のために、モデルやその基礎となるコンポーネントを繰り返し改良するために使用することができます。
デバッグ:W&B StreamTable は、ユーザーとのインタラクションの中心的なリポジトリとして機能し、開発者はボットの動作中に発生した問題を特定し診断することができます。特に、実際の使用時に起こりうるエッジケースや予期せぬ振る舞いを把握し、解決するために有効です。
下流評価タスク:記録されたデータは、プロンプトの改良、パイプラインの構成要素の調整、あるいは特定のユーザー要件に基づく新しいモデルのトレーニングなど、下流の評価タスクに利用することができます。この継続的なフィードバックループにより、開発チームは実際のユーザーとの対話に応じてQ&A ボットを調整および改善することができます。
モニタリングとレポーティング: W&B StreamTable は、ボットのパフォーマンスを時間とともに監視するための視覚的でアクセスしやすいプラットフォームを提供し、チームが改善を追跡し、トレンドを見つけ出し、必要に応じてレポートを生成することができます。
Weights & Biases StreamTable をQ&A ボットのDiscord やSlack アプリケーションと連携して活用することで、開発チームは、進化し続けるユーザーのニーズに対応した、堅牢でダイナミック、かつ継続的に改善されるパイプラインを維持できます。
Q&A ボットの評価
Q&Aボットのパフォーマンスを評価するために、検索精度、文字列の類似度、そしてモデルが生成した回答の正確さを評価するメトリクスの組み合わせを使用します。この評価を実行するためには、次の手順を実行します。
評価用データセットを読み込む:Weights & Biases Artifact として保存されている評価用データセット(一連の質問、元の回答、ドキュメントソースを含む)を利用します。
チャットモデルをテストする:評価データセット内の各質問について、チャットモデルを使用して回答と、取得されたドキュメントとそのスコアを生成します。
検索精度を計算する:検索された文書に元の文書が存在するかどうかをチェックすることで、検索精度を評価します。
文字列の類似度を計算する:FuzzyWuzzy ライブラリを使用して、チャットボットが生成した回答と元の回答との類似度を計算します。この類似度スコアは0~100 の範囲で、スコアが高いほど類似度が高いことを示します。
チャットボットの回答を等級付けする:言語モデルを使って、チャットボットの回答を元の回答と比較し評価します。言語モデルは、チャットボットの回答を「正しい(CORRECT)」または「間違っている(INCORRECT)」と評価するよう指示されます。
具体的には、wandbot の場合、以下のようなプロセスに従いパフォーマンスを評価しました。
W&B ドキュメントの各コードスニペットについて、ユーザーの質問をシミュレートした大規模なデータセットを生成する。このスニペットは、質問と回答の両方を提供する「理想的な回答」として機能します。
既存のWandbot のコードとアルゴリズムを活用し、各質問に対する回答を生成する。
GPT-3.5 のモデルベースのアプローチを用いて自動評価を実施する。
MLE(機械学習エンジニア)によって一部の質問とモデルの回答に対する人間によるラベル付けを行いました。専門家が質問または「理想的な回答」が間違っていると評価した例を除外しました。
このプロセスに基づき、W&B の専門家の判断では、モデル回答の精度は74%と算出されました。相関性がある一方で、モデルベースの精度評価では偽陰性が多く、自動化された(モデルベースの)評価が良い結果をもたらすようにするために、さらなる検討が必要です。
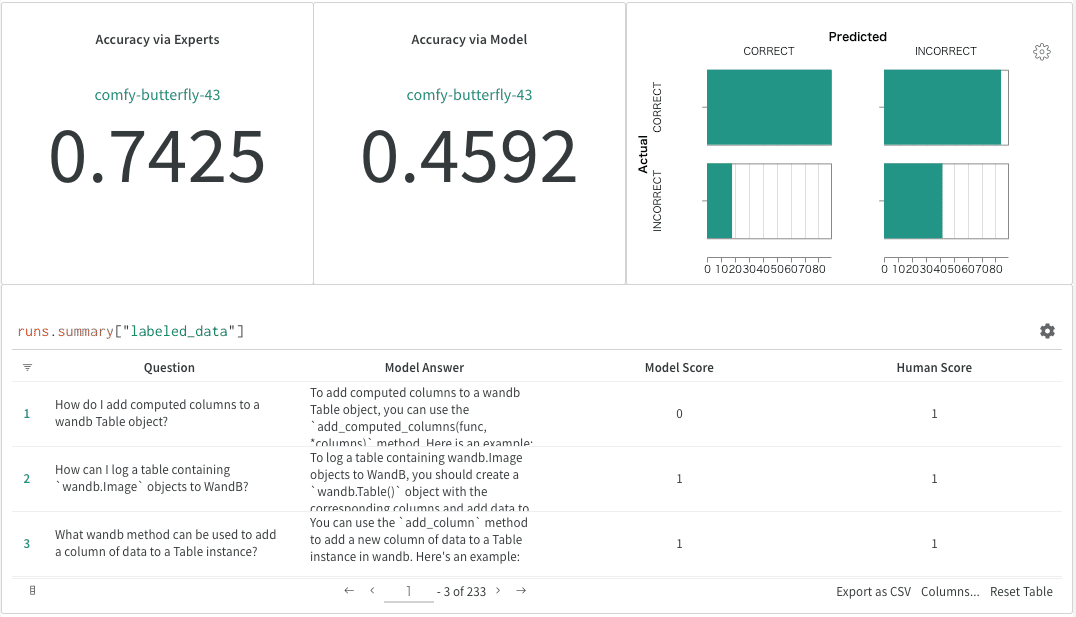
これらのメトリクスを用いてQ&Aボットを評価することで、モデルのパフォーマンスに関する洞察を得るとともに、改善すべき点を特定することができます。この評価プロセスを必要に応じて繰り返すことで、チャットボットの進捗を把握し、ユーザーに正確で関連性のある情報を提供し続けることができます。
まとめ
以上がQ&Aボットの作り方の概要です。次のステップとして、Q&Aボットの他のコミュニケーションプラットフォームへの拡張、継続的なモデル改善のためのアクティブラーニングの組み込み、ユーザーエクスペリエンスのパーソナライズ、複数の言語とドメインのサポートの拡張などが、考えられる改善と将来の作業として挙げられます。これらの方法を模索することで、Q&Aボットの機能と適用性をさらに強化し、それぞれの分野で情報やサポートを求めるユーザーにとって、より価値のあるツールとなります。
あなた自身の機械学習プロジェクトでWeights & Biasesを活用することに興味がある場合は、無料アカウントにサインアップし、モデルを簡単に構築、追跡、改善するのに役立つ多彩な機能と能力を探索してみてください。
そしてもし私たちのボットを試してみたいなら、もう一度リンクをここに貼りますので是非トライしてみてください: wandb.me/wandbot

この記事が気に入ったらサポートをしてみませんか?