SMOTE (Synthetic Minority Over-sampling Technique)

SMOTEとは?
SMOTE(Synthetic Minority Over-sampling Technique)は、不均衡なデータセットの問題に対処するために開発されたオーバーサンプリングの手法です。オーバーサンプリングの主な目的は少数クラスのサンプル数を増加させることにより、クラス間のバランスを改善しモデルの学習性能を向上させることです。
この記事ではこのSMOTEを実践してみたいと思います。
デモンストレーション
不均衡なデータセットの用意
オーバーサンプリングのデモンストレーションに適した不均衡なデータセットを用意します。今回はKaggleのこちらのデータセットを用います。
このデータセットにはクレジットカードの取引が含まれています。2日間で発生した取引で、284,807件の取引のうち492件が不正取引です。不正取引はすべての取引のうちの0.17%です。
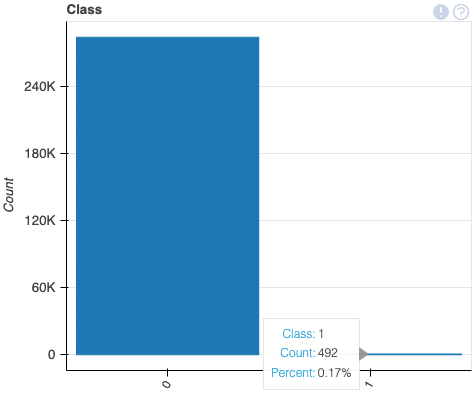
クレジットカードの不正取引を検出する分類問題のモデルを構築していきます。
データセットの読み込み
import pandas as pd
df = pd.read_csv("./creditcard.csv")データセットを読み込みます。
df.head(5)
訓練用と検証用のデータセットを分割
from sklearn.model_selection import train_test_split
X = df.drop(['Class'], axis=1)
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)モデルの学習
オーバーサンプリングを実施しない場合のベースラインモデルも構築します。今回はXGBoostを利用しました。
from xgboost import XGBClassifier
bst = XGBClassifier(n_estimators=2, max_depth=2, learning_rate=1, objective='binary:logistic')
bst.fit(X_train, y_train)
y_pred = bst.predict(X_test)評価
ベースラインモデルのconfusion matrixとrecallを算出してみます。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot()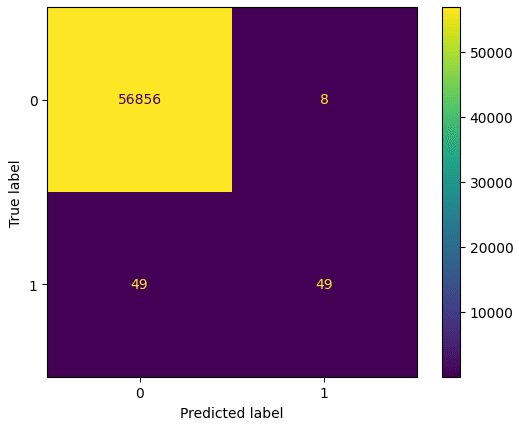
recall_score(y_test, y_pred)また、Recallは0.5となりました。
SMOTEによるオーバーサンプリング
インストール
imbalanced-learnというオープンソースのライブラリにSMOTEの実装があるため、今回はそちらを利用します。
pip install imbalanced-learnライブラリの読み込み
from imblearn.over_sampling import SMOTESMOTEクラスを読み込みます。
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)fit_resampleメソッドを呼び出すことで、SMOTEが実行されオーバーサンプリングされた新しい特徴量のセットと新しいクラスラベルのセットが生成されます。
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.2, random_state=42)
bst = XGBClassifier(n_estimators=2, max_depth=2, learning_rate=1, objective='binary:logistic')
bst.fit(X_train, y_train)
y_pred = bst.predict(X_test)ベースラインモデルと同じように学習をさせます。
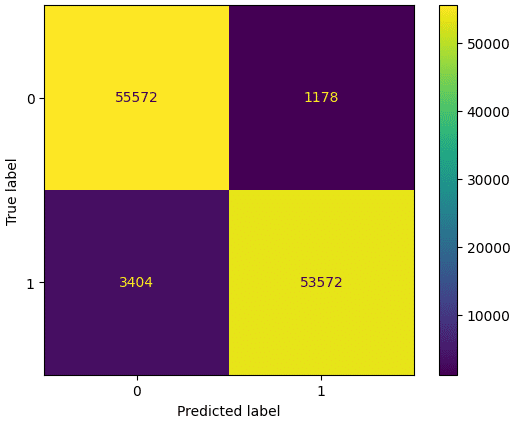
recall_score(y_test, y_pred)Recallは0.94となり、実際に不正であった取引のうち、モデルが不正と正しく予測した取引の割合を改善することができました。