
(3/20更新)Kohya版LoRA学習環境 簡単スタンドアローンセットアップ(※bmaltais氏の『Kohya's GUI』の導入)

2023/08/05 (v21.8.8)
■はじめに
AUTOMATIC1111 webuiのスタンドアローン化に引き続き、PythonやGiTをインストールしていなくても導入出来るKohya版LoRAの学習環境についてあれやこれやしてみました。ただ、今回はAUTOMATIC1111webui以上に技術者向けの世界なので、ある程度わかる方だけを対象とさせて頂きます。
また、Kohya版LoRAそのものについては沢山の解説ブログなどがあるので、基本的にはそういった方々の解説を読んで頂ければと思います。
■Kohya版LoRAとは
日本人のKohya S.氏という方が作ったStableDiffusion用の学習スクリプトのことで、通称Kohya版LoRA、または単純にLoRAとも呼ばれています。
そもそもLoRAとは追加学習であるDreamboothの拡張機能だったのですが、現在はKohya氏が改良したものが主流となっているようです。
Kohya氏の公式リポジトリ
https://github.com/kohya-ss/sd-scripts
Kohya氏による公式ガイド
(↓追加学習をするなら必ず読むべし↓)
https://github.com/kohya-ss/sd-scripts/blob/main/train_README-ja.md
■bmaltais式WebUI 『Kohya's GUI』の導入
本家のKohya版LoRAは導入も運用もコマンドプロンプトオンリーという中々に玄人向けな作りになっていますが、bmaltais氏という方が作ったWebUIバージョン(ブラウザ上で視覚的に扱うことが出来るツール)なら、ある程度の知識さえあれば比較的ラクにLoRAによる追加学習が出来ます。
本記事で紹介するやり方はpythonやgitを直接インストールせずに導入するというやや特殊な方法ですが、すでにpythonやgitがインストールされている環境下でもたぶん動くと思います。
bmaltais氏の公式リポジトリ Kohya's GUI
https://github.com/bmaltais/kohya_ss
■必要環境
AUTOMATIC1111 WebUIを問題なく運用出来ている環境であれば大丈夫だと思いますが、VRAMがあまりにも低いGPUでは厳しいかもしれません。一応DreamBoothなどの他の学習法よりはかなり必要スペックは緩和されているので、おそらく1000番台Vram6GB以上であればギリギリ動くかもしれません。
そのあたりの詳しい対応については申し訳ないですが自身で調べてみてください。
■セットアップ
まずはセットアップ用のファイルをダウンロードしてください。
※2023/02/21更新
ダウンロードしたファイルを解凍すると、kohya_ss_webuiという名前のフォルダが出てくるので、このフォルダをインストールしたい場所に置いてください。
ただしデスクトップは避けてください。また、日本語を使用したフォルダや極端に長い名前のフォルダの中も避けてください。ファイル名の問題で導入や運用でエラーが出る可能性が高いです。よくわからない場合は、Cドライブの直下やDドライブの直下などが無難です。

中には、Python3.10.6フォルダ丸ごとと、機能を最小限にしたGitフォルダ、そして2つのバッチファイルが入っています。
その中のkohya_ss_webui_Run.batがセットアップ兼起動ファイルとなっているので、これをクリックしてセットアップを開始します。
AUTOMATIC1111の導入と同じく、途中とても時間のかかる部分がありますが、フリーズではないのでウィンドウは閉じないでください。
セットアップが無事完了すると、自動的にブラウザが開いてWebUIが表示されます。また、AUTOMATIC1111同様プロンプトウィンドウは起動中のプログラム本体ですので、決して閉じないようにしてください。
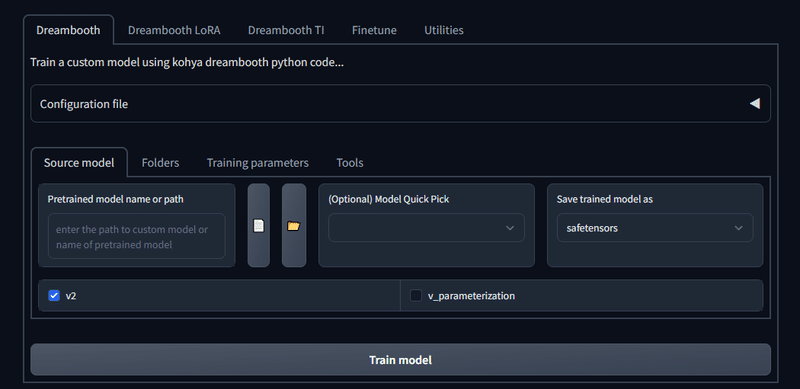
ご覧のように、LoRAだけでなく他の追加学習機能も一緒になっています。
ちなみに動作確認はLoRAだけしかしてません!←
Utilitiesタブには様々な便利な機能がいくつかありますが、初回使用時に必要ファイルのインストールを行うものがあるので、その都度プロンプトウィンドウをよく確認してインストール完了まで待つようにしてください。
■なんかエラー出た
出ましたか。
このGUI、本来の公式Kohya版に更新があった場合、大抵それに合わせてすぐアップデートがあるのですが、ちょうどそのバージョンが噛み合ってない時に導入したりするとエラーが出て動かなかったりします。
もうわりと頻繁に。なので安定して使えてるバージョンはバージョンアップ前に一旦とっておいたほうがいいかもしれません。
なにはともあれ、ひとまずは、kohya_ss_webui_update.batを使ってwebui自体を更新してみましょう。そして再起動。
まだだめ。エラー。
もうこうなったら以下の無理やりアップデーターを使って強引に公式からファイルを引っ張ってきます。もしかすると解決するかもしれません。
無理やりアップデーター
ただ、あまり好ましい方法ではないので、本家に大きなアップデートがあった時は新規に再導入してみてください。また、元の環境を残したまま導入したい時は、新規に導入するほうのフォルダ名(kohya_ss_webui)を別の名前に変更してください。
Kohya氏の公式リポジトリ
https://github.com/kohya-ss/sd-scripts
■高速化オプション
RTX 30X0/40X0 をお持ちの方はさらに学習速度を上げることができます。公式によると4090でほぼ50%UPとのこと。
まずは以下より必要なファイルをダウンロードします。
CUDNN 8.6
https://b1.thefileditch.ch/mwxKTEtelILoIbMbruuM.zip
解凍すると、中からcudnn_windowsというフォルダが出てくるので、これをkohya_ssフォルダの中に入れます。
準備が出来たら、以下のファイルをダウンロードし、kohya_ss_webuiフォルダ内で実行してください。こっちはさっきの場所と違ってkohya_ss_webuiフォルダなので間違えないように。
■ざっくりと使い方説明
Kohya版LoRAの学習そのものに関してはとにかく色んなところで詳しい解説が出ているので、出来ればそっちを読んで頂きたいです(何度でも言います)
本記事ではあくまでもツールの簡単な使い方と流れだけを説明出来ればと思っております。
また、本来の基本的な使い方を知りたい方はKoya's GUI公式にあるチュートリアル動画をご覧ください。なんならそれだけ見れば全て解決です。
Kohya's GUI
https://github.com/bmaltais/kohya_ss
・素材集め
今回は人物やキャラクターを学習する流れで説明をしたいと思います。なにはともあれ、まずは素材集めです。
ただし、著作権が絡むキャラクターや実在の人物などを学習するのは非常に危険な行為なので注意してください。作るなとは言いませんが、決して世に出してはダメですよ。特に実在の人物は裁判沙汰になりかねません。
CIVITAIに著名人を学習したLoRAが山の様にアップされてますが絶対に真似しちゃダメですよ!
というわけで、今回は筆者が身体を張って自身の近影を10枚ほど用意しました。画像のファイル名はなんでもいいですが、日本語が入っていたり長すぎるとエラーが出るようです。2~30枚あったほうが安定しますが、まぁ、10枚でもいけるはず、たぶん。
今回は画像のサイズを512x512で統一していますが、必ずしも全て揃ってなければいけないというわけではありません。
大きくても小さくても、縦横比が違っていても、指定サイズ内にテキトーに処理してくれます。なんならネットで検索してきた画像をそのままテキトーに放り込んでも大丈夫(らしい)
ただ、それでも学習精度を高めたいのであれば、出来ればレタッチソフトなどで人物のみを切り出したりなど、入念に準備をしたほうがより良い結果が得られるとは思います。
さて、まずはこの集めた画像ひとつひとつに、その特徴や要素を説明するキャプションをテキストファイルで用意していきます。簡単に言うと『青い人が、白い背景の前に、立ってる』といったものです。もちろん英語タグで。画像の数だけ。
そんなものをちまちま書いていたらさすがに面倒なので、自動キャプションを使ってタグ付けをしてみます。
Utilitiesの中のWD14 Captioningというdanbooruタグ特化のタガーがあります。これはフォルダ内の画像を見て、そこから自動的にAIがタグをつけてくれるというものです。
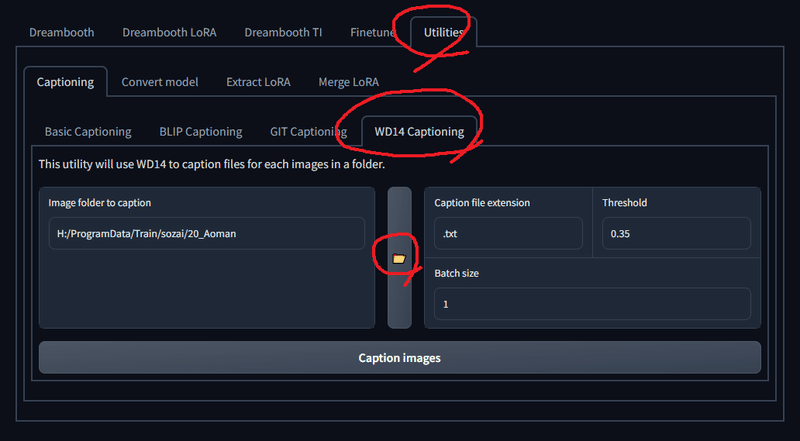
ただ、これに関してはAUTOMATIC1111webuiのExtensionからインストールできるstable-diffusion-webui-wd14-taggerのほうが断然高性能かなと思うので、面倒でなければそっちを使ったほうが良いと思います。
今回はせっかくなのでWD14 Captioningを使用してみます。
フォルダマークをクリックして画像の入っているフォルダを選択したら、一番下のCaptioning imagesを押してスタート。
ちゃんとキャプションができているか確認するために、niel_001.txt をメモ帳で開いてみます。
solo, looking_at_viewer, smile, open_mouth, black_eyes, no_humans, colored_skin, transparent_background, blue_theme, straight-on
no_humans だそうです。わりと正確ですね。
ただ、オートだとどうしても不要なタグが出来てしまうので、不必要なタグを削除して整理します。
太字で示した部分がおおよそ今回の学習させたい人物を説明しているタグです。本来であればsmileも表情のみを表しているので人物を直接表すタグではないのですが、笑顔がこの顔の標準なので今回はsmileも含みます。
なるほど、じゃあ人物を表すタグを残せばいいのだな?と思うかもしれませんが、逆です。キャプションに書くべきタグは
「呼び出しキーワード」+「学習から外したいもの」
よって先程のタグを整理するとこうなります。
Aoman, solo, looking_at_viewer, transparent_background, straight-on
呼び出し用のキーワードとして、Aoman というタグを新規に作り、先ほどの人物描写を全て削除しました。これは先程の人物描写の全てをAomanというタグに集約したということです。
ようは、この画像は『Aomanというキャラクターが、一人で白い背景の前にいる』という絵なのだと教え込むわけです。
そんな調子で全て修正していきましょう。
とはいえこんなものひとつひとつメモ帳でやってたらキリがありません。便利なツールがいくつも作られていますのでありがたくそれらを使わせてもらいましょう。
BooruDatasetTagManager
https://github.com/starik222/BooruDatasetTagManager
また、詳しいキャプショニングについては作者であるKohya氏のReadmeやwikiなどを読んでみてください。
fine_tune_README_ja.md
https://github.com/kohya-ss/sd-scripts/blob/main/fine_tune_README_ja.md
キャラクター学習のタグ付け一例
https://rentry.org/dsvqnd
また、キャプショニングに関しても、これが正解というわけではありません。場合によっては無編集でもうまくいくこともあります。
だいたいさっきから、キャプションって言ったりタグって言ったりキャプショニングって言ったりタガーとかタグ付けって言ったり、説明するなら呼び名ぐらい統一しろよ!って思うかもしれませんが、他所での説明も言い方がバラバラなので筆者も困ってます。もうなんとなく雰囲気で覚えてください(雑
・モデル選択
画像が整ったら、次はそれをどんなモデルを基準にして学習させるかを選びます。Source modelタブを開いてみてください。
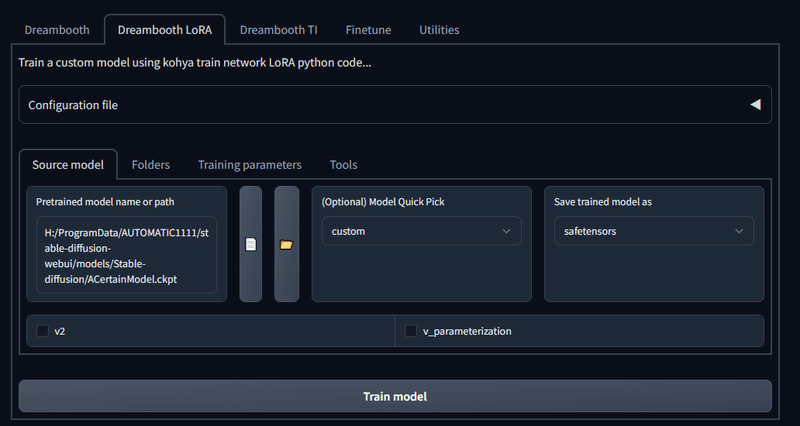
学習モデルの種類は、実写なら実写向け、イラストならイラスト向けのモデルなど多岐に渡りますが、世の中に出回っているマージ系モデルのほとんどが過学習状態なので、実はあまり学習にはむいていません。
使うととてもピーキーな仕上がりになりがちですし、なにより特定のモデル専用のLoRAになってしまいます。
なので、基本的にベースモデルはシンプルなものを選びましょう。
実写であれば、公式モデルであるSD1.4かSD1.5、イラスト系であれば、ACertainModelというイラスト用学習向けモデルが界隈ではオススメだそうです。また、沢山のモデルの元となったNAIなどが人気のようですがそこに関してはノーコメントにさせてください。
ACertainModel
https://huggingface.co/JosephusCheung/ACertainModel
また、今回は汎用性を重視して、StableDiffusion 1.x系ベースの学習にするので、v2 にチェックが入っている場合はチェックを外します。逆に2.x系で学習する場合はチェックを入れます。
・フォルダ選択
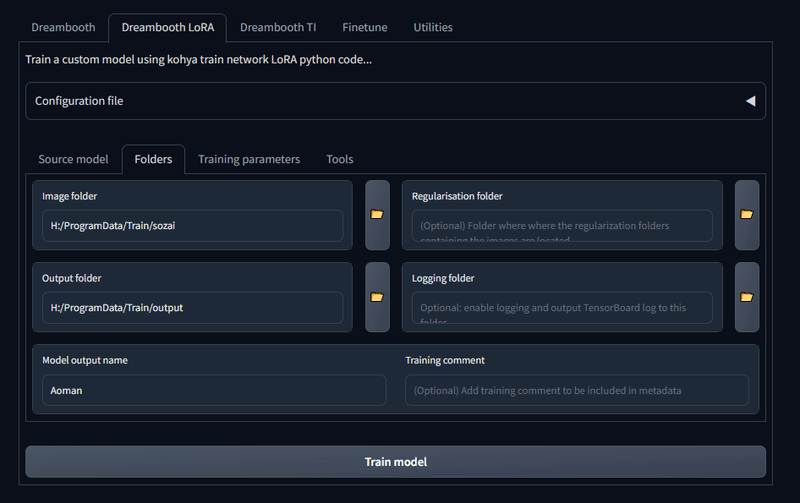
フォルダタブに移動して画像フォルダを指定します。
が、ここで注意。
ここで選択する画像フォルダとは、画像が入っているフォルダそのものではなく、そのひとつ上の階層のフォルダでなります。なので、フォルダ構造も以下のようになります。
上の階層のフォルダ/画像が入っているフォルダ
今回は、sozaiという名前のフォルダを作り、その中に画像フォルダを入れました。また画像を入れておくフォルダ名にも決まりがあり、以下のルールに従って名前をつけてください。
学習の繰り返し回数_呼び出し用インスタンスプロンプト
繰り返し回数はKohya氏が20に設定していたのでそのまんま真似しておきます。呼び出し用のプロンプトは青い人ということでAomanとしました。
よって筆者の場合は、20_Aoman というフォルダ名になります。
Output folderの設定もしておきます。これは最終的にLoRAファイルが出力されるフォルダです。LoRAの名前もこの段階で決められるので、Model output name にも Aoman と入れました。
■学習設定
最後にTraining parametersタブを選択して、学習方法などの細かな設定をします。正直、これに関しては学習目的や学習内容、集めた画像やキャラクターの方向性、個人のPC環境などによってあまりにも様々過ぎて、これだ!という設定はありません。何度もトライアンドエラーする他ないです。
よくわからない場合は、まずは初期設定のまま行ってみましょう。
とりあえず今回は、Epochを20にしようと思います。
Epocとは『学習を何セットするか』という回数です。先程画像の繰り返し回数を20に設定したので、
画像10枚x20回x20Epoch = 4000 step
ということになります。
ちなみにこれ、別に多ければいいってもんでもありません。今回は画像の数が少ない&やや難解なキャラクターだったので多めに回してみることにしましたが、条件によっては半分以下でも十分ということもあります。
もしも学習具合を確認しつつ進めたいのであれば、あえて少なめのEpochにして確認、いまいちであればさらに続きから再学習、ということも可能です。
その他の設定も筆者の環境に合わせつつ、いくつかの項目を変更しました。
今回使用しているwebui版は公式の最新版より設定出来る項目が若干少ないです。
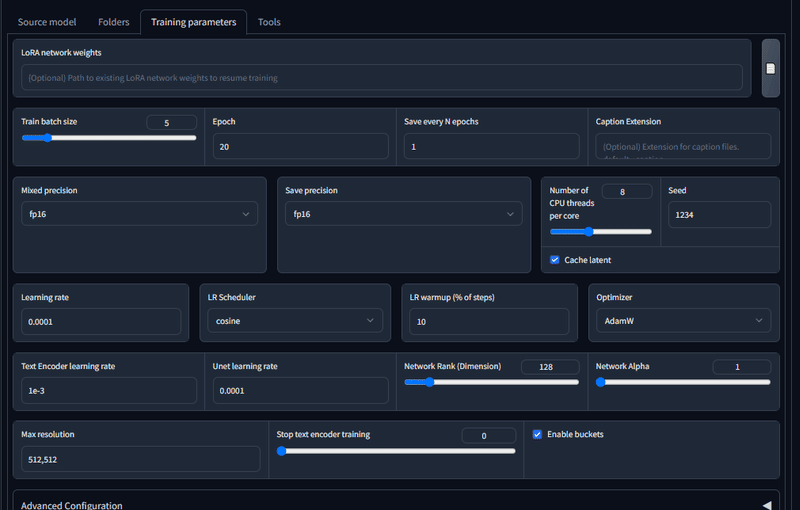
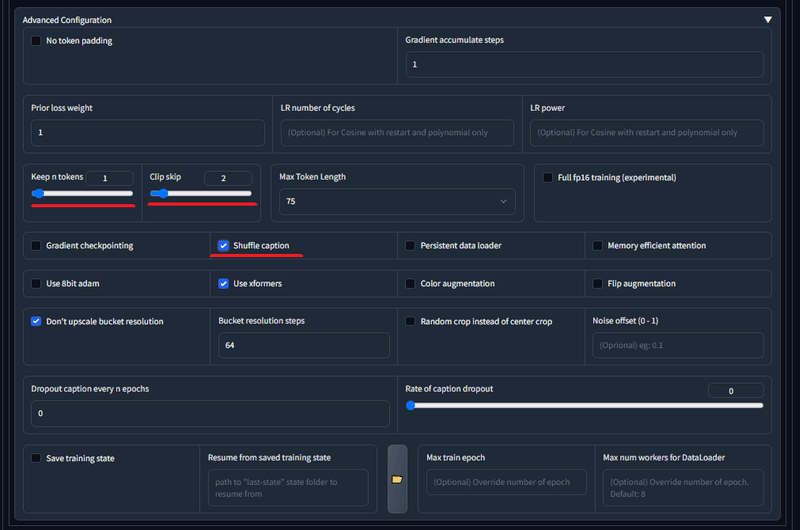
Shuffle captionにチェックを入れました。これは各タグをシャッフルしてタグの重みを分散させる効果があるのだとか。その代わりKeep n tokensを1にして、1番目のタグまでを保持(この場合は1番目にあるAomanタグ)にします。
このあたりの色んな設定の説明についても他所のブログやwikiなどで(以下略
としあきwikiとか(丸投げすんません
ひとまず設定が終わったら、Configuration fileボタンを押して設定を保存しておきましょう。
■学習開始!
では全ての準備が整いましたので、Train modelボタンをクリックして学習スタート!これならだいたい30分程度でしょうか?お茶でも飲んでのんびり待ちましょう。間違っても同じPCを使って画像生成でもしながら待とう!とかしてはダメです。今PCはフルパワーで働いている最中なので。
ちなみに筆者が以前使っていたPCは、作業中の熱がこもり過ぎて発火、マザーボードからモクモクと煙を吹いてお亡くなりになってしまいました。皆さんもPCの排熱にはくれぐれも気をつけてください。
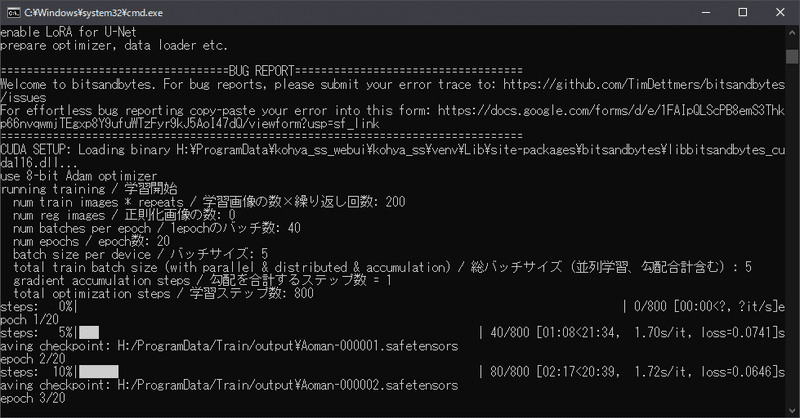
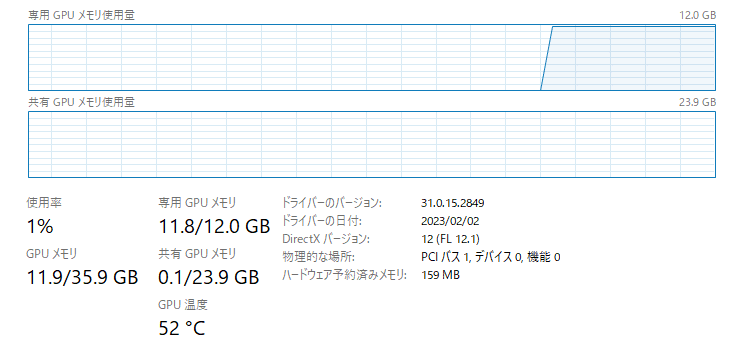
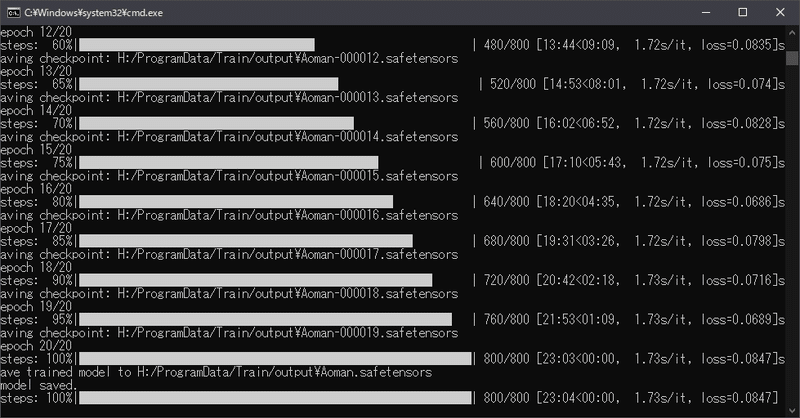
今回使用したPC環境 RTX3060 VRAM12GB でおよそ23分でした。
充分速いですね。
それでは無事に学習出来ているか確認してみましょう。
■LoRAを適用して画像生成
先程完成したLoRAファイル、Aoman.safetensors をAUTOMATIC1111webuiのLoRAフォルダに入れます。
webuiを起動し、モデルはAnything v4.5をにしてみます。
🎴マークを押してLoRAタブを表示し、目的のLoRAをクリックすると、プロンプトに
<lora:Aoman:1>
と記入されます。
しかし、今回の場合はこのまま生成してもダメなので、新たに作った呼び出しタグである Aoman を記述します。
<lora:Aoman:1> Aoman,
と入力して生成してみます。

こんなものでもなんとなく学習してくれます。
ただ、やはり完全にオリジナルな存在よりも、キャラクターであったり人物であったりするほうが学習結果は良いように思われます。何せベースが学習済みですから。
■なんかエラーでた
たぶん無理させたからか、環境が足りていない可能性があります。
最小限の設定にして、最低限学習が開始出来るかどうかを確認してみてください。
また、更新状況によってはある日突然エラーが出て動かなくなるということもわりとよくあるようです。
また、LoRA特有の問題に関してはあまり詳しくないので、申し訳ないですが質問には答えられないかもしれません。ごめんなさい。
■さいごに
だいぶ駆け足でしたが、なんとなく雰囲気でわかっていただけたでしょうか?
正直な話、今現在、マジガチで追加学習をやりたい!というのなら、普通にPythonやGitを導入し、上級者達と同じ環境下でやったほうが目的のものが作りやすいと思います。
もしも他の解説ブログなどを読んでみて、少しづつわかってきたぞ!というい方は、あえてチャレンジしてみても良いのでは。
とはいえ、すぐに出ると思いますけどね、簡単に出来るやつ。
それがわかっているのであえてLoRAはスルーしようと思ったのですが…
次回こそControl Netについて書きたいと思うのですが、まだ暫く未定です。
この記事が気に入ったらサポートをしてみませんか?