
PyTorchとWeights & Biasesを使用したニューラルネットワークの可視化とデバッグ

この記事はVisualizing and Debugging Neural Networks with PyTorch and Weights & Biasesを日本語訳したものになります。

この投稿では、ニューラルネットワークの低パフォーマンスの原因と、勾配やモデルトレーニングに関連するその他のパラメーターを可視化することで、この問題をデバッグする方法を見ていきます。勾配消失と勾配爆発の問題、およびこの問題に対処する方法についても考察します。
最後に、適切な重みの初期化が役立つ理由や、これを正しく行う方法を考察し、ドロップアウトやバッチ正規化などの正則化化手法がモデルのパフォーマンスにどのように影響を及ぼすかを見ていきます。
ニューラルネットワークのバグはどこから生じる?
ニューラルネットワークのバグは発見するのが非常に困難です。なぜなら
その理由は、コードが決してクラッシュせず、例外を引き起こさず、速度が低下しないため。
それでもネットワークはトレーニング可能で、損失が減少するため。
値は数時間後に収束しながらも、非常に悪い結果になるためです。
このトピックを掘り下げて調べたい場合は、Andrej KarparthyによるA Recipe for Training Neural Networks(ニューラルネットワークをトレーニングするための方策)を読むことを強くお勧めします。ニューラルネットワークをより良くデバッグするにはどうすれば良いでしょうか?ニューラルネットワークをデバッグする際に従うべき決定的な手順はありません。しかし、以下はコンセプトのリストですが、ニューラルネットワークのデバッグの際に適切に実施すれば役立つでしょう。
ニューラルネットワークのデバッグを試した方はこちら
モデルに入力するデータのデバッグ
入力データ
私たちはデータを理解する必要があります。たとえばデータのタイプ、データの保存方法、ターゲットクラスのバランス、特徴量、データの尺度の一貫性などです。
データの前処理
データの前処理について考え、ドメイン知識をそれに組み込む必要があります。データの前処理が必要になる状況は通常2つあります:
データクリーニング:アーティファクトと呼ばれるデータの一部取り除いたされた場合に、目的のタスクを簡単に達成できることがあります。
データオーグメンテーション:トレーニングデータに限りがある場合、各データサンプルをさまざまな方法で変換して、モデルのトレーニングに使うことができます(たとえば、画像のスケーリング、シフト、回転)。このブログは、不適切なデータ前処理によって生じた問題は考察しません。
小規模データセットでの過学習
データサンプルが50~60の小規模データセットである場合、モデルはすぐに過学習します。すなわち、2~5エポックで、損失はゼロになります。モデルが逆に過学習していない場合、モデルが正しく設計されていないか、損失の選択が正しくないことが原因として考えられます。おそらくマルチクラス分類を試みているにもかかわらず、出力層がシグモイド関数で活性化されているのではないでしょうか。これらのエラーは見逃しがちです。これを実証しているノートブックをこちらでご覧ください。このようなエラーを回避するにはどうすれば良いでしょうか?読み進めていきましょう。
モデルアーキテクチャーのデバッグ
小規模アーキテクチャーで開始する
高度な正規化ツールやスケジューラーの使用はやり過ぎかもしれません。エラーが発生した場合、小規模ネットワークをデバッグする方が簡単ですので、まずは小規模ネットワークから始めましょう。一般的なエラーには、ある層から別の層にテンソルを渡し忘れること、入力と出力のニューロンの比率が不整合であることなどがあります。
学習済みモデル(重み)
モデルアーキテクチャーが、VGG、Resnet、Inceptionなどの標準的なバックボーンの上に構築されている場合、標準的なデータセット上で学習済みの重みを使うことができるので、もしできれば作業しているデータセット上で見つけてください。最近の興味深い論文Transfusion: Understanding Transfer Learning for Medical Imaging(輸血:医用画像向けの転移学習の理解)では、学習済みのImageNetモデルから最初のいくつかの層を使うことで、医用画像モデルのトレーニング速度と最終的な精度を改善できることが示されています。
したがって、解決しようとしている問題のドメイン内になくても、汎用的な学習済みモデルを使うべきだと言えます。ただし、この論文では、医用画像に適用された場合、ImageNetの学習済みモデルからの改善の量がそれほど大きくないとも述べています。。そのため、初期化が良いということが保証されるわけでもありません。詳細については、Jeremy Howardによるこの 素晴らしいブログ投稿を読んでみてください。
損失のデバッグ
適切な損失関数の選択
まず、所定のタスクに対して、必ず適切な損失関数を使用してください。マルチクラス分類器については、バイナリ損失関数は精度の改善に役立たないため、カテゴリカルクロスエントロピーが適切な選択肢です。
理論的損失の判断
モデルがランダムに推測を開始した場合(つまり、事前学習モデルを使用していない場合)、初期損失が期待損失に近いかどうか確認します。その他の打ち手についてはこちらを参照してください。
学習率
このパラメーターは、損失関数の最小値に向かって各イテレーションでのステップサイズを決定します。損失関数が急であるか滑らかであるかに応じて学習率を調整することができます。しかし、これは時間がかかり、大量のリソースを消費するステップになることがあります。最適な学習率を自動的に見つけることはできるでしょうか?
Leslie N. Smithは非常に短い時間と最小限のリソースで学習率を体系的に見つけるための非常に賢明でシンプルな方法を提案しました。必要なものはモデルとトレーニングセットだけです。モデルは小さい学習率で初期化され、データのバッチでトレーニングされます。関連する損失と学習率が保存されます。その後、学習率は線形的にまたは指数的に増加し、この学習率でモデルが更新されます。これは非常に高い(最大の)学習率に達するまで繰り返されます。
このノートブックでは、PyTorch上でこのアプローチが実装されています。こちらの例ではクラスLRfinderが実装し、モデルの最適な学習率を自動的に見つけています。なお、ここではwandb.log()を使って、学習率と対応する損失をログしています。
if logwandb:
wandb.log({'lr': lr_schedule.get_lr()[0], 'loss': loss})
lr_finder = LRFinder(net, optimizer, device)
lr_finder.range_test(trainloader, end_lr=10, num_iter=100, logwandb=True)
ここでW&B runページに移動して、LR曲線の最小値を見つけることができます。これを学習率として使って、トレーニングセットのバッチ全体でトレーニングします。
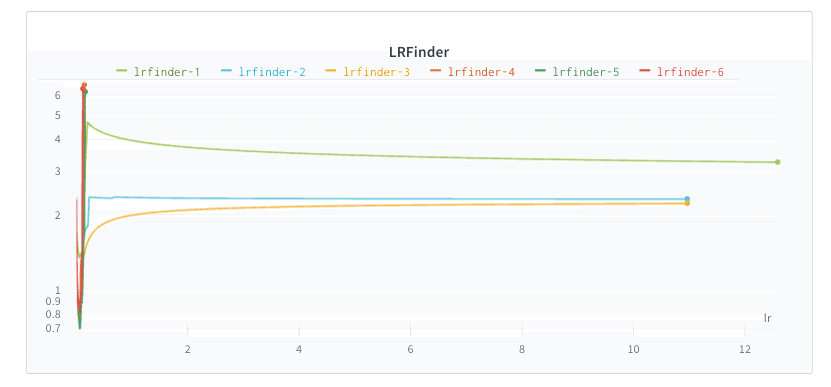
学習率が低すぎると、モデルは何も学習することができず、停滞したままになります。学習率が十分な大きさの場合、学習を開始した後lossに急激な下降が見られますが、曲線の最小値を実現する最適な学習率を見つける必要があります。
Kerasを使ってモデルを構築している場合、PyImageSearchによるこのブログに示されている学習率ファインダーを利用することができます。TensorFlow 2.0での実装に関するこのブログ投稿も参照してください。
活性化関数のデバッグ
勾配消失の問題
10年前はシグモイド/タンジェント活性化関数を使用すると、深いニューラルネットワークのトレーニングに大きな問題がありました。この問題を理解するためには、フィードフォワードとバックプロパゲーションのアルゴリズム、および勾配ベースの最適化に関する理解が求められます。この問題について、こちらの動画・ブログが参考になります。簡単に言えば、バックプロパゲーションが実行されると、各層の重みに関して損失の勾配が計算され、ネットワーク内で後方に移動すると勾配が小さくなる傾向があります。各層の勾配は、微分の連鎖則を使って計算できます。シグモイドの導関数は数値的に0~0.25の範囲にあるので、計算された勾配は小さく、ほとんど重みの更新が行われません。この問題によって、モデルは収束できない、または収束に長時間かかります。
ネットワークをデバッグする際の最も簡単な方法は、勾配を可視化することです。PyTorchを使ってネットワークを構築している場合、W&Bは各層の勾配を自動的に可視化します。こちらのノートブックを参考にしてください。
ノートブックには、NetwithIssueとNetの2つのモデルが用意されています。最初のモデルは、各層に対してシグモイドを活性化関数として使用します。後者はReluを使います。両方のモデルの最後の層はsoftmaxを使用しています。
net = Net().to(device)
optimizer = optim.Adam(net.parameters())
wandb.init(project='pytorchw_b')
wandb.watch(net, log='all')
for epoch in range(10):
train(net, device, trainloader, optimizer, epoch)
test(net, device, testloader, classes)
print('Finished Training')W&BはPyTorchとのインテグレーションを提供しており、例えばwatchを呼び出してPyTorchモデルで渡すことで、自動的に勾配を記録し、ネットワークトポロジを保存することができます。パラメーター値のヒストグラムも記録したい場合は、log='all'引数をwatchメソッドに渡すことでそれが実現できます。
下記の実装では、モデルは手書きのMNISTデータセットに対して、40エポックのトレーニングが行われました。これは最終的に、トレーニング-テストのaccuracyが80%を超える精度で収束しました。ほとんどのエポックで勾配がゼロであることがわかります。以下の勾配プロットを見るには、wandb内でプロジェクト内のrunをクリックしてから、Gradientsセクションをクリックします。

ReLUの問題
正規化線形関数(ReLU)は特効薬ではありません。というのは、この関数はゼロ未満の値を与えると「死んでしまう」ためです。短時間のトレーニング内でニューロンの多くが死んだ場合、ネットワークのかなりの部分で学習が停止する可能性があります。このような状況では、最初の重みをよく調べるか、重みに小さな初期バイアスを追加してみてください。これが上手くいかない場合、MobileNetV2論文に示されているように、Maxout、Leaky ReLUおよびReLU6を試してみましょう
勾配爆発の問題
後続の層が最初の層よりも学習率が遅い場合に、この問題が発生します。初期の層が、後続の層よりも学習率が遅い勾配消失の問題とは対照的です。層を通して後方に移動する時に、勾配が指数関数的に大きくなる場合に、この問題が発生します。実際、勾配が爆発すると、数値のオーバーフローによって勾配がNaNになる場合があります。あるいは、トレーニングの損失曲線に不規則な振動が発生することもあります。勾配消失の場合、重みの更新は非常に小さく、勾配爆発の場合、更新は非常に大きくなります。このため、極小値が見逃され、モデルは収束しません。この問題については、こちらの動画・ブログを参考にしてください。
勾配爆発の場合の、勾配の可視化を試してみましょう。このノートブックをこちらでチェックしてください。ここでは、爆発するように、意図的に大きい100の値で重みを初期化しました。
class NetforExplode(nn.Module):
def __init__(self):
super(NetforExplode, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv1.weight.data.fill_(100)
self.conv1.bias.data.fill_(-100)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv2.weight.data.fill_(100)
self.conv2.bias.data.fill_(-100)
self.fc1 = nn.Linear(9216, 128)
self.fc1.weight.data.fill_(100)
self.fc1.bias.data.fill_(-100)
self.fc2 = nn.Linear(128, 10)
self.fc2.weight.data.fill_(100)
self.fc2.bias.data.fill_(-100)以下のプロット内の勾配がどのように指数関数的に増加し、後方に移動しているかに注目してください。conv1の勾配値は10^7のオーダーであり、conv2は10^5です。不適切な重み初期化が、この問題の原因の1つになることがあります。
勾配爆発は通常、CNNベースのアーキテクチャーでは発生しません。これはむしろ、Recurrent NN(回帰型ニューラルネットワーク)で遭遇する問題です。こちらのスレッドで詳細なインサイトをチェックしてください。勾配爆発によって生じた数字的な不安定のために、損失としてNaNが得られる場合があります。こちらのノートブックはこの問題を実証しています。
この問題に関しては以下の2つのシンプルな方法があります
勾配スケーリング
勾配クリッピング
こちらのノートブックでは勾配クリッピングを使ってこの問題を克服しています。勾配クリッピングは勾配を「切り取る」か、または勾配をしきい値までに制限して、勾配が大きくなり過ぎるのを防ぎます。PyTorchでは、1行のコードでこれを実行できます。
torch.nn.utils.clip_grad_norm_(model.parameters(), 4.0)ここで4.0はしきい値です。この値は私のデモユースケースで上手くいきました。ノートブックでtrainModified関数をチェックして、実装をご覧ください。

重み初期化のデバッグ
これは、ニューラルネットワークのトレーニングの最も重要な側面の1つです。画像分類、センチメント分析、または囲碁などの問題は、決定的アルゴリズムを使って解決できません。非決定的アルゴリズムを使って、このような問題を解決する必要があります。これらのアルゴリズムは、アルゴリズムの実行中に決定を行う際、ランダム要素を使います。これらのアルゴリズムは、ランダムネスを慎重に利用します。アーティフィシャルニューラルネットワークは、確率的勾配降下法と呼ばれる確率最適化アルゴリズムを使ってトレーニングされます。ニューラルネットワークのトレーニングは、単純に「良い」解を探す非決定的な探索です。
検索プロセス(トレーニング)が展開するにつれて、検索空間の望ましくない領域に行き詰まるリスクがあります。行き詰まって「良くない」ソリューションを返すという考えは、「局所最適に行き詰まる」と呼ばれます。重みの初期化は検索問題にランダム性を導入する一つの方法です。このランダムネスは最初に取り込まれます。トレーニングに、shuffle=Trueとともにミニバッチを使用することは、検索の進行中にランダムネスを組み込むためのもう1つの方法です。基礎となる概念の詳細については、、こちらのブログをご覧ください。
優れた初期化には多数のメリットがあります。ネットワークが、勾配ベースの最適化アルゴリズム(問題解決への1つの鍵)に対して大域的最小値を達成するのに役立ちます。これは勾配消失/勾配爆発の問題を防ぎます。良い初期化は、トレーニング時間も加速します。このブログは、重みの初期化の背後にある基本的な概念をうまく説明しています。
初期化メソッドの方法は、活性化関数によって異なります。初期化の詳細を学ぶには、こちらの記事をお読みください。
ReLUまたはLeaky ReLUを使う場合は、He初期化(Kaiming initializationとも呼ばれる)を使用します。
SELUまたはELUを使用う場合は、LeCun初期化を使用します。
SoftmaxまたはTanhを使う場合は、Glorot初期化(Xavier初期化とも呼ばれる)を使用します。
多くの初期化メソッドには、一様分布および正規分布の特色があります。詳細は、このPyTorchドキュメントをご覧ください。
PyTorchでどのように重みを初期化できるかを確認するには、こちらのノートブックをチェックしてください。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 1)
torch.nn.init.kaiming_uniform_(self.conv1.weight, mode='fan_in', nonlinearity='relu')
self.conv2 = nn.Conv2d(32, 32, 3, 1)
torch.nn.init.kaiming_uniform_(self.conv2.weight, mode='fan_in', nonlinearity='relu')
self.conv3 = nn.Conv2d(32, 64, 3, 1)
torch.nn.init.kaiming_uniform_(self.conv3.weight, mode='fan_in', nonlinearity='relu')
self.conv4 = nn.Conv2d(64, 64, 3, 1)
torch.nn.init.kaiming_uniform_(self.conv4.weight, mode='fan_in', nonlinearity='relu')
self.pool1 = torch.nn.MaxPool2d(2)
self.pool2 = torch.nn.MaxPool2d(2)
self.fc1 = nn.Linear(1600, 512)
self.fc2 = nn.Linear(512, 128)
self.fc3 = nn.Linear(128, 10)kaiming_uniformを使って層がどのように初期化されたかに注目してください。このモデルは過学習していることに気づくでしょう。モデルを単純化することで、この問題を簡単に克服できます。

正則化のデバッグ
ドロップアウト
ドロップアウトは、過学習の問題を回避するために、ニューラルネットワーク内のいくつかのニューロンをランダムに「落とす」または「無効化する」正則化の手法です。トレーニング中、層内の一部のニューロンは、ドロップアウトが適用された後「オフ」になります。よりパラメーターが少ない(シンプルなモデル)ニューラルネットワークのアンサンブルでは、過学習が減少します。ネットワークのスナップショットアンサンブルに反して、トレーニングの計算や、複数モデルのメンテナンスにかかる追加費用はかかりません。これはノイズをニューラルネットワークに取り入れて、ノイズに対処できるように、適切に一般化する方法を学習させます。
ドロップアウトを実施して、どのようにモデルパフォーマンスに影響を与えるか見てみましょう。こちらのノートブックで、バッチ正規化とドロップアウトをPyTorchでどのように利用できるかを確認してください。ベースモデルで開始し、この調査のベンチマークを設定しました。実装されたアーキテクチャーはシンプルで、過学習をもたらします。
以下のプロットで、run base_modelテストに対して損失が次第に増加するのが分かります。それから、Convブロックの後に、0.5のドロップ速度でドロップアウト層を適用しました。この 層をPyTorchで初期化するために、torch.nnのDropoutメソッドを呼び出します。
self.drop = torch.nn.Dropout()
ドロップアウトは過学習を防ぎましたが(以下のチャート内のdropout_model runを探してください)、モデルは期待ほど速く収束しませんでした。つまり、アンサンブルネットワークでは学習により時間がかかります。ドロップアウトのコンテキストでは、学習中にすべてのニューロンが利用できるわけではありません。

バッチ正則化
バッチ正規化は、最適化を改善するための手法です。学習アルゴリズムが振動しないようにするため、トレーニング前に入力データを正規化するのが良い方法です。1つの層の出力は、次の層への入力であると言えます。入力として使用する前にこの出力を正規化できれば、学習プロセスを安定させることができます。これによって、ディープネットワークのトレーニングに必要なトレーニングエポックの数が大幅に減少します。バッチ正規化によって、正規化がモデルアーキテクチャーの一部になり、トレーニング中にミニバッチ上で実行されます。バッチ正規化によって、はるかに高い学習率の使用も可能になり、私たちは初期化についてそれほど慎重になる必要がなくなります。
この層をPyTorchで初期化するには、torch.nnのBatchNorm2dメソッドを呼び出します。
self.bn = torch.nn.BatchNorm2d(32)バッチ正規化では、モデルを収束するために使用するステップ数が減りました(以下のプロットでrun batch_normを探してください)。モデルはシンプルなので、過学習を回避できませんでした。
これら両方の層を同時に使ってみましょう。BNとドロップアウトを同時に使っている場合、この順番に従ってください(詳細なインサイトについては、この論文をご覧ください)。
CONV/FC -> BatchNorm -> ReLu(またはその他の活性化) -> ドロップアウト -> CONV/FC
以下の bn_dropでは、ドロップアウトとバッチ正規化を両方使うことで、モデルがより速く収束される一方、過学習が排除されているのが分かります。
大規模なデータセットがある場合、最適化をうまく行うことが重要であり、正則化を適切に行うよりも、最適化を適切に行うことが重要です。。大規模データセットではバッチ正規化はより重要です。もちろん、バッチ正規化とドロップアウトを同時に両方使うことはできます。バッチ正規化は正規化ツールとしても機能しますが、場合によってはドロップアウトの必要性がなくなります。

最後に
このブログが、機械学習コミュニティの皆さんにとって役立つことを願っています。私は、このトピックのより深い理解のために、自分自身のインサイトと、たくさんの優れた文献をご紹介しました。ニューラルネットワークのデバッグの最も重要な側面は、後で再現できるように実験を追跡することです。実験の追跡に関して言えば、Weights & Biasesは非常に便利です。実験の可視化に関するあらゆる最新の方法によって、日々簡単になっています。
この機会を与えてくださったLavanyaに感謝いたします。私はブログ作成の過程で多くのことを学びました。また、日頃ご指導いただいているSayak Paul氏に感謝いたします。
最後に、その他の有用な記事を紹介します。
『Checklist for debugging neural networks(ニューラルネットワークをデバッグする際のチェックリスト)』の記事は、次に読む記事として良いでしょう。
ニューラルネットワークの単体テストは簡単ではありません。この記事では、how to unit test machine learning code (機械学習コードの単体テスト方法)について考察します。
Why are deep neural networks hard to train?(ディープニューラルネットワークのトレーニングが難しい理由)を読むことをお勧めします。
勾配クリッピングの詳細な説明については、how to avoid exploding gradients in neural networks with gradient clipping?(勾配クリッピングで、ニューラルネットワークでの勾配爆発を回避する方法)をお読みください。
The effects of weight initialization on neural nets(ニューラルネットワークでの重み初期化の効果)。重み初期化のさまざまな効果について詳細に論じられています。

この記事が気に入ったらサポートをしてみませんか?