
深層学習4dayレポート

Section1:強化学習
【解説】
強化学習の歴史:
強化学習の歴史強化学習について・冬の時代があったが、計算速度の進展により大規模な状態をもつ場合の、強化学習を可能としつつある。・関数近似法と、Q学習を組み合わせる手法の登場Q学習・行動価値関数を、行動する毎に更新することにより学習を進める方法関数近似法・価値関数や方策関数を関数近似する手法のこと
強化学習とは目的を与えられ、制限された「環境」で「方策」と言う考えた行動を行いそれに対し「価値」得点が与えられるように工夫するという考え方。
強化学習のイメージ:
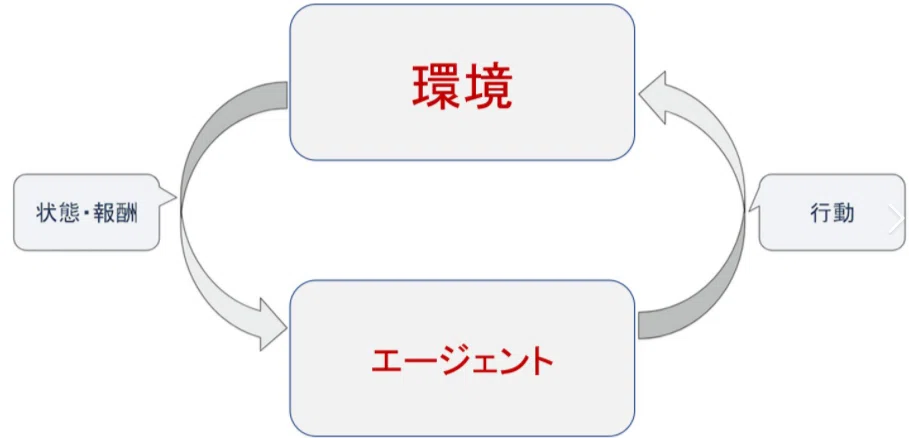
失敗を繰り返しながら、与えられる価値、報酬を高めるよう調整する行動を強化学習と言う。
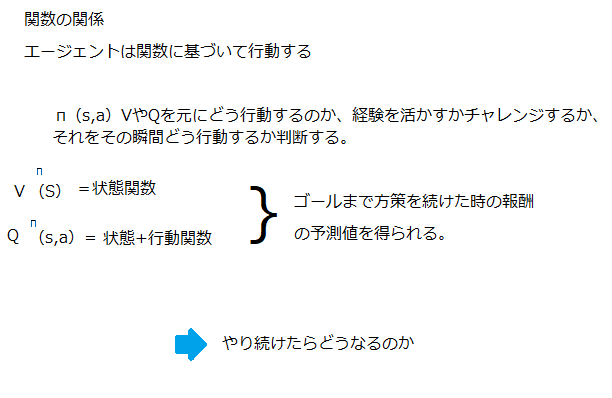
学習させる項目はこの二つ、方策関数。価値関数。

価値関数:
価値関数とは・価値を表す関数としては、状態価値関数と行動価値関数の2種類があるある状態の価値に注目する場合は、状態価値関数状態と価値を組み合わせた価値に注目する場合は、行動価値関数。
方策関数:
方策関数とは方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数のこと。
数式による表現:
方策とは、ある状態sでの行動aが一意に決まっている方策のことを言い下記の式で表すことが出来る。

方策関数、方策勾配法:

計算して展開すると:


【実装/演習】
以下のような非常に簡単な迷路を考える。

#必要なモジュールをインポート
import numpy as np
gamma = 0.9#将来価値の割引。小さいほど行動直後の利益を重視。また、この割引率の存在が効率的な学習の鍵となる。
alpha = 0.1#学習率。大きいと1回の学習による値の更新が急激となる。小さいほど更新がゆるやかとなる。後で詳述。 #報酬の設定 #各場所から移動できる箇所に報酬1を与え 、それ以外を0とすることで移動できる方向を指示 #以下の行列の各行が場所に対応 。0行目は迷路の位置0、1行目が迷路の位置1 #ゴールとなる8の報酬を大きく設定する
reward = np.array([[0,1,0,1,0,0,0,0,0],#0から1,3に移動できるので、そこに1
[1,0,1,0,1,0,0,0,0],#1から0,2,4に移動できるので、そこに1
[0,1,0,0,0,0,0,0,0],
[1,0,0,0,0,0,1,0,0],
[0,1,0,0,0,1,0,1,0],
[0,0,0,0,1,0,0,0,10000],#8をゴールより5→8の報酬を大きく
[0,0,0,1,0,0,0,1,0],
[0,0,0,0,1,0,1,0,0],
[0,0,0,0,0,1,0,0,0]]) #Q値 (行動価値)の初期値を設定。今回は0を初期値とする。
Q = np.array(np.zeros([9,9])) #Q学習を実装し 、各位置における行動価値を算出 #以下の学習を実行すると 、行動価値Qを求められる。Qの各行が位置に対応し、たとえば0行1列目の値は0から1に移動する行動の価値となる。 #p_stateのpはpresent (現在)、n_state,n_actionsのnはnext(次)のn
for i in range(10000):#1万回繰り返し学習を行う
p_state = np.random.randint(0,9)#現在の状態をランダムに選択
n_actions = []#次の行動の候補を入れる箱
for j in range(9):
if reward[p_state,j] >= 1:#rewardの各行が1以上のインデックスを取得
n_actions.append(j)#これでp_stateの状態で移動できる場所を取得
n_state = np.random.choice(n_actions)#行動可能選択肢からランダムに選択
#Q値の更新。学習率が小さいほど現在の行動価値が重視され、更新がゆるやかとなる
#ここでQ学習に用いる「たった一つの数式」を利用して行動価値を学習していく
Q[p_state,n_state] = (1-alpha)*Q[p_state,n_state]+alpha*(reward[p_state,n_state]+gamma*Q[n_state,np.argmax(Q[n_state,])]) #最短ルート表示関数の定義 。Q値が最も高い行動をappendで追加しているだけ
def shortest_path(start):#0~8の数字を入力。好きなところからスタート可能
path = [start]#pathに経路を追加していく
p_pos = start#p_posは現在位置(positionの略)
n_pos = p_pos#n_pos(次の位置)にいったんp_posを代入
while(n_pos != 8):#n_posがゴール(8)になるまで繰り返し行動を選択
n_pos = np.argmax(Q[p_pos,])#各位置の行動価値が最も高い行動を選択
path.append(n_pos)#経路をpathに追加
p_pos = n_pos#行動後が次のp_posとなる
return path
print(shortest_path(0))#スタートを0として最短経路を表示
最短経路となることには、割引率を設定していることが大きく関る。
0から1への移動したとき、5→8の大きな報酬を得るまでには少なくともあと3回行動する必要があり。
0から3への移動したとき、5→8の大きな報酬を得るまでには少なくともあと5回行動する必要があり。
つまり、0から3への移動の場合、5→8の大きな報酬に掛け算される割引率が2回多くなってしまう。
割引率が多く掛け算されるほど値は小さくなります。
たとえば、
10000×0.94=6561
10000×0.95=5904.9
したがって、ゴールの8に近い0~1への移動の方が行動価値が高くなり、かつ最短経路になっている。
【確認テスト/考察結果】
強化学習と通常の教師あり、教師なし学習との違いは何か?
結論:
目標が違う・教師なし、あり学習では、データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標。強化学習では、優れた方策を見つけることが目標
【関連/図書・問題・記事】

Qは行動の価値、tは時刻、stは時刻tの状態、atはそのときの行動。つまり、Q(st,at)は時刻tにおける状態sのときの、aという行動の価値となり、とにかく、Qが行動の価値だとわかればOK。
また、α(アルファ)は学習率、γ(ガンマ)は割引率となります。アルファは1回の学習の効率にかかわり、アルファが大きいほど行動価値を1回の学習で大きく変化させることになる。
ガンマは将来の報酬・利益を割り引くために用います(後で詳述)。わかりやすくいうと、今手元にある100円と、1年後に手に入る100円では1年後の100円の方が価値が低いということです。
同じ100円なら、今すぐ手に入る方がよいですよね。たとえば割引率ガンマ=0.9のとき、1年後の100円の価値は100×0.9=90円となります。2年後の100円なら100×0.9×0.9=81円です。ガンマを設定することで、遅く手に入る利益ほど価値を低くします。
最後に、rというのは獲得できる報酬・利益のことです。
行動価値を計算するための上記数式を算出するためには、まず状態の価値(状態価値)を求める数式を考えるとわかりやすいです。状態価値をV(st)とすると、報酬・利益のrとγ(ガンマ)を用いて以下のようにできます。さきほどと同様、遠い将来の報酬・利益ほど割引が大きくなるのがポイントです。
V(st)=rt+1+γrt+2+γ2rt+3+γ3rt+4+・・・
どういうことかというと、その時点での状態価値は、将来得られる利益を現在まで割引したものの総和に等しいということです。
右辺第2項を変形すると
V(st)=rt+1+γ(rt+2+γrt+3+γ2rt+4・・・)
すると、この式は以下のように書けることになります。
V(st)=rt+1+γV(st+1)
これをベルマン方程式と呼びます。状態価値に関してベルマン方程式が成り立つのと同様に、行動価値に関してもベルマン方程式が成り立ちます。
Q(st,at)=rt+1+γQ(st+1,at+1)
この行動価値のベルマン方程式の左辺を右辺に移動させると、
0=rt+1+γQ(st+1,at+1)−Q(st,at)(=TD誤差)
となるはず。
この右辺のことをTD誤差(Temporal difference error)と呼びます。理想的な状況ではTD誤差は0になるはずなのですが、学習が進んでない段階では0とならない。
なぜなら学習の初期段階ではQ(st,at)が初期値に依存したデタラメな値だからです。つまり、TD誤差がゼロとなること、言い換えるとベルマン方程式が成り立つよう行動価値Qを学習することが目的。
そして、αを学習率として以下のようにQ(st,at)を更新し、正しい値に近づけていきます。
Q(st,at)←Q(st,at)+αTD誤差
つまり、TD誤差が0より大きいときはTD誤差を0に近づけるためQ(st,at)を少し大きくし、TD誤差が0より小さいときはTD誤差を0に近づけるためQ(st,at)を少し小さくする、という試行錯誤を繰り返し行うことに等しいです。このように価値更新をする方法をSARSA法といいます。
Q学習は、価値更新の際にSARSA法のTD誤差を少し変えるだけです。
TD誤差=rt+1+γQ(st+1,at+1)−Q(st,at)
だったものを、
TD誤差=rt+1+γmaxat+1Q(st+1,at+1)−Q(st,at)
に変えます。そのため、Q学習は、常に最も価値の高い行動によって価値更新を行うことになります。
したがって、Q学習の数式は、以下のようになります。
Q(st,at)←Q(st,at)+α(rt+1+γmaxat+1Q(st+1,at+1)−Q(st,at))
右辺を式変形すれば、最終的に以前示した「1つだけ使う数式」が得られます。
Q(st,at)←(1−α)Q(st,at)+α(rt+1+γmaxat+1Q(st+1,at+1))
この式を見るとαの学習率という意味合いがわかります。αが0に近いほど、価値更新の際に現時点の行動価値が強く反映されます。そのため価値の更新がゆるやかに行われていくことになります。逆にαが1に近いほど、行動価値が大きく変わっていきます。だから学習率なのです。
以上がざっくりとしたQ学習の数学的背景となります。結局使うのは
Q(st,at)←(1−α)Q(st,at)+α(rt+1+γmaxat+1Q(st+1,at+1))
だけとなります。
[記事:超簡単な強化学習(Q学習)のPythonコード実装例で一気に理解!【迷路を解く】DSE総研オンライン編集部より]
Section2:AlphaGo
【解説】

AlphaGo(アルファ碁、アルファご)は、Google DeepMindによって開発された19路盤で動くコンピュータ囲碁プログラム
AlphaGo (Lee) と AlphaGo Zeroがある。
AlphaGo (Lee):
●PolicyNet(方策関数)

19x19の盤面特徴(48チャンネル)を入力。
通常のカラー画像ではRGBの3チャンネルだったが、48チャンネル持っている(石が自石・敵石・空白か、着手履歴、取れる石の数はいくつか等)。
出力はソフトマックス関数によって19x19の着手予想確率(どこに打つと良いか)が得られる。
●ValueNet(価値関数):
19x19の盤面特徴(49チャンネル)を入力とする。手番というチャンネルが増えているだけでほかはPolicyNetと同じ
出力はtanh関数によって現局面の勝率を-1~1の範囲で得られる。
PolicyNetと違い、出力は2次元ではなく1次元(単一値)であるため平滑化(Flatten)をする。
●AlphaGoの学習:
1、教師あり学習によるRollOutPolicyとPolicyNetの学習
PolicyNetの教師あり学習KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。具体的には、教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。この学習で作成したPolicyNetは57%ほどの精度である。
2、強化学習によるPolicyNetの学習
現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行った。PolicyPoolとは、PolicyNetの強化学習の過程を500Iteraionごとに記録し保存しておいたものである。現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうというのが主である。この学習をminibatch size 128で1万回行った。
3、強化学習によるValueNetの学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。教師データ作成の手順は1、まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。2、N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。3、S(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。S(N+1)とRを教師データ対とし、損失関数を平均二乗誤差とし、回帰問題として学習した。この学習をminibatch size 32で5000万回行ったN手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている
●RollOutPolicy:

ニューラルネットワークの大量な計算を軽減するための手法。
線形の方策関数。
探索中に高速に着手確率を出す。PolicyNetのような方策関数は畳み込みをしているため計算量が多かったがRollOutPolicyは1000倍速い。
●強化学習の学習手法
コンピュータ囲碁ソフトでは現在もっとも有効とされている探索法。他のボードゲームではminmax探索やその派生形のαβ探索を使うことが多いが、盤面の価値や勝率予想値が必要となる。しかし囲碁では盤面の価値や勝率予想値を出すのが困難であるとされてきた。そこで、盤面評価値に頼らず末端評価値、つまり勝敗のみを使って探索を行うことができないか、という発想で生まれた探索法である。囲碁の場合、他のボードゲームと違い最大手数はマスの数でほぼ限定されるため、末端局面に到達しやすい。具体的には、現局面から末端局面までPlayOutと呼ばれるランダムシミュレーションを多数回行い、その勝敗を集計して着手の優劣を決定する。また、該当手のシミュレーション回数が一定数を超えたら、その手を着手したあとの局面をシミュレーション開始局面とするよう、探索木を成長させる。この探索木の成長を行うというのがモンテカルロ木探索の優れているところである。モンテカルロ木探索はこの木の成長を行うことによって、一定条件下において探索結果は最善手を返すということが理論的に証明されている。


AlphaGo Zero:
特徴:
1、教師あり学習を一切行わず、強化学習のみで作成
2、特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3、PolicyNetとValueNetを1つのネットワークに統合した
4、Residual Net(後述)を導入した
5、モンテカルロ木探索からRollOutシミュレーションをなくした
AlphaGo ZeroのPolicyValueNet:

●重要なのが中央のResidualNetwork
ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったものResidula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった基本構造はConvolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLUのBlockを1単位にして積み重ねる形となるまた、Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある。
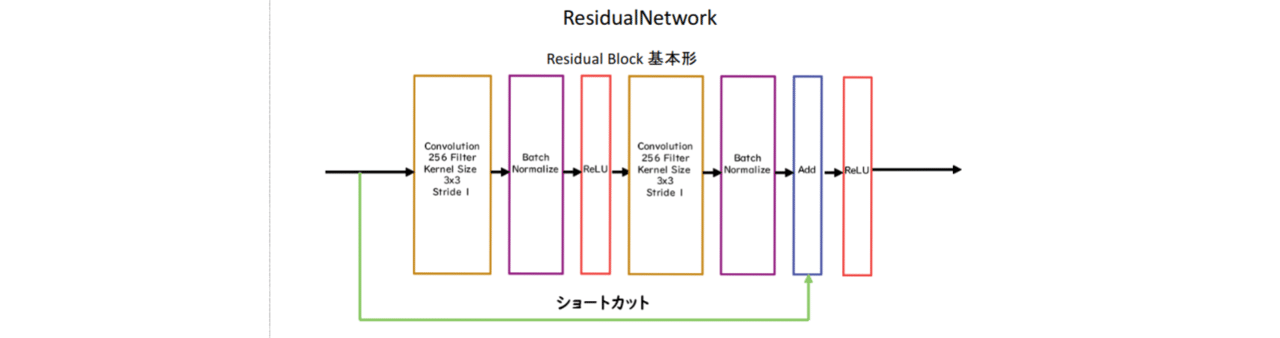
●ResidualNetworkの派生形

●ResidualNetworkの性能
左記はResidualNetworkをImageNetの画像分類に使ったときのネットワーク構造、およびエラーレートである。18、34Layerのものは基本形、50、101、152LayerのものはBottleNeck構造である。性能は従来のVGG-16と比較してTop5で4%程度ものエラー率の低減に成功している。

●Alpha Go Zeroの学習法
Alpha Goの学習は自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される自己対局による教師データの作成現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。自己対局中の各局面での着手選択確率分布と勝敗を記録する。教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。学習自己対局で作成した教師データを使い学習を行う。NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差。ネットワークの更新学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
【確認テスト/考察結果】
●確認テストがないので、ディープラーニングE資格より抜粋



終了時点のタイムステップをLとし書く時間ステップをt<Lで行動を選ぶ時、多く訪問した手は採用率を低く広い探索を促進する。
(ア)=D
行動価値観数の更新は
(イ)=A で行う。
アルファ碁は与えられた時間内で種ミュレーションを繰り返し探索が終了したらルートノードから最も訪問回数が多い行動を次のさしてとして採用するので
(ウ)=C
【関連/図書・問題・記事】
AlphaGo(アルファ碁、アルファご)は、Google DeepMindによって開発されたコンピュータ囲碁プログラムである。
2015年10月に、人間のプロ囲碁棋士を互先(ハンディキャップなし)で破った初のコンピュータ囲碁プログラムとなった。2016年3月15日には、李世乭との五番勝負で3勝(最終的に4勝1敗)を挙げ、韓国棋院に(プロとしての)名誉九段を授与された。また、2017年5月には、柯潔との三番勝負で3局全勝を挙げ、中国囲棋協会にプロの名誉九段を授与された。Google DeepMindは世界トップ棋士である柯潔に勝利したことを機に、AlphaGoを人間との対局から引退させると発表した。
コンピュータが人間に打ち勝つことが最も難しいと考えられてきた分野である囲碁において、人工知能が勝利を収めたことは世界に衝撃をもたらした。AlphaGoの登場は単なる一競技の勝敗を越え、人工知能の有用性を広く知らしめるものとなり、世界的AIブームを呼び起こすきっかけともなった。
AlphaGoはAlphaGo Lee、AlphaGo Zeroの他に、AlphaGo Fan、AlphaGo Master、AlphaZeroがある。
[wikipediaより]
Section3:軽量化・高速化技術
【解説】
機械学習の必要な計算処理が1年で10倍、PCの処理速度はそれに全く追いついていない状況。で、あればたくさんの計算処理できるものを集めて処理させて問題を解決しようとする手段。計算処理できる物体一個一個をワーカーと呼ぶ。
データ並列化
親モデルを各ワーカーに子モデルとしてコピー
データを分割し、各ワーカーごとに計算させる

●データ並列化:同期型
各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する。

●データ並列化:非同期型
各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。学習が終わった子モデルはパラメータサーバにPushされる。新たに学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく。

・処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
・非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
・現在は同期型の方が精度が良いことが多いので、主流となっている
モデル並列化
・親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
・モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。

GPUによる高速化
GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
CPU
高性能なコアが少数
複雑で連続的な処理が得意
GPU
比較的低性能なコアが多数
簡単な並列処理が得意
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
軽量化
1.量子化(Quantization)
通常のパラメータの64 bit 浮動小数点を32 bit など下位の精度に落とすことでメモリと演算処理の削減を行う
利点としては、計算の高速化省メモリが上げられるが、化欠点は有働小数点の表現が64bitに比べて32bitは少ないので精度の低下が上げられる。
2.蒸留
規模の大きなモデルの知識を使い軽量なモデルの作成を行う


3.プルーニング
モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化を行う技術
●削減のイメージ

●削減の例
ニューロンの削減の手法は重みが閾値以下の場合ニューロンを削減し、再学習を行う下記の例は重みが0.1 以下のニューロンを削減をする。

注目する点としては削減の部分が約50%でも90%以上の精度が出ているということも注目。
【確認テスト/考察結果】
制度と速度の実験:

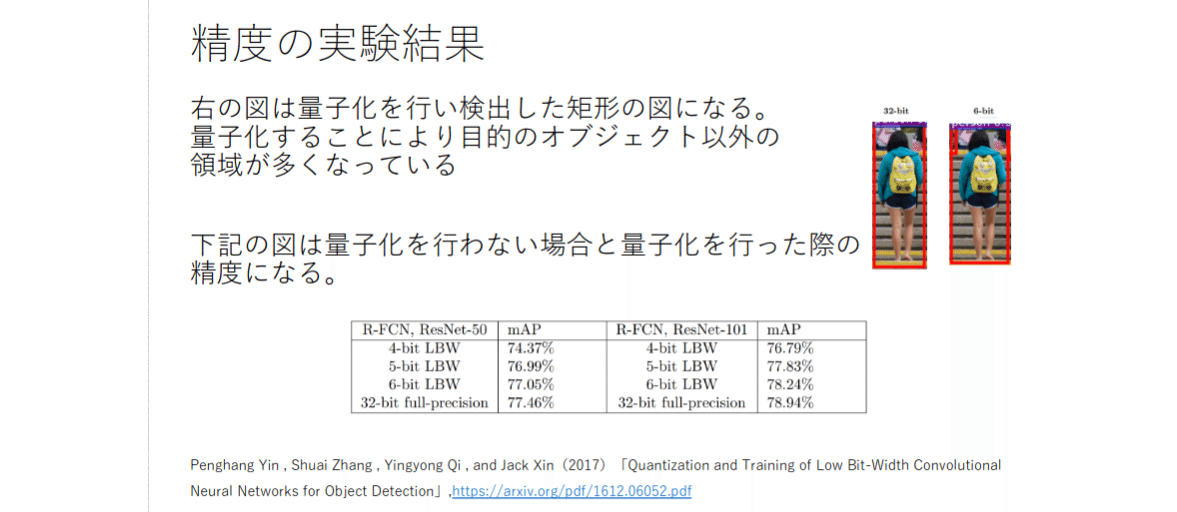
●速度の実験より、処理の量が少ないと、計算量もそれに比例するようにして時間も少なくなっている32bit約32秒、6bit約6秒となっている。
●精度がそれで悪くなるかと思うがほどんど変わらないことが分かる。
【関連/図書・問題・記事】
蒸留に関する問題:


ア=A:分類問題における通常学習の目的は、正解クラスに対する確率の対数の平均を最大にすること。
イ=B:ニューラルネットワークに構築されたモデルは正解クラスに対する確率だけではなく不正解のクラスの確率も出力する。
ウ=A:あるGPUワーカが購買を計算している間にパラメータ更新が行われることが有るため計算される勾配が古いパラメータに対して計算されることがある。これらの勾配を陳腐化された勾配とよび学習が不安定にな原因になる対策としては学習率を大きくする。
エ=B:逆伝搬ではGPU間での通信が必要だが、順伝搬ではGPU間での通信は不要である。
Section4:応用モデル
【解説】
MobileNet:
Depthwise Separable Convolution (Depthwise ConvolutionとPointwise Convolution)という仕組みを用いて画像認識において軽量化・高速化したモデル。
●Depthwise Convolution

●Pointwise Convolution

通常の畳込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行い組み合わせて行うう。
DenseNet:
Dense Convolutional Network(以下、DenseNet)は、畳込みニューラルネットワーク(以下、CNN)アーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、Residual Network(以下、ResNet)などのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseBlockと呼ばれるモジュールを用いた、DenseNetもそのようなアーキテクチャの一つである。
●DenseNetとResNetの違い
○DenseBlockでは前方の各層からの出力全てが後方の層への入力として用いられる
○RessidualBlockでは前1層の入力のみ後方の層へ入力
●DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは成⻑率(Growth Rate)と呼ばれるハイパーパラメータが存在する。
○DenseBlock内の各ブロック毎にk個ずつ特徴マップのチャネル数が増加していく時、kを成⻑率と呼ぶ
正規化:
●Batch Norm
ミニバッチに含まれるsampleの同一チャネルが同一分布に従うよう正規化
●Layer Norm
それぞれのsampleの全てのpixelsが同一分布に従うよう正規化
●Instance Nrom
さらにchannelも同一分布に従うよう正規化
Wavenet:
生の音声波形を生成する深層学習モデル
Pixel CNNを音声に応用したもの
時系列データである音声に畳込みニューラルネットワーク(Dilated Convolution)を適用する

【確認テスト/考察結果】
復習を兼ねて、MobileNetのアーキテクチャまとめ確認

い=H☓W☓C☓K☓K
う=H☓W☓C☓M

【関連/図書・問題・記事】
MobileNet。通常はすべてを正しく抽出し。複雑であるもののすべてを解析すれば、時間がかかるが精度の高いものが作れると思う。
しかし、そうではない構造、考え方の事が気になったので簡単な概要や作られた背景等調べてみた。
●MobileNetがつくられた背景
・従来はより深く、より複雑化することで精度をあげようとすることがモデル開発の主流だった。それに対してMobileNetは、オンデバイスや組み込みアプリケーションの限られたリソースを意識しながら、効率的に精度を最大化することに重点をおいて設計された。
・MobileNetのアーキテクチャの特徴は、depthwise separable convolutions(depthwise convolutionsと pointwise convolutionsの組み合わせ)に基づいてる点にある。
・ハイパーパラメータとしてwidth multiplier と resolution multiplier を用いることで、モデルサイズとレイテンシー、精度のトレードオフを最適化するより小さく高速なモバイルネットを構築する方法を示している。
●計算量が減る仕組み
標準的な畳み込み層は、DF × DF × M の特徴量マップ F を入力とし、DF × DF × N の特徴量マップ Gを作り出す。(なお、ここで、DF は正方形の入力特徴量マップの空間幅と高さ※1 、DK は正方形と仮定したカーネルの空間次元、 M は入力チャンネル数(入力の深さ)、DG は正方形の出力特徴量マップの空間幅と高さ、N は出力チャンネル数(出力の深さ)を意味する。※1.出力特徴量マップは入力と同じ空間寸法を持ち、両特徴量マップは正方形であると仮定する。モデル縮小の結果は、任意のサイズとアスペクト比の特徴量マップに一般化する。)
標準的な畳み込み層は、サイズ DK ×DK ×M×N の畳み込みカーネル K でパラメータ化されている。ストライド1とパディングを仮定した標準畳み込みの出力特徴量マップは、次のように計算される。

ここで、計算コストは、入力チャネル数 M、出力チャネル数 N、カーネルサイズ DK × DK、特徴マップサイズ DF × DF の大きさに乗算的に依存していることがわかる。MobileNet モデルは、これらの各項とその乗算的関係に対応することで計算コストを削減する。具体的には、depthwise convolutions convolutionsを用いることで、出力チャネル数とカーネルサイズが乗算されることを解消する。
depthwise separable convolutionsは、depthwise convolutionsとpointwise convolutionsの2つの層で構成されている。depthwise convolutionsを利用して、各入力チャネル(入力の深さ)ごとに単一のフィルタを適用する。次に、単純な1×1の畳み込みであるpointwise convolutionsを使用して、depthwise convolutions層の出力の線形組み合わせを作成する。(なお、MobileNetsでは、両方のレイヤにバッチノルムとReLU非線形性の両方を使用している。)
入力チャネル(入力の深さ)ごとに1つのフィルタを使用したdepthwise convolutionsは、次のように書くことができる。

depth方向のみの畳み込みは、標準的な畳み込みに比べて非常に効率的である。しかし、これは入力チャンネルをフィルタリングするだけで、それらを組み合わせて新しい特徴を生成することはない。そのため、これらの新しい特徴を生成するためには、pointwise convolutionsを介してdepthwith convolutionsの出力の線形結合を計算することが必要となる。
depthwise separable convolutionsのコストは depthwise convolutionsと 1×1pointwise convolutionsを合計した以下になる。

MobileNet は 3×3のdepthwise separable convolutionsを使用しており、標準的な畳み込みよりも 8 ~ 9 倍の計算量を削減しながら、精度をわずかに低下させるだけとなっている。(なお、空間次元での追加の分解は、depth方向の畳み込みに費やされる計算量が非常に少ないため、追加の計算量をあまり節約できない。)
Section5:Transformer
【解説】
BERTの理解するための知識の一つTransformer
目標:
三段階に分けてBERTを理解する。
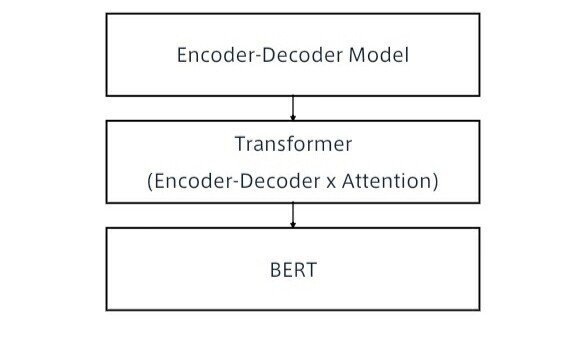
5-1;Encoder-Decoder
:seq2seqの理解
系列(Sequence)を入力として、系列を出力するもの
-Encoder-Decoderモデルとも呼ばれる
- 入力系列がEncode(内部状態に変換)され、内部状態からDecode(系列に変換)する
- 実応用上も、入力・出力共に系列情報なものは多い
- 翻訳 (英語→日本語)
- 音声認識 (波形→テキスト)
- チャットボット (テキスト→テキスト)
:seq2seqの材料
○RNN
RNNとは


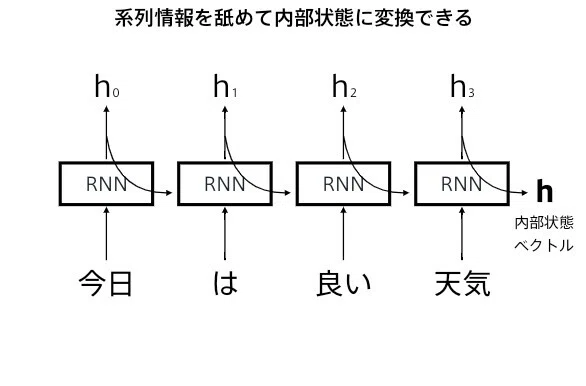
○言語モデル
言語モデルとは


○RNN x 言語モデル
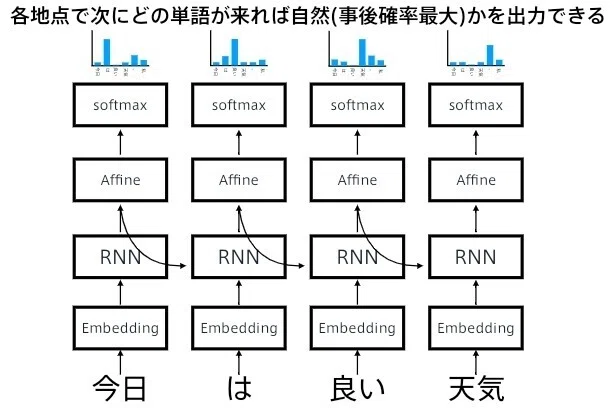
RNNは系列情報を内部状態に変換することができる
- 文章の各単語が現れる際の同時確率は、事後確率で分解できる -
事後確率を求めることがRNNの目標になる -
言語モデルを再現するようにRNNの重みが学習されていれば、ある時点の次の単語を予測することができる -
先頭単語を与えれば文章を生成することも可能
:上記を踏まえた上でseq2seq解説
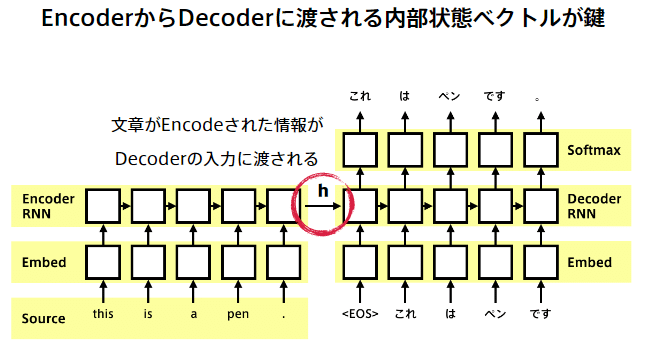


5-2;Transformer
RNN問題として長さに弱い。

それをフォローするためにアテンションが有る。
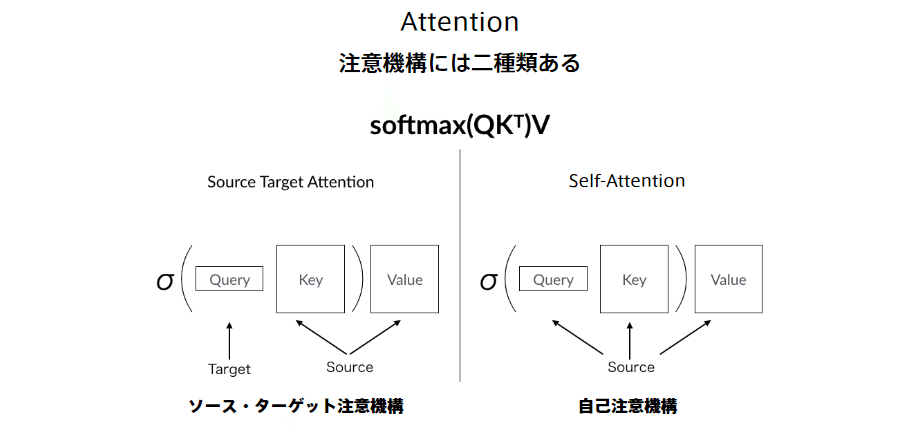
Attention (注意機構):


そうする事で、文長が長くなっても翻訳精度が落ちないことが確認できる。

Encoder-Decoder特徴説明:
特徴【1】
-2017年6月に登場 - RNNを使わない - 必要なのはAttentionだけ 当時のSOTAをはるか少ない計算量で実現 - 英仏 (3600万文) の学習を8GPUで3.5日で完了。
特徴【2】

特徴【3】
特徴【4】
自己注意機構により文脈を考慮して各単語をエンコード

特徴【5】
Self-Attention、入力を全て同じにして学習的に注意箇所を決めていく
特徴【6】
Position-Wise Feed-Forward Networks、位置情報を保持したまま順伝播させることが出来る。

特徴【7】
Scaled dot product attention
全単語に関するAttentionをまとめて計算する

特徴【8】
Multi-Head attentionm重みパラメタの異なる8個のヘッドを使用

特徴【9】
Decoder

特徴【10】
Add & Norm

特徴【11】
Position Encoding

特徴【12】
Position Encoding縦軸が単語の位置、横軸が成分の次元

まとめ

【実装/演習】
from os import path
!pip3 install wheel==0.34.1
from wheel.pep425tags import get_abbr_impl, get_impl_ver, get_abi_tag
platform = '{}{}-{}'.format(get_abbr_impl(), get_impl_ver(), get_abi_tag())
accelerator = 'cu80' if path.exists('/opt/bin/nvidia-smi') else 'cpu'
!pip install -q http://download.pytorch.org/whl/{accelerator}/torch-0.4.0-{platform}-linux_x86_64.whl torchvision
import torch
print(torch.__version__)
print(torch.cuda.is_available())
! wget https://www.dropbox.com/s/9narw5x4uizmehh/utils.py
! mkdir images data
# data取得
! wget https://www.dropbox.com/s/o4kyc52a8we25wy/dev.en -P data/
! wget https://www.dropbox.com/s/kdgskm5hzg6znuc/dev.ja -P data/
! wget https://www.dropbox.com/s/gyyx4gohv9v65uh/test.en -P data/
! wget https://www.dropbox.com/s/hotxwbgoe2n013k/test.ja -P data/
! wget https://www.dropbox.com/s/5lsftkmb20ay9e1/train.en -P data/
! wget https://www.dropbox.com/s/ak53qirssci6f1j/train.ja -P data/
! ls data
import random
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from nltk import bleu_score
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
from utils import Vocab
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(1)
random_state = 42
print(torch.__version__)中身の確認
! head -10 data/train.en
! head -10 ./data/train.ja
def load_data(file_path):
# テキストファイルからデータを読み込むメソッド
data = []
for line in open(file_path, encoding='utf-8'):
words = line.strip().split() # スペースで単語を分割
data.append(words)
return data
train_X = load_data('./data/train.en')
train_Y = load_data('./data/train.ja')
# 訓練データと検証データに分割
train_X, valid_X, train_Y, valid_Y = train_test_split(train_X, train_Y, test_size=0.2, random_state=random_state)
print('train data', train_X[0])
print('valid data', valid_X[0])
# まず特殊トークンを定義しておく
PAD_TOKEN = '<PAD>' # バッチ処理の際に、短い系列の末尾を埋めるために使う (Padding)
BOS_TOKEN = '<S>' # 系列の始まりを表す (Beggining of sentence)
EOS_TOKEN = '</S>' # 系列の終わりを表す (End of sentence)
UNK_TOKEN = '<UNK>' # 語彙に存在しない単語を表す (Unknown)
PAD = 0
BOS = 1
EOS = 2
UNK = 3
MIN_COUNT = 2 # 語彙に含める単語の最低出現回数 再提出現回数に満たない単語はUNKに置き換えられる
# 単語をIDに変換する辞書の初期値を設定
word2id = {
PAD_TOKEN: PAD,
BOS_TOKEN: BOS,
EOS_TOKEN: EOS,
UNK_TOKEN: UNK,
}
# 単語辞書を作成
vocab_X = Vocab(word2id=word2id)
vocab_Y = Vocab(word2id=word2id)
vocab_X.build_vocab(train_X, min_count=MIN_COUNT)
vocab_Y.build_vocab(train_Y, min_count=MIN_COUNT)
vocab_size_X = len(vocab_X.id2word)
vocab_size_Y = len(vocab_Y.id2word)
print('入力言語の語彙数:', vocab_size_X)
print('出力言語の語彙数:', vocab_size_Y)

コードが長いので訓練から表示。
# 訓練
best_valid_bleu = 0.
for epoch in range(1, num_epochs+1):
train_loss = 0.
train_refs = []
train_hyps = []
valid_loss = 0.
valid_refs = []
valid_hyps = []
# train
for batch in train_dataloader:
batch_X, batch_Y, lengths_X = batch
loss, gold, pred = compute_loss(
batch_X, batch_Y, lengths_X, model, optimizer,
is_train=True
)
train_loss += loss
train_refs += gold
train_hyps += pred
# valid
for batch in valid_dataloader:
batch_X, batch_Y, lengths_X = batch
loss, gold, pred = compute_loss(
batch_X, batch_Y, lengths_X, model,
is_train=False
)
valid_loss += loss
valid_refs += gold
valid_hyps += pred
# 損失をサンプル数で割って正規化
train_loss = np.sum(train_loss) / len(train_dataloader.data)
valid_loss = np.sum(valid_loss) / len(valid_dataloader.data)
# BLEUを計算
train_bleu = calc_bleu(train_refs, train_hyps)
valid_bleu = calc_bleu(valid_refs, valid_hyps)
# validationデータでBLEUが改善した場合にはモデルを保存
if valid_bleu > best_valid_bleu:
ckpt = model.state_dict()
torch.save(ckpt, ckpt_path)
best_valid_bleu = valid_bleu
print('Epoch {}: train_loss: {:5.2f} train_bleu: {:2.2f} valid_loss: {:5.2f} valid_bleu: {:2.2f}'.format(
epoch, train_loss, train_bleu, valid_loss, valid_bleu))
print('-'*80)
評価:
# 生成
batch_X, batch_Y, lengths_X = next(test_dataloader)
sentence_X = ' '.join(ids_to_sentence(vocab_X, batch_X.data.cpu().numpy()[:-1, 0]))
sentence_Y = ' '.join(ids_to_sentence(vocab_Y, batch_Y.data.cpu().numpy()[:-1, 0]))
print('src: {}'.format(sentence_X))
print('tgt: {}'.format(sentence_Y))
output = model(batch_X, lengths_X, max_length=20)
output = output.max(dim=-1)[1].view(-1).data.cpu().tolist()
output_sentence = ' '.join(ids_to_sentence(vocab_Y, trim_eos(output)))
output_sentence_without_trim = ' '.join(ids_to_sentence(vocab_Y, output))
print('out: {}'.format(output_sentence))
print('without trim: {}'.format(output_sentence_without_trim))
# BLEUの計算
test_dataloader = DataLoader(test_X, test_Y, batch_size=1, shuffle=False)
refs_list = []
hyp_list = []
for batch in test_dataloader:
batch_X, batch_Y, lengths_X = batch
pred_Y = model(batch_X, lengths_X, max_length=20)
pred = pred_Y.max(dim=-1)[1].view(-1).data.cpu().tolist()
refs = batch_Y.view(-1).data.cpu().tolist()
refs_list.append(refs)
hyp_list.append(pred)
bleu = calc_bleu(refs_list, hyp_list)
print(bleu)
と言う結果になった。
【確認テスト/考察結果】

RNNでは、時刻 t の出力を時刻 t+1 の入力とすることができるが、この方法でDecoderを学習させると連鎖的に誤差が大きくなっていき、学習が不安定になったり収束が遅くなったりする問題が発生します。
この問題への対策としてTeacher Forcingというテクニックがあり。 これは、訓練時にはDecoder側の入力に、ターゲット系列(参照訳)をそのまま使うというものです。 これにより学習が安定し、収束が早くなるというメリットがある。

この手法は学習が安定し、収束が早くなるというメリットがありるが、逆に評価時は前の時刻にDecoderが生成したものが使われるため、学習時と分布が異なってしまうというデメリットがある。
Teacher Forcingの拡張として、ターゲット系列を入力とするか生成された結果を入力とするかを確率的にサンプリングするScheduled Samplingという手法がある。
【関連/図書・問題・記事】
BERTの誕生した背景と特徴の大きなまとめ:
2017年12月にEncoder-Decoder翻訳モデルを並列処理が可能であるAttentionのみで構成したTransformerが発表されました。その後研究が進むにつれてTransformerに使われている Self Attention による文章の意味抽出能力が相当強力であることが分かりました。

そこで、TransformerのEncoder部分のみを使ったOpenAI GPTが発表されSelf Attentionで性能が向上することが分かりましたが、前の文脈しか利用できませんでした。一方、双方向LSTMを採用した翻訳モデルELMoは、前後の文脈の活用で性能が向上することが分かりましたが、並列処理が行えませんでした。
そして2018年10月にBERTが発表されました。BERTは、Self Attentionで並列処理を行い、かつ事前学習の工夫によって前後の文脈を活用することを可能にしました。そして、事前学習+ファインチューニングの2段階学習によって様々なタスクへの対応を可能にし、現在主流のモデルになりました。
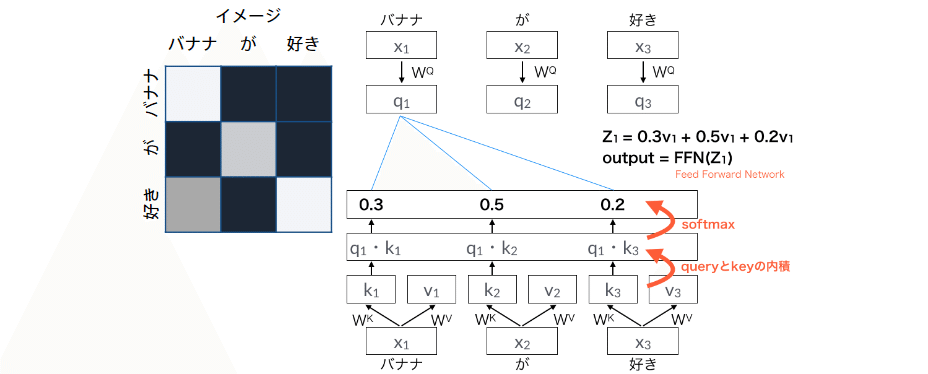
まず、Self Attentionについて簡単に説明します。入力(単語数, 次元数)に3つの全結合層を通してQuery, Key, Valueを作ります。つまり、入力に3つの重み(Wq, Wk, Wv)を掛けたものが、それぞれ Query, Key, Value となります。この3つの重みが学習の中で最適化されて行くわけです。

QueryとKey(転置)の内積によって、Queryの各ベクトルがKeyのどのベクトルと関連度が高いかを表す重み(Weight)を求めます。その後、ルートdkで割っているのは、Softmaxをかけた時に大き過ぎる値があるとそれ以外の数字が0になってしまうので、それを防止するためのものです。
そして、その重みとValueの内積によって、Valueの各ベクトルの重み付け和(Context vector)を求めます。結果、Contextvector は、QueryとKeyの掛かり受け構造がどうなっているのかを表すことになり、これが文の意味抽出において絶大な力を発揮します。
[記事:人工知能AIより]
Section6:物体検知・セグメンテーション
【解説】
広義の物体認識タスク
入力:画像(カラー・モノクロは問わない)
出力:
分類・・・(画像に対し単一または複数の)クラスラベル
物体検知・・・Bounding Box
意味領域分割・・・(各ピクセルに対し単一の)クラスラベル
個体領域分割・・・(各ピクセルに対し単一の)クラスラベル

物体検出コンペティションで用いられたデータセット
VOC12, ILSVRC17, MS COCO18, OICOD18
開発されたアルゴリズムの精度を見るために、共通として制度評価に用いられるデータセットが必要になる。


正解率(Accuracy):全データ(TP+FN+FP+TNTP+FN+FP+TN)のうち、正しく判別した(TP+TNTP+TN)確率
TP+TNTP+FN+FP+TN
TP+TNTP+FN+FP+TN

再現率(Recall):Positiveなデータ(TP+FNTP+FN)から、Positiveと予想(TPTP)できる確率
TPTP+FN
TPTP+FN
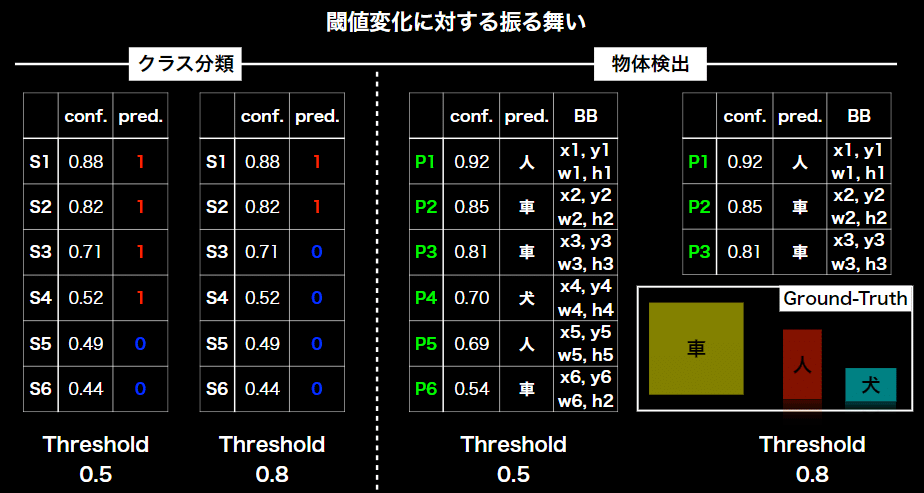
適合率(Precision):モデルがPositiveと予想したデータTP+FPTP+FPから、Positiveと予想(TPTP)できる確率
TPTP+FP
TPTP+FP
F値(F score):再現率(Recall)と適合率(Precision)の調和平均
21Recall+1Precision=2(Precision)(Recall)Recall+Precision
21Recall+1Precision=2(Precision)(Recall)Recall+Precision
IOU(Intersection Over Union)= Area of overlap / Area of Union
クラスラベルだけでなく, 物体位置の予測精度も評価


AP:Average Precision(PR曲線の下側面積)
confの閾値をββとするとき、Recall==R(ββ)、
Precision== P(ββ)
AP=∫10P(R)dR
AP=∫01P(R)dR


mAP:mean Average Precision
APの平均
mAP=1C∑i=1CAPi
mAP=1C∑i=1CAPi


FPS:Flames per Second
検出精度に加え検出速度も問題となる

2段階検出器(Two-stage detector)
候補領域の検出とクラス推定を別々に行う。
相対的に精度が高い傾向
相対的に計算量が大きく推論も遅い傾向
→リアルタイム検出には向かない
1段階検出器(One-stage detector)
候補領域の検出とクラス推定を同時に行う。
相対的に精度が低い傾向
相対的に計算量が小さく推論も早い傾向

SSD (Single Shot Detector)
1段階検出器のモデルの1つ。
初めにデフォルトボックスを用意する。

デフォルトボックスを変形して、プレディクテッド・バウンディングボックスとする。
【関連/図書・問題・記事】
SSDの進化:
●SSD: Single Shot MultiBox Detector
シングルショットマルチボックス検出器
単一のディープニューラルネットワークを用いて画像内の物体を検出する方法。アプローチでは、バウンディング ボックスの出力スペースを、フィーチャ マップの位置ごとに異なる縦横比と縮尺を超える既定のボックスのセットに分離。
予測時には、ネットワークは各デフォルトボックスに各オブジェクトカテゴリの存在に対してスコアを生成し、オブジェクトの形状に合わせてボックスに対する調整。さらに、ネットワークは、さまざまなサイズのオブジェクトを自然に処理するために、異なる解像度を持つ複数のフィーチャ マップからの予測を組み合わせる。
SSD モデルは、提案の生成とその後のピクセルまたはフィーチャのリサンプリング段階を完全に排除し、すべての計算を単一のネットワークにカプセル化するため、オブジェクト提案を必要とするメソッドに対して単純。これにより、SSD は、検出コンポーネントを必要とするシステムに簡単に統合できるトレーニングが容易になります。
PASCAL VOC、MS COCO、およびILSVRCデータセットの実験結果は、SSDが追加のオブジェクト提案ステップを利用するメソッドと同等の精度を有し、はるかに高速であり、トレーニングと推論の両方に統一されたフレームワークを提供することを確認した。他の単一ステージ方式と比較して、SSDは入力画像サイズが小さくても、はるかに精度が高い。対して300×300入力、SSD は、NVIDIA タイタン X の 58 FPS で VOC2007 テストで 72.1% mAP を達成し、500×500入力、SSDは75.1%mAPを達成し、より速いR-CNNモデルの同等の状態を上回る。
●DSSD: Deconvolutional Single Shot Detector
デコンボルシャナルシングルショット検出器
最先端の分類器(残差-101[14])と高速検出フレームワーク(SSD[18])を組み合わせる。
次に、SSD+残差-101をデコンボリューション層で増強し、オブジェクト検出に大規模なコンテキストを追加し、特に小さな物体の精度を向上させ、デコンボリューションシングルショット検出器用に得られたシステムDSSDを呼び出します。
これら 2 つの貢献は簡単に高レベルで記述されますが、簡単な実装は成功しません。その代わりに、学習した変換のステージ、特にデコンボリューションのフィードフォワード接続用のモジュールと新しい出力モジュールを慎重に追加することで、この新しいアプローチが可能になり、さらなる検出研究のための潜在的な方法が形成されることを示しています。
結果は、PASCAL VOC と COCO 検出の両方で示されます。私たちのDSSDと513×513入力は、VOC2007テストで81.5%mAP、VOC2012テストで80.0mAP、COCOで33.2%mAPを達成し、各データセットの最先端の方法R-FCN[3]を上回ります。
●Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
畳み込みニューラルネットワークを介してシングルショットマルチボックス検出器の浅い部分を拡張
シングルショットマルチボックスディテクタ(SSD)は、現在のオブジェクト検出フィールドで最速のアルゴリズムの1つで、完全に畳み込みニューラルネットワークを使用して画像内のすべてのスケーリングされたオブジェクトを検出します。
デコンボリューションシングルショットディテクタ(DSSD)は、SSDにデコンボリューションモジュールを追加することで、より多くのコンテキスト情報を導入するアプローチです。
また、PASCAL VOC2007の平均平均精度(mAP)がSSDの77.5%から78.6%に改善されました。DSSD は SSD より 1.1% 高い mAP を取得しますが、1 秒あたりのフレーム数 (FPS) は 46 から 11.8 に減少します。
そのバランスの解決のため、ESSDという単一段階のエンドツーエンド画像検出モデルを提案する。
この問題に対する解決策は、最良の単一段階(例えばSSD)検出器の浅い層のより良い文脈情報を巧みに拡張すること。実験結果モデルは79.4%mAPに達し、DSSDとSSDをそれぞれ0.8ポイントと1.9ポイント上回っている。
一方この手法だと、テスト速度はタイタンX GPUで25 FPSで、元のDSSDの2倍以上。
●Single-Shot Refinement Neural Network for Object Detection
オブジェクト検出のためのシングルショットリファインメントニューラルネットワーク
物体検出では、2段階のアプローチ(例えば、より速いR-CNN)が最高の精度を達成しているのに対し、一段階アプローチ(例えば、SSD)は高効率の利点を有する。
両論のメリットを継承し、その欠点を克服するために、2段法よりも精度が高く、一段法の同等の効率を維持する、RefineDetという新しいシングルショットベースの検出器がある。
RefineDetは、2つの接続されたモジュール、すなわち、アンカー絞り込みモジュールとオブジェクト検出モジュールで構成されています。具体的には、前者は(1)分類器の検索スペースを減らすために負のアンカーを除外し、アンカーの位置とサイズを粗く調整して後続のリグレッサーの初期化を改善することを目的。
後者のモジュールは、改良されたアンカーを前者からの入力として受け取り、回帰をさらに改善し、多クラスのラベルを予測します。一方、アンカー絞り込みモジュールのフィーチャを転送して、オブジェクト検出モジュール内のオブジェクトの位置、サイズ、クラス ラベルを予測する転送接続ブロックを設計。
マルチタスクの損失機能により、ネットワーク全体をエンドツーエンドでトレーニングできます。PASCAL VOC 2007、PASCAL VOC 2012、およびMS COCOに関する広範な実験は、RefineDetが高効率で最先端の検出精度を達成することを実証済み。
[テキスト100ページ目、SSDの進化を追いたい方へより]
この記事が気に入ったらサポートをしてみませんか?