
WandB Sweeps on LaunchのOptuna連携によるハイパーパラメータ最適化

本記事はこちらの記事を公式アカウントに再配置したものです。

こんにちは。Weights & Biases Japanの山本です。今回はWeights & Biases (wandb) のLaunch機能とOptuna連携によるモデルのハイパーパラメータ最適化についてご紹介したいと思います。このLaunchとOptunaの連携によって、普段何気なく行なっている実験が自動的にJobとしてキャプチャされ、それをLaunchによってボタン一つでGPUクラスタを含む任意の環境に展開し、Optunaに実装されている多様で高度かつ効率的なアルゴリズムを用いてシームレスに最適化することができるようになります。
はじめに
Weights & Biasesを用いて機械学習の実験のトラッキングを行うと、リアルタイムにモデルの学習状況をダッシュボード上で把握できるだけでなく、実験に関する様々な情報が自動的にキャプチャされており、その再現性を担保しています。これには実行されたコードやそれが紐づくGitのリポジトリとコミット、そこから差分が生じている場合にはそのパッチ、さらには依存関係にあるライブラリのバージョンをfixするためのrequirements.txtなどが含まれます。そして、これらは単に実験の再現性のためだけではなく、パラメータの設定を変えて追加実験を行うためにも有用で、W&B Launchはこれをボタン一つで可能にしてくれる機能です。さらに、LaunchとOptunaの連携機能が実装されましたので、何気なく行なった実験が自動的にジョブとしてキャプチャされており、それをLaunch上のOptunaに投げることでボタン一つでモデルの最適化までできてしまうのです。
やはり、実際にやってみるのが一番わかりやすいと思いますので、以下では、KaggleのHungry Geeseコンペを題材にゲームエージェントの模倣学習で"Optuna on Launch"による最適化をしていきたいと思います。今回のデモプロジェクトのコードはこちらです。
WandBによる実験のトラッキングとコードキャプチャ
Hungry Geeseはいわゆるヘビゲームを多人数プレイに拡張したゲームで、エサを食べて体を成長させつつ、自分や対戦相手への衝突を避けて自身の長さと生存期間を競うゲームです。ゲームそのものの詳細については、コンペサイトや参加者のブログ記事などをご参照ください。ここでは盤面の状況を画像に見立てて入力し、次の一手として東西南北どちらに進むべきかを出力する畳み込みニューラルネットワーク (CNN) を既存のプレイデータから学習していきます。まずはデフォルトの条件でエイヤで動かしてみましょう。
python training.pytraining.pyを実行するとWandBのArtifactとして公開されているエピソード(=棋譜)がダウンロードされ、jsonからnumpyのarrayに変換されてCNNの学習が始まります。学習中は検証損失やベンチマークエージェントに対する勝率、推論速度、対戦のGIFアニメなどがトラッキングされてWandBサーバ上に集約・可視化され、リアルタイムにモニタリングが可能になります。lossや勝率だけでなく、実際の対戦風景を随時確認できるので、例えば同じ負けるにしても何に失敗して負けたのかなど、学習の進行状況に対するより深い洞察を得られるでしょう。

Launchによるジョブの実行
ここでプロジェクト画面左側のJobs > Version detailsを見ると、今回の実行がJobとして自動的にキャプチャされており、実験を再現するための諸元がまとめられていることがわかります。
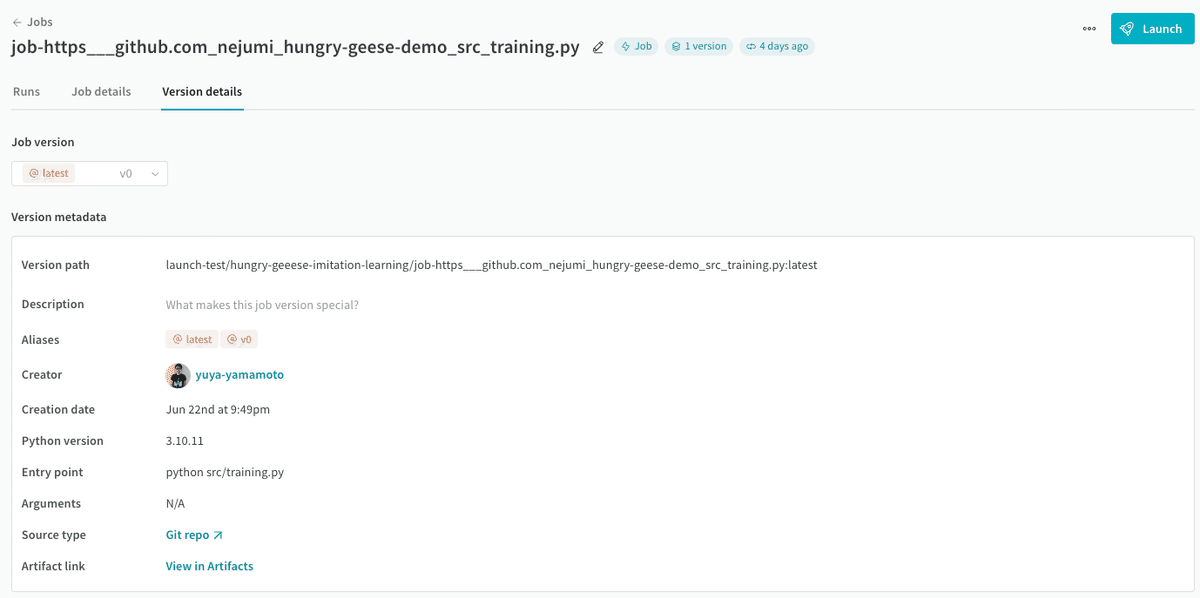

では、このジョブを設定を少しだけ変えてLaunchキューに投げてみましょう。画面右上のLaunchボタンをクリックしてQueueから対象キューを選択します。キューは事前に作成しておき、実行環境でLaunch Agentを走らせておきます(Link)。ここではUI上からConfigを設定して実行します。Overrides欄をお好みで編集してLaunch nowボタンをクリックして開始しましょう。すぐに実行され、結果がダッシュボード上に追加されます。

Sweeps on LaunchのOptuna連携によるハイパーパラメータ最適化
さらに、Launchにジョブを投げる際に手動でパラメータを変えていくのは効率が良くありませんので、Sweepsによって自動的に行いましょう。この際、WandBにビルドインの従来の最適化アルゴリズムを用いることもできるのですが、ここでは代わりにOptunaを呼び出して実行します。Optunaを用いることで多様な最適化アルゴリズムや枝刈りによる効率化など、より高度な最適化が可能になります。WandBとOptunaの連携自体は従来からありましたが、Launch機能との連携が追加されたことでより実践的かつスケーラブルな使い方ができるようになりました。まずは以下のように、最適化の対象とする指標と探索空間をyamlに定義します(jobの名前などはご自身のものを設定してください。また、以下は適当に値を振っているだけですので実際には目的に応じて適切に設定してください。)。
# optuna_config_hungry_geese.yaml
description: optuna on launch demo
# a basic training job to run
job: your-entity/your-project/job-https___github.com_nejumi_hungry-geese-demo_src_training.py:latest
run_cap: 5
metric:
name: val_loss
goal: minimize
scheduler:
job: wandb/sweep-jobs/job-optuna-sweep-scheduler:latest
resource: local-container # required for scheduler jobs sourced from images
num_workers: 1 # number of concurrent runs
settings:
sampler:
type: TPESampler
n_startup_trials: 3
pruner:
type: PercentilePruner
args:
percentile: 25.0 # kill 75% of runs
n_warmup_steps: 10 # pruning disabled for first x steps
parameters:
data_folder:
values:
- ./episodes
distribution: categorical
chunk_size:
max: 3000
min: 100
distribution: int_uniform
batch_size:
max: 2048
min: 64
distribution: int_uniform
chunk_num:
max: 11
min: 1
distribution: int_uniform
n_epochs:
max: 11
min: 1
distribution: int_uniform
project:
values:
- hungry-geeese-imitation-learning
distribution: categorical
filters:
max: 128
min: 4
distribution: int_uniform
layers:
max: 64
min: 4
distribution: int_uniformなお、目的関数は自動的にキャプチャされたジョブ自体とその中で既にトラックしている評価指標がその役割を果たしますので、これ以上の設定は不要です。あとは以下のように実行するだけです。
wandb launch-sweep optuna_config_hungry_geese.yaml -q "your-queue-name" -p your-project-name -e your-entity-name時間経過とともにより良いパラメータが見つかっていく様子や、ハイパーパラメータの変数重要度、変数同士のパラレルプロットなどを確認することができます。今回はモデルアーキテクチャに関してはフィルタの数が効いていることがわかりました。今回は既存のエピソードを用いた模倣学習(教師あり学習)を行いましたが、この結果を強化学習を行う際の初期エージェントに設定し、更なる学習を行うことでより強力なエージェントに育てることもできるでしょう。

まとめ
以上、ゲームエージェントの模倣学習をWandBでトラックし、さらにSweeps on LaunchのOptuna連携を用いることで、ハイパーパラメータの最適化を行うことができました。Optuna連携ではより多様な最適化アルゴリズムや枝刈り機能の恩恵を受けることができますので、モデル開発の更なる効率化が期待できます。なお、Optunaといえば多目的最適化ですが、こちらについても機能連携の対応を急いでおり、近く実装予定ですのでもう少々お待ち頂ければと思います。
9/4更新:8月のアップデートでOptuna on LaunchがOptunaの多目的最適化に対応いたしました。
