
TimeGPT-1でアノマリー検知

今回はアノマリー検知を試してみたいと思います。
前回はTimeGPTの予測を試し、金融時系列データに対しても予測を出力してみました。
アノマリー検知
下記のチュートリアルを見ながら進めていきます。
インストール
pip install nixtlatsfrom nixtlats import TimeGPT
timegpt = TimeGPT(
token = '取得したAPIキーを設定する'
)データセットの読み込み
import pandas as pd
pm_df = pd.read_csv('https://raw.githubusercontent.com/Nixtla/transfer-learning-time-series/main/datasets/peyton_manning.csv')今回使用されているデータセットはペイトン・マニングというアメフト選手のWikipediaアクセス数のデータのようです。日付データは「timestamp」で表され、アクセス数は数値データとして「value」に格納されています。

アノマリーを検知
timegpt_anomalies_df = timegpt.detect_anomalies(pm_df, time_col='timestamp', target_col='value', freq='D')
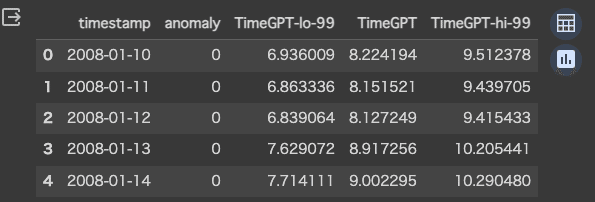
timegpt_anomalies_df.head()ではアノマリーの検出をやってみたいと思います。アノマリーの検出はdetect_anomaliesで行います。指定するパラメーターは下記の通りです。
time_col: 日付のカラムを指定
target_col: 検知対象のカラムを指定
freq: 時系列データの頻度をPandasのフォーマットで指定。Dは日間になります。
detect_anomaliesを実施するとanomalyカラムが追加され、検出された場合には1, それ以外には0が入ります。
timegpt.plot(pm_df,
timegpt_anomalies_df,
time_col='timestamp',
target_col='value')
detect_anomaliesメソッドはデフォルトでは、99%の予測区間を用いて観測値の異常検知を行うとのことです。この閾値は、levelというパラメーターで変更が可能になっています。
timegpt_anomalies_df = timegpt.detect_anomalies(pm_df, time_col='timestamp', target_col='value', freq='D', level=80)
timegpt.plot(pm_df,
timegpt_anomalies_df,
time_col='timestamp',
target_col='value')試しに80%に設定してみました。
閾値を下げたので、より多くの観測値が異常値として検出されました。

まとめ
今回はTimeGPTでアノマリー検知をやってみました。