汎用ヒューリスティック(CB)

集合分析を使った学習の問題
Piosolverを使った集合分析はその仕様上プリフロップレンジとスタックサイズが固定されており、それを使って構築されたヒューリスティックもプリフロレンジとスタックが固定さていることが前提になりやすい問題があります
(具体例としてSBvsBTNとBBvsBTNではプリフロレンジが異なるので、どちらか一方の集合分析に基づいて構築されたヒューリスティックをもう一方にそのまま使うことは危険です)
この問題を解決する方法としてレンジやスタックを変更した複数の集合分析を行うことが考えられますが、複数の集合分析をそれぞれ個別に使った座学をするのは非常に手間がかかります
この記事の目的は機械学習を使って複数の集合分析をまとめて分析し、上記の問題を克服したヒューリスティックの構築をすることです
分析方法の概要
IP2bet→OOPcall、OOP2bet→IPcc、OOP3bet→IPcall、IP3bet→OOPcallの4つの局面でプリフロレンジとスタックの異なる複数の集合分析を行い
それらのFlopとTurnのCB頻度を予測する機械学習モデルを構築し、そのモデルを解釈することによってヒューリスティックを構築しました
分析結果とその考察
モデルが示した傾向(ヒューリスティック)
構築された機械学習モデルを解釈した結果、全ての局面のCB頻度の予測に関して、モデルは次の傾向を示しました
(EQは全てストリート開始時点のものを指しています)
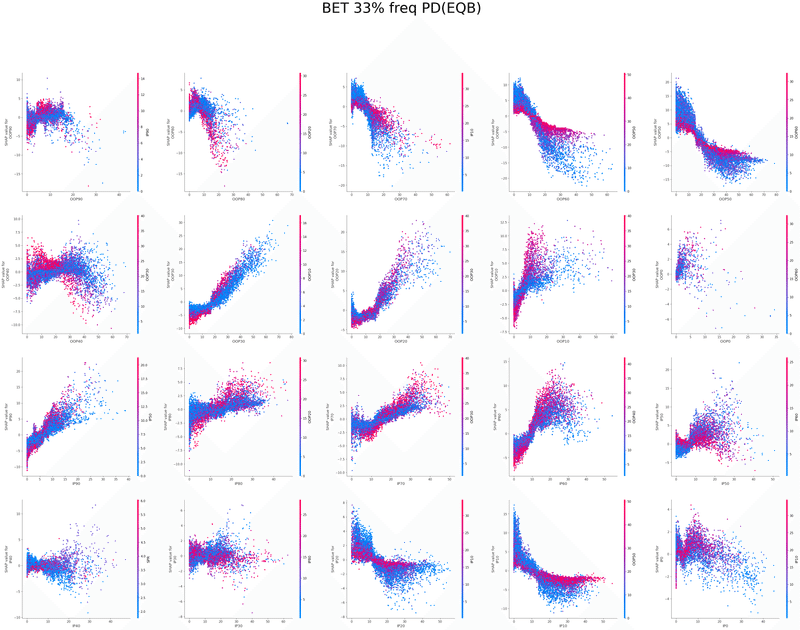
相手レンジのEQ80%以上の比率が上がると大サイズベットの頻度が下がる
相手レンジのEQ80-50%の比率が上がると大サイズベットの頻度が上がり
小サイズベットの頻度が下がる(OOPの場合はEQ70-40)相手レンジのEQ50%以下の比率が上がると小サイズベットの頻度が上がり、大サイズベットの頻度が下がる(OOPの場合はEQ40%以下)
自レンジのEQ80%以上の比率が上がると大サイズベットよりも小サイズベットの頻度を上昇させる
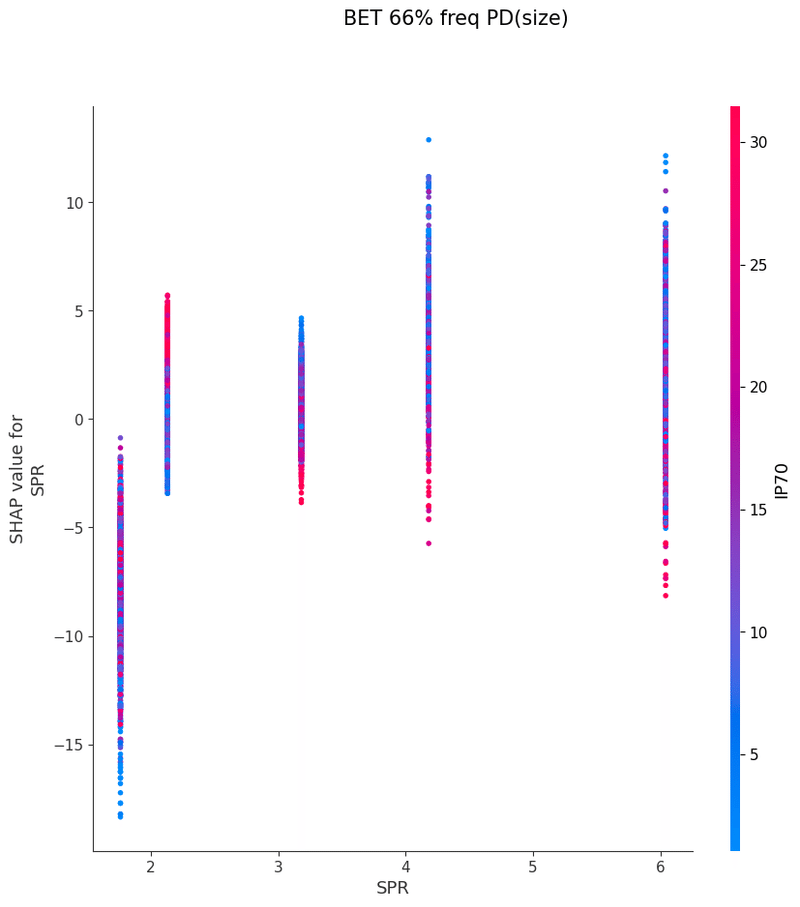
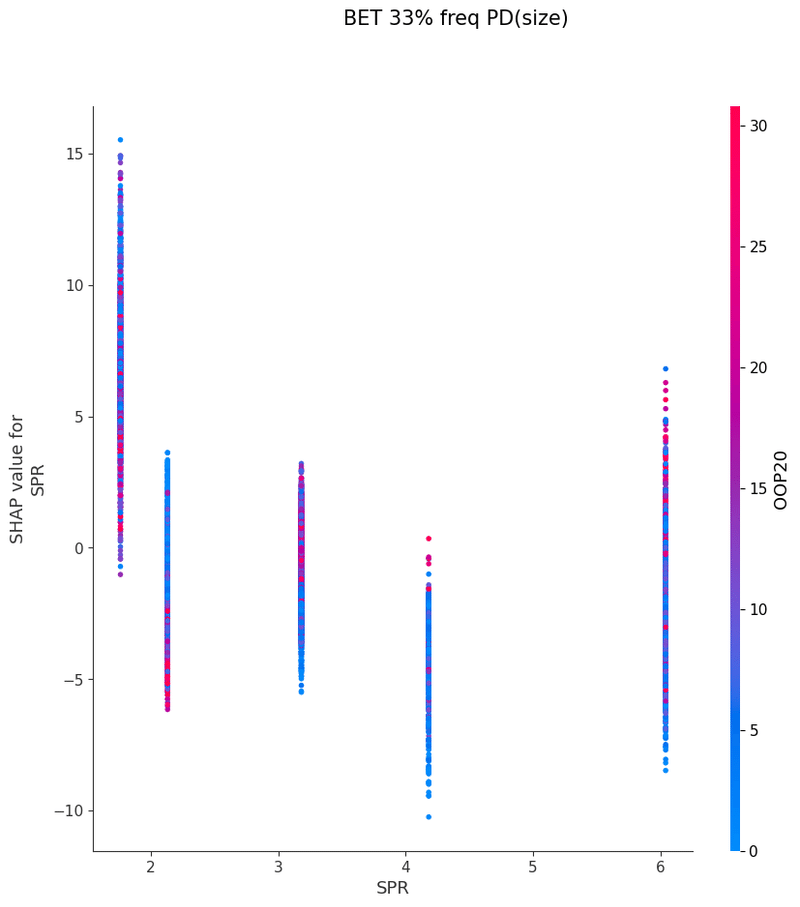
SPRが低いと小サイズベットが好まれる
傾向の考察
示された傾向についての筆者なりの考察です
1.
相手のレンジに占める強いハンドの割合が多い場合、大きいベットに対するディフェンスレンジはほぼ強ハンドのみで構成されることになり、そのレンジに対して十分なEQを確保できるベットレンジは狭いものになるからと考えられます
2と3.
相手レンジに多い部分をindifferentしようとしている
ポジションによる違いについてはIPはポジションによってEVが底上げされているのでベットサイズが同じでもindifferentされるレンジのEQがOOPと比べて下がることが原因と考えます
4.
自レンジの強いハンドが占める割合が多いとチェック頻度が下がる傾向がある一方で、自レンジの強いハンドが多くなるボードはペアボードの様な相手も強いハンドを多く持つボードが多く、それによって大サイズの頻度が抑制されるので、自レンジの強ハンド割合と小サイズベットの間に相関が生じたと考えています
5.
SPRが低い状況だと大サイズベットがジオメトリックサイズを超えてしまい、また、ジオメトリック以上のサイズを使うことが肯定される状況は限定されているのだと思います
※ここから先は今回行った機械学習とその解釈についての詳細です、それらに興味がなければ読まなくても大丈夫です
分析方法の詳細
Piosolverの設定
レンジとスタックの設定
IP2bet→OOPcall
BTNvsBB (vsGTO):200,100,50BB (vsRec):100BB
OOP2bet→IPcc
UTGvsBTN (vsGTO):100BB (vsRec):100BB
OOP3bet→IPcall
SBvsBTN (vsGTO):200,100,50BB (vsRec):100BB
SBvsUTG (vsGTO):100BB (vsRec): 100BB
BBvsBTN (vsGTO):100BB
IP3bet→OOPcall
BTNvsCO (vsGTO):200,100,50BB (vsRec):100BB
BTNvsUTG (vsGTO):100BB (vsRec):100BB
ベットサイズ設定
2betpot Flop:33,66 Turn:66,150 River:66,150 Raise:50
3betpot Flop:33,66 Turn:33,66 River:66,AI Raise:33
Subset設定
Flop:1755flop
Turn:184flop
精度
2betpot:0.3%
3betpot:0.1%
アクション予測モデルの構築
説明変数
OOP,IP双方の10%刻みのEQBとSPRの合計21種類
(それぞれストリート開始時の値を使っています)
目的変数
各アクションの頻度
として合計24個の機械学習モデルをLightGBMで作成しました
元データを8:2で学習データとテストデータに分け、テストデータに対する決定係数(R2)と誤差平均(MAE)を計測した結果は次の通りです
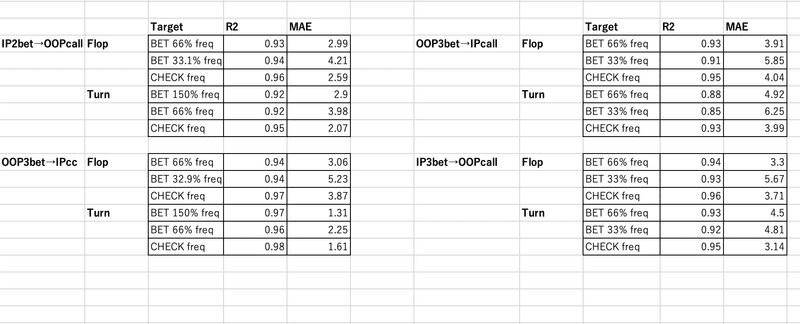
構築されたモデルの決定係数と誤差平均は共に良好で精度の高いモデルが構築できたと言えます
(EQBとSPRだけでこれだけのスコアが出るとは思ってなかったので驚きでした!)
分析結果の詳細
モデル解釈の方法
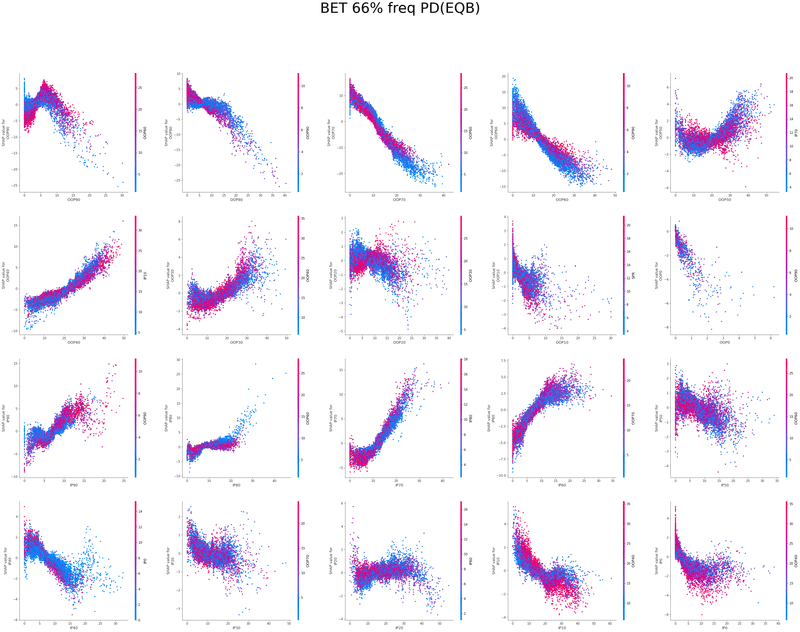
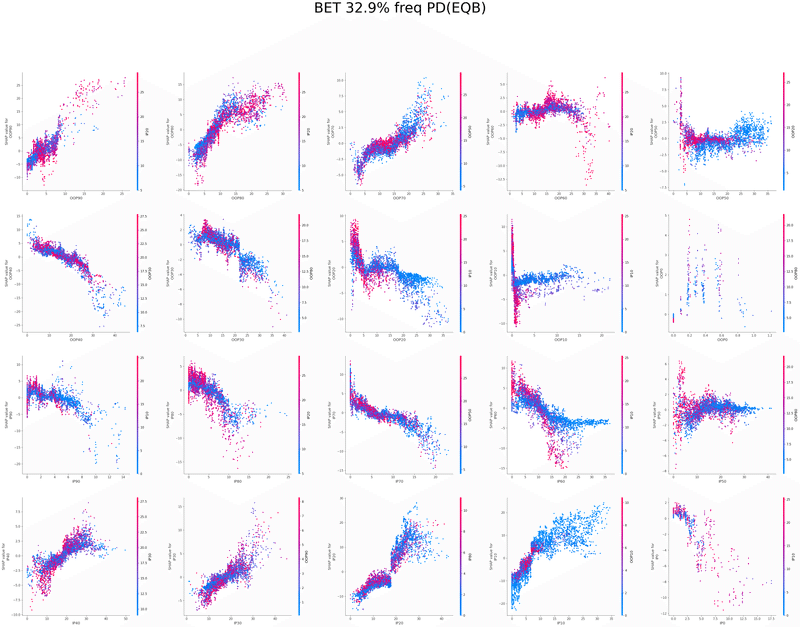
SHAPを使い各特徴量が予測値に与える影響を可視化することでモデルの解釈を行いました
グラフの各点は1つのボードにおけるアクションの頻度、
各点の色はその特徴量と最も交互作用が強い特徴量の値、
横軸は特徴量の値、縦軸は予測値に与える影響をそれぞれ表しています
SHAPの詳細な説明は筆者には荷が重いので下記リンクやChatGPTなどを参照してください
数学に自信ニキ向け
(筆者は書籍「機械学習を解釈する技術」で勉強しました、構成が素晴らしいのでおすすめです)
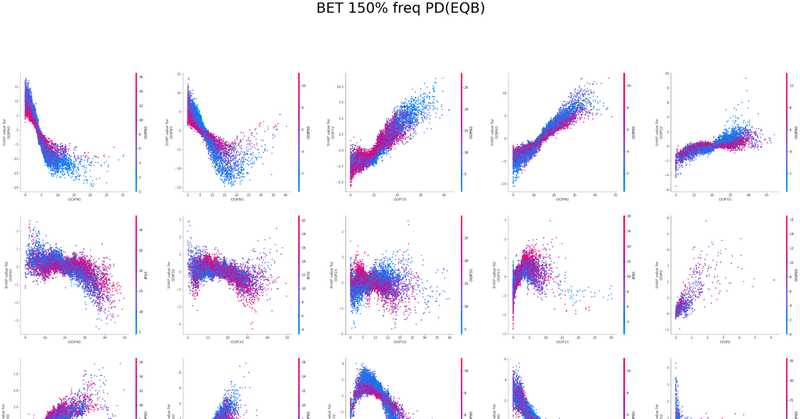
以下は今回の分析で作成されたグラフの一覧です、これらを見てヒューリスティックの構築を行いました
IP2bet→OOPcall FlopCB
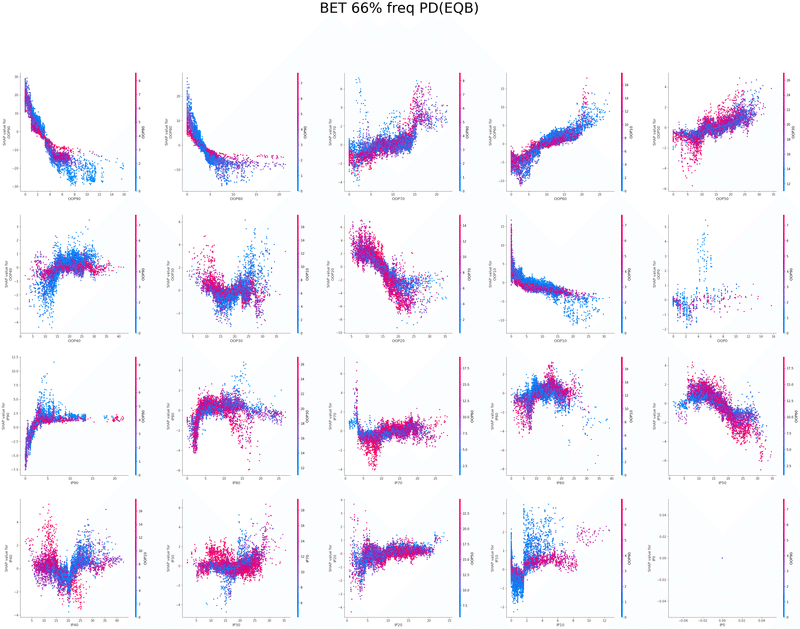


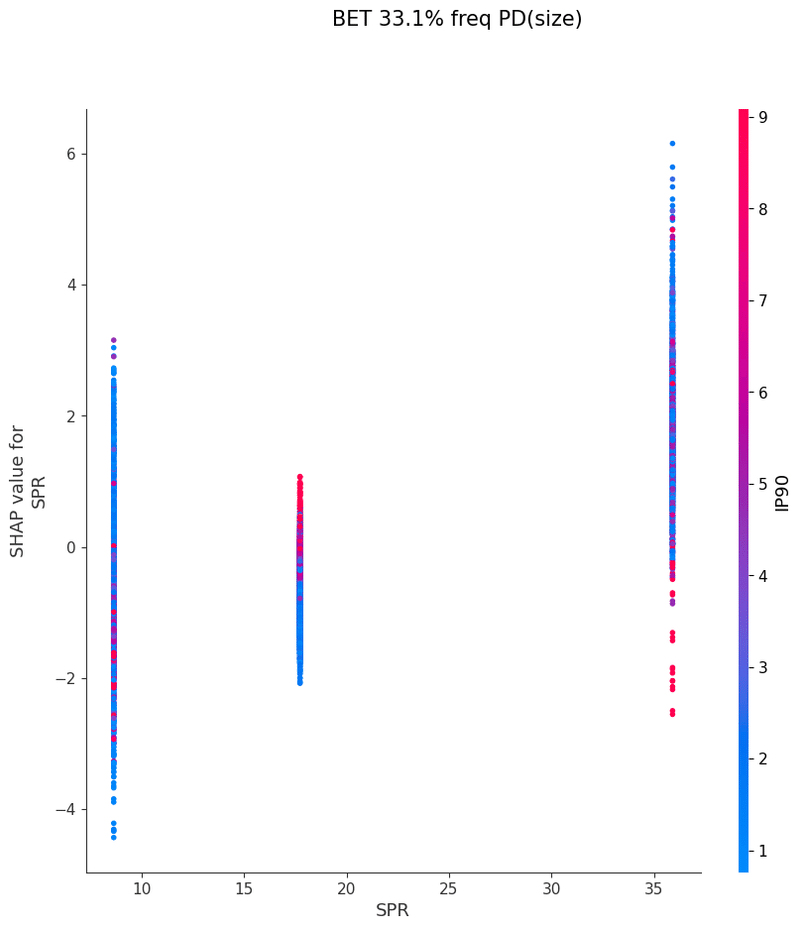
IP2bet→OOPcall TurnCB
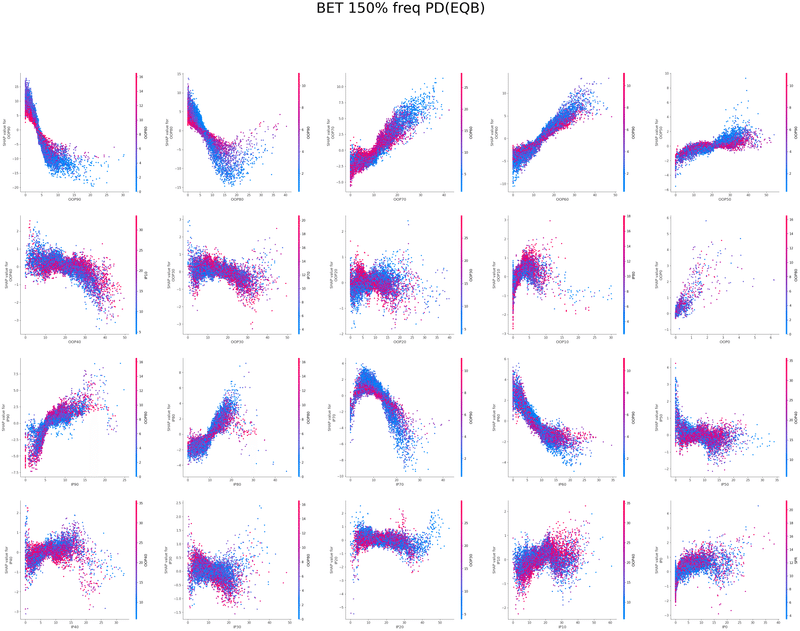
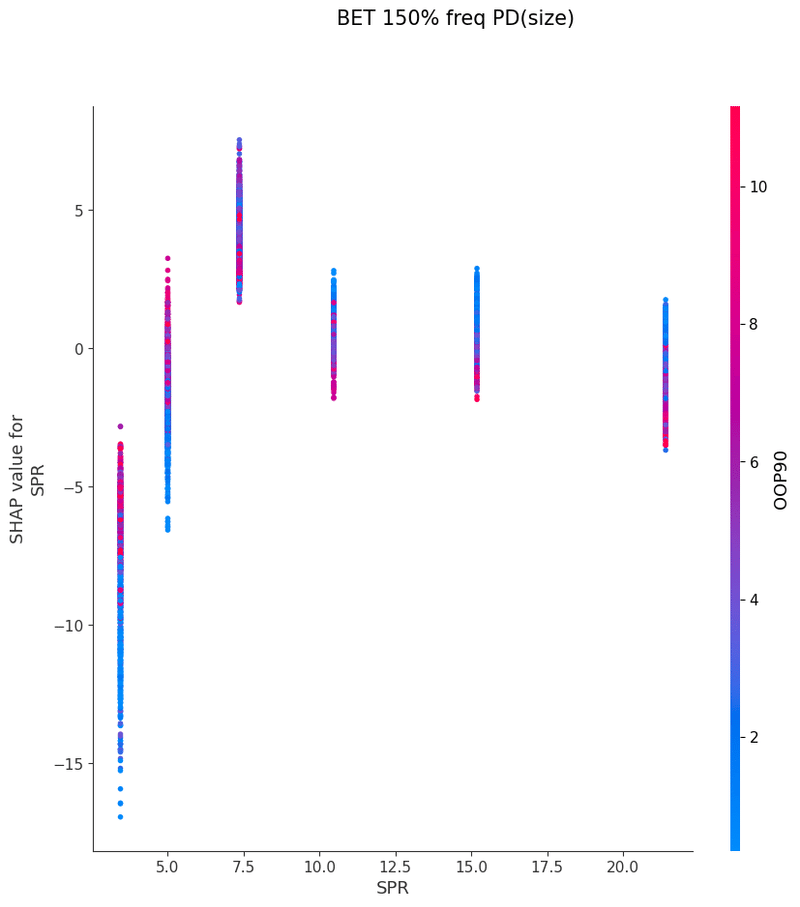

OOP2bet→IPcc FlopCB

OOP2bet→IPcc TurnCB
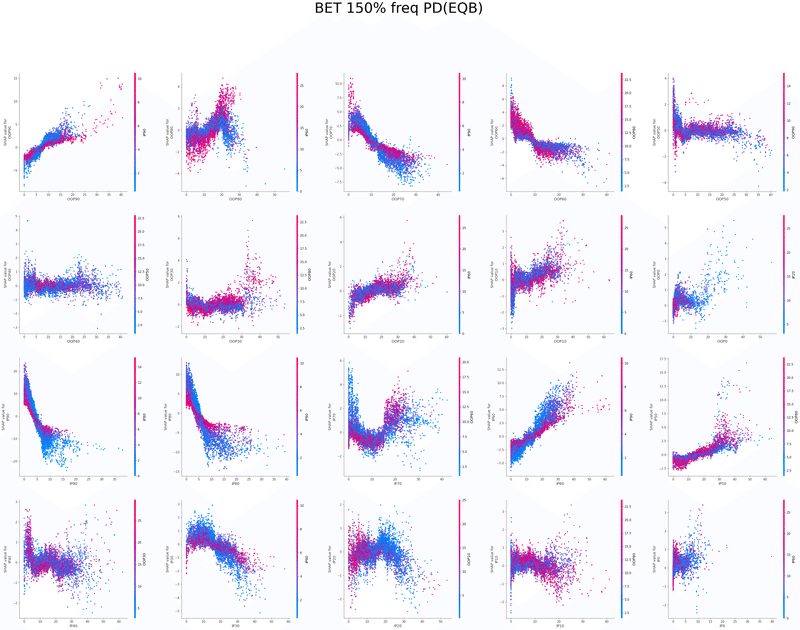
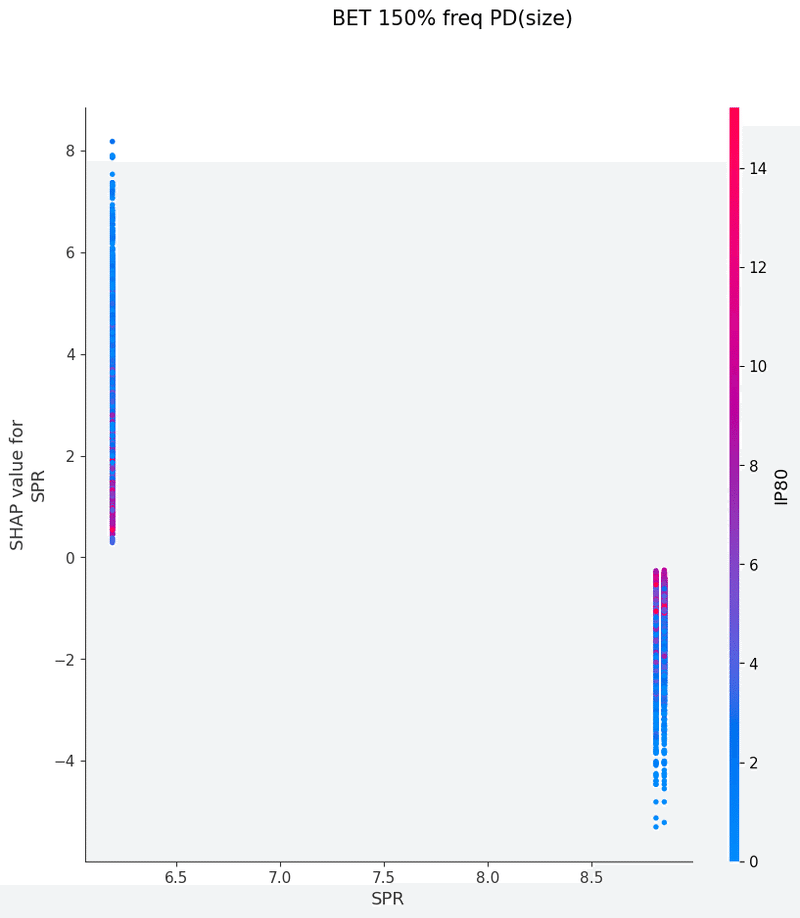
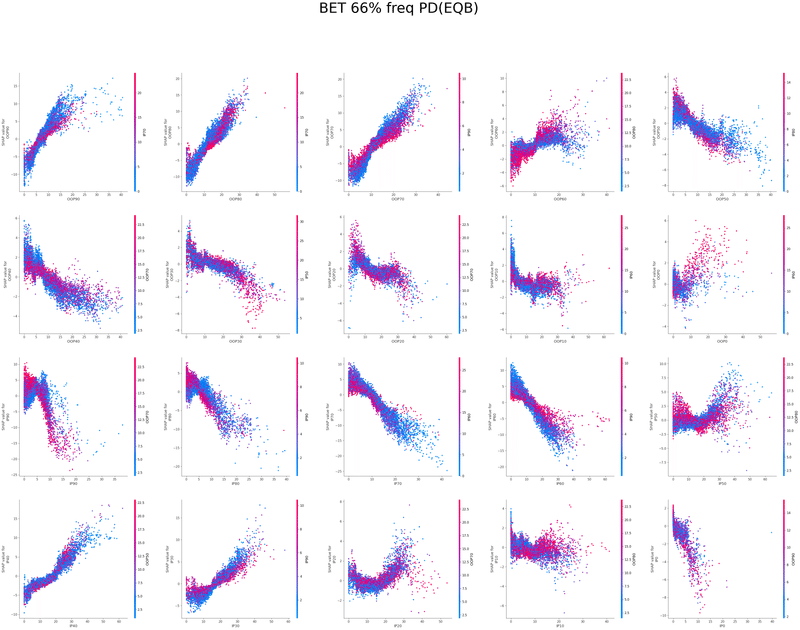
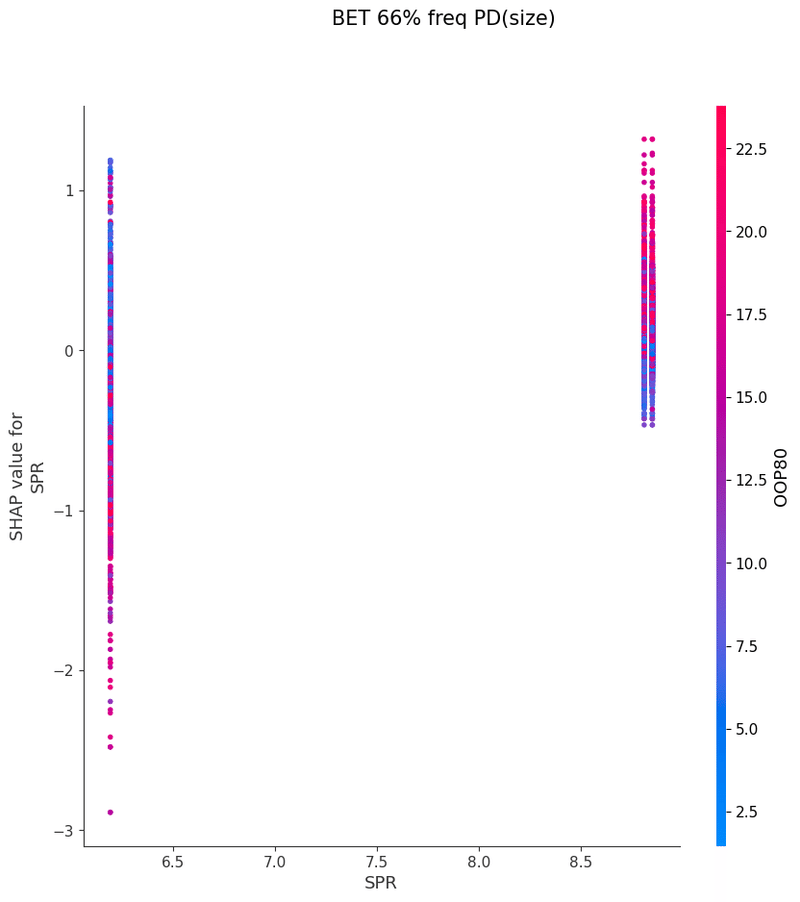
OOP3bet→IPcall FlopCB
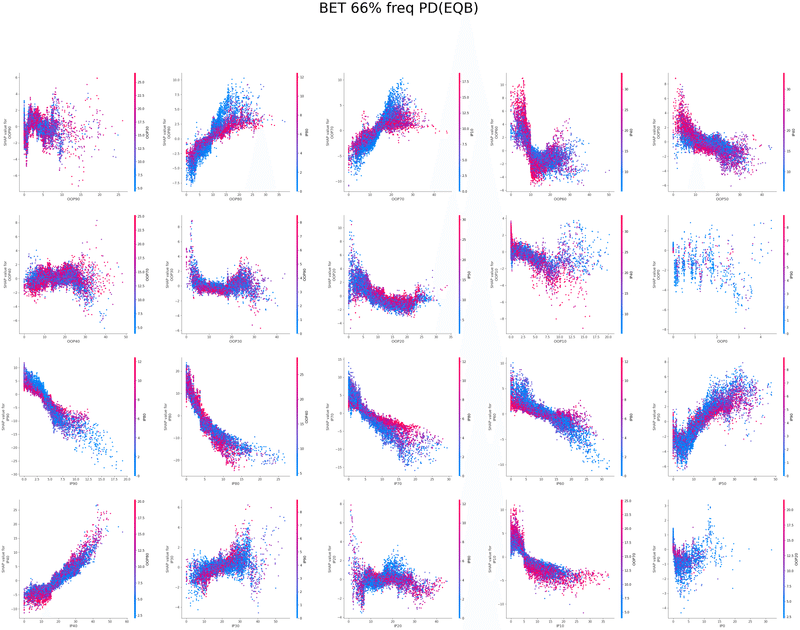
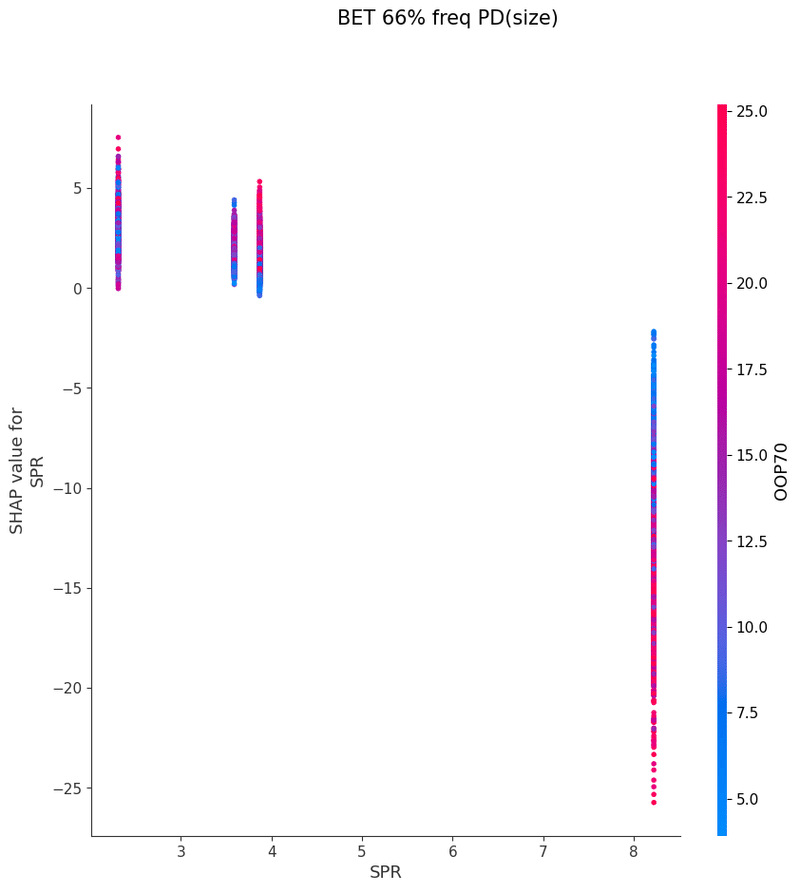
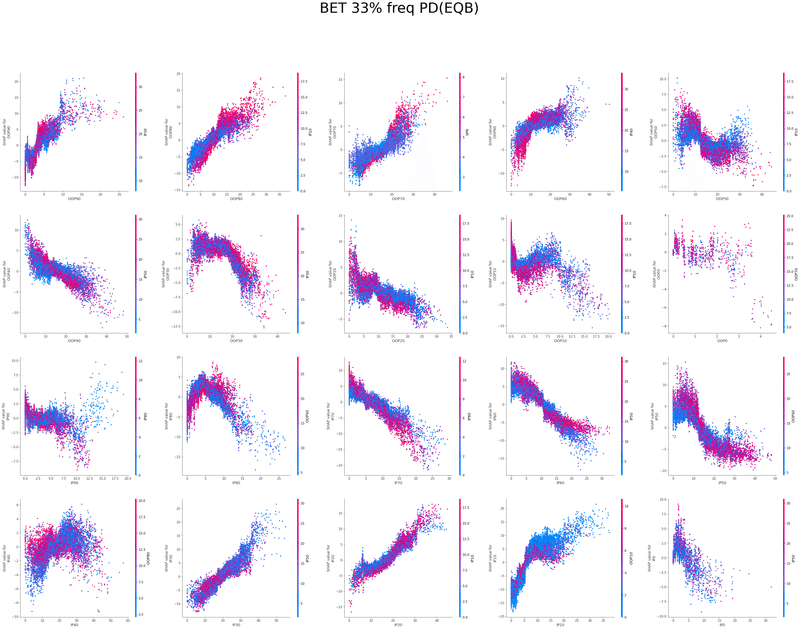
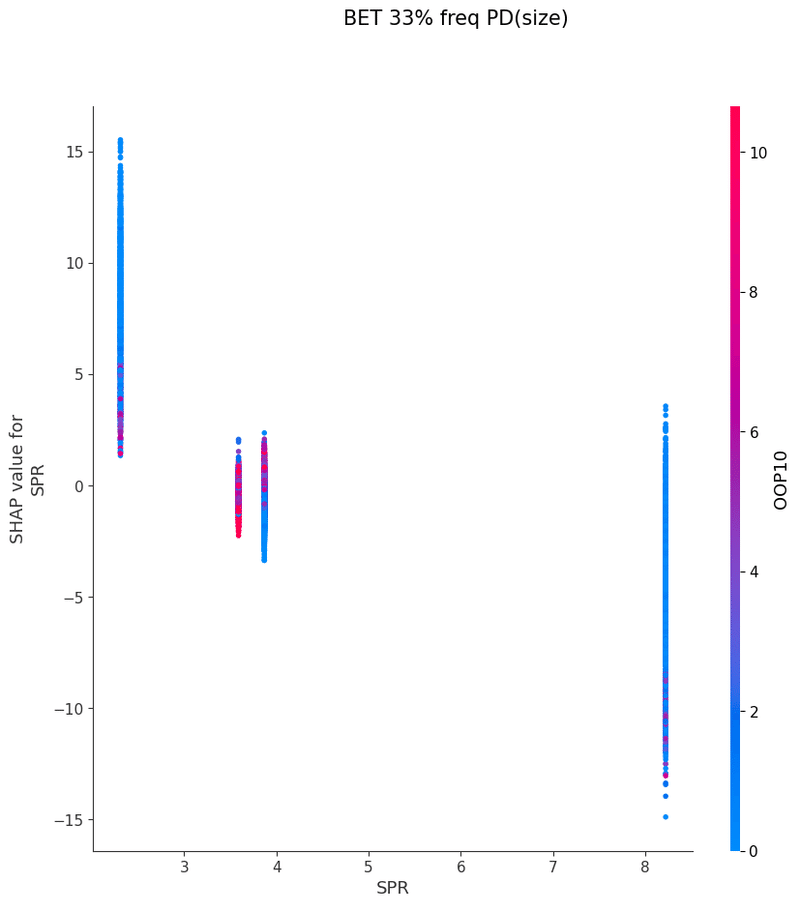
OOP3bet→IPcall TurnCB
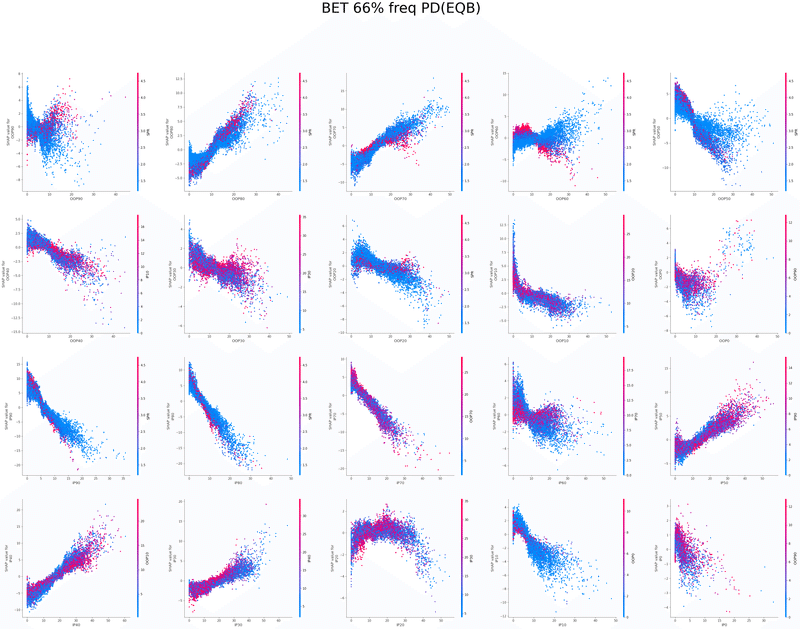
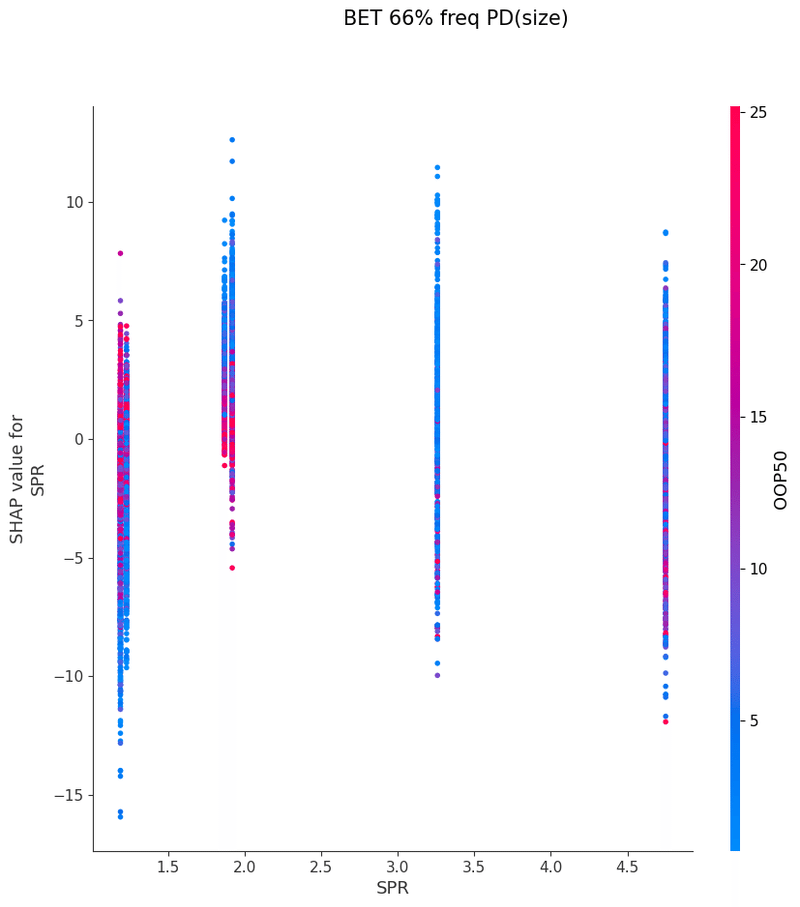
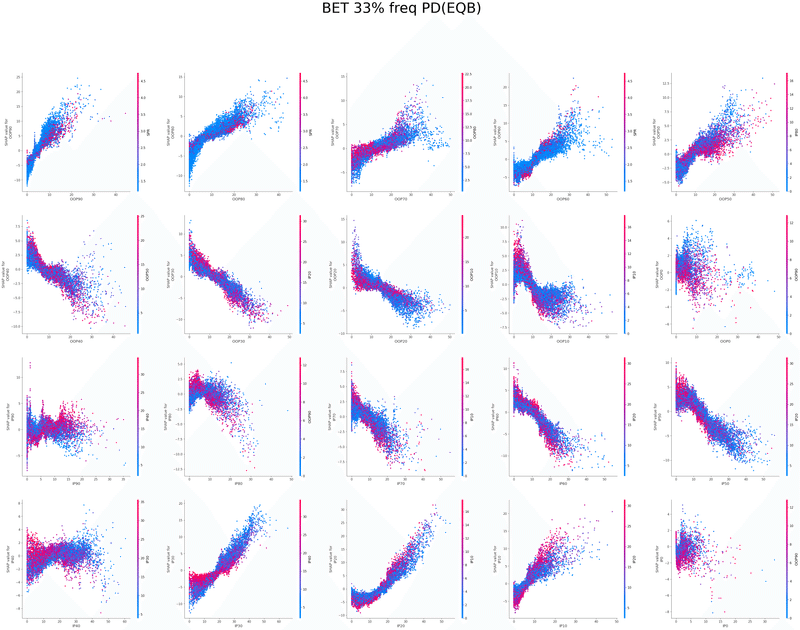
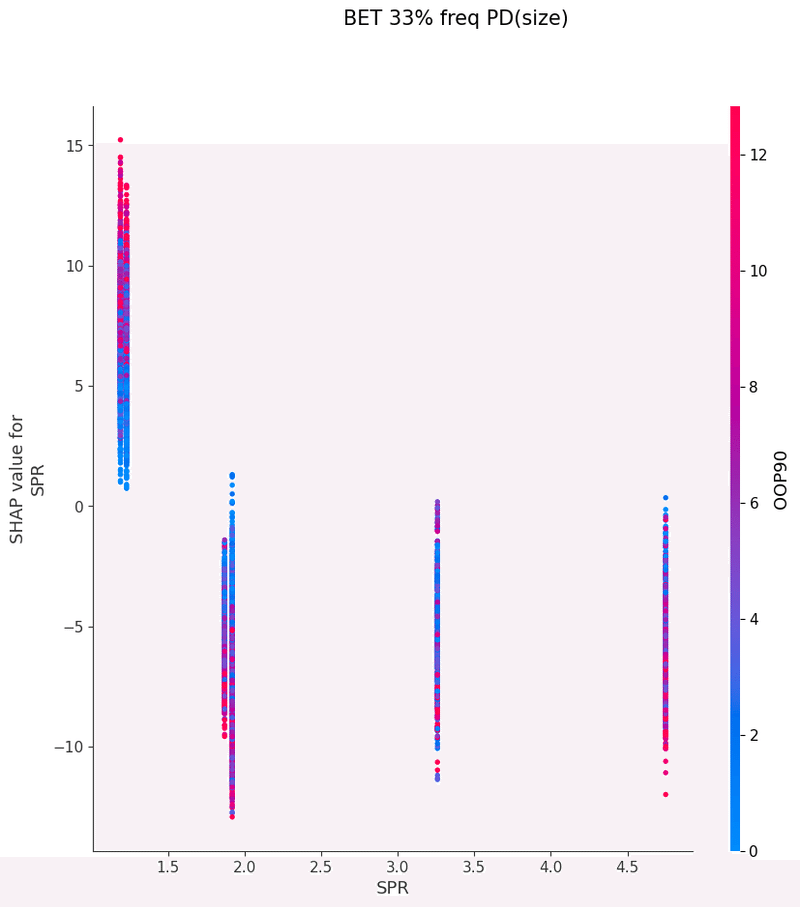
IP3bet→OOPcall FlopCB

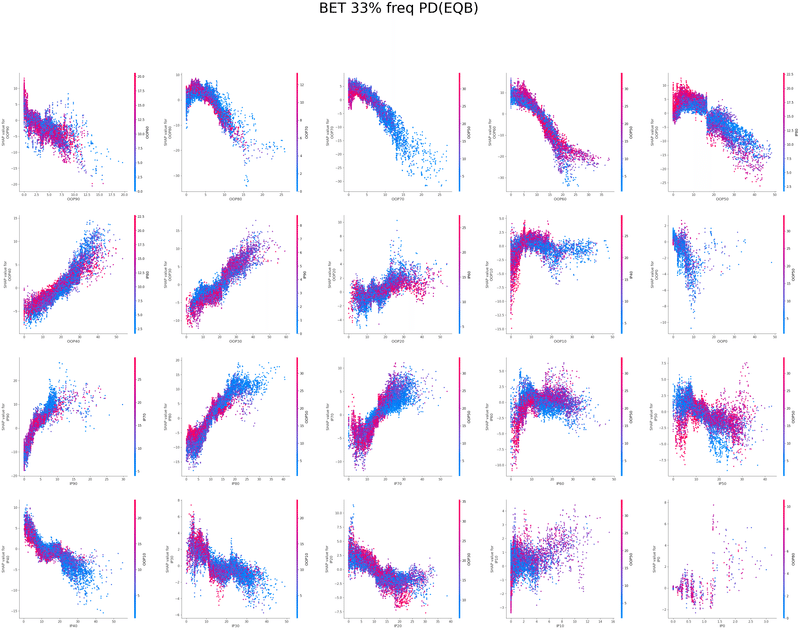
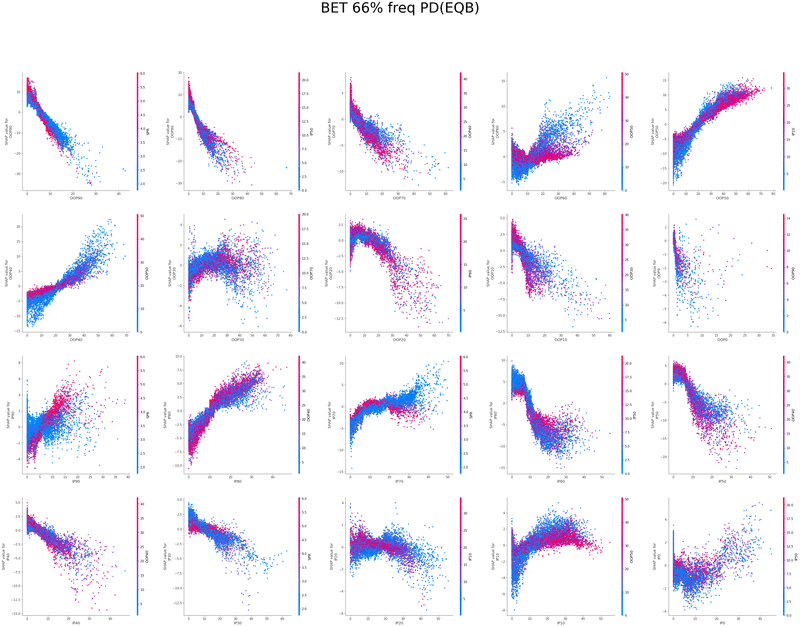
IP3bet→OOPcall TurnCB
この記事が気に入ったらサポートをしてみませんか?