Great Expectationsでトレーニングデータの検証

Great Expectationsとは?
Great Expectationsは、Python向けのデータバリデーションライブラリです。このツールは、データの品質と一貫性を確保するために使用されます。具体的には、データの検証ルールを定義し、それに基づいてデータが正しいかどうかをチェックします。
この記事では、機械学習モデルを学習するためのトレーニングデータの検証を行うというシナリオでGreat Expectationsを使ったデータの検証を行ってみます。
環境はGoogle Corabです。
インストール
!pip install great_expectationsデータセットの読み込み
検証のデータセットにはTitanicを利用したいと思います。このデータセットは、1912年に沈没したタイタニック号の乗客の情報を含んでおり、生存者を予測するためのモデルを構築することが目的となっています。
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()
データの検証
それでは、Great Expectationsをインポートしてデータを読み込み検証を行っていきたいと思います。
import great_expectations as ge
ge_df = ge.from_pandas(titanic)カラムが存在するかどうか
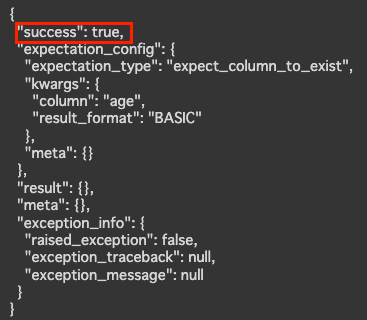
試しにageカラムが存在するかどうかをexpect_column_to_existで検証してみます。
ge_df.expect_column_to_exist('age')検証の結果はJSONフォーマットで返却されて、赤枠に検証結果が示されていいます。Titanicデータセットにはageカラムが存在するので期待通りの結果となっています。
NULL値でないことを確認する
次にexpect_column_values_to_not_be_nullでageカラムにNULL値がないことを検証してみます。
ge_df.expect_column_values_to_not_be_null('age')結果は下記の通り、不正となりました。

実際にNULL値を下記のコードで確認してみると、検証結果で示された177件のNULL値があることが確認できます。
titanic['age'].isnull().sum()特定の値であることを確認する
最後にageカラムが特定の値であるかどうかを確認してみます。
ageカラムの値が0.42から80までの値であるかどうかを検証しています。
ge_df.expect_column_values_to_be_between('age', min_value=0.42, max_value=80)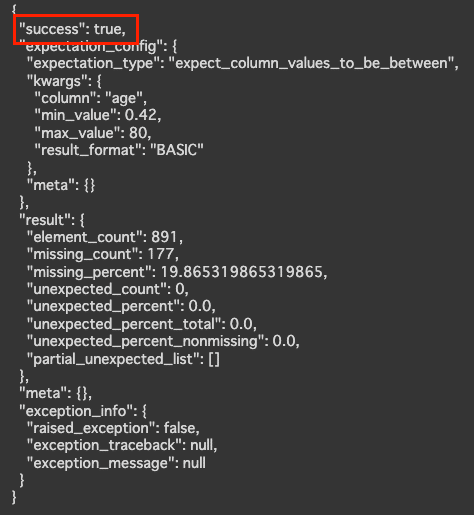
このように検証ルールを設定することで、データの品質を評価し、モデルのトレーニング前に問題を特定することが可能になります。
搭載されている検証ルールは下記のページから確認できます。