シルエットスコア(Silhouette Score)でクラスタリング効果を評価する

シルエットスコア(Silhouette Score)とは?
シルエットスコア(Silhouette Score)は、クラスタリングの効果を評価するために使用される指標の一つです。このスコアは、各データポイントがどの程度適切にクラスタリングされているかを数値で示します。具体的には、ク
ラスタ内の凝集度とクラスタ間の分離度を用いて計算されます。
シルエットスコアは -1 から 1 の範囲で、1 に近いほどクラスタリングの品質が高いことを示します。スコアが 0 に近い場合は、クラスタの境界が曖昧であることを示し、負の値はクラスタリングが不適切である可能性があります。
以下の式でシルエットスコアを計算します。
$$
s= \frac{b−a}{max(a,b)}
$$
aは凝集度、bは分離度になります。
凝集度:各データポイントに対して、その点が属するクラスタ内の他の点との平均距離を計算します。この距離は、データポイントがそのクラスタにどれだけ「よくフィットしているか」を示します。凝集度が小さいほど、そのデータポイントはクラスタ内でより密接しています。
分離度:各データポイントに対して、最も近い別のクラスタとの平均距離を計算します。この距離は、異なるクラスタとの「分離」を示します。分離度が大きいほど、そのデータポイントは他のクラスタから遠く離れています。
この記事では、scikit-learnに実装されているsilhouette_scoreを用いてクラスタリングの効果を評価してみます。
データセット
シルエットスコアの差が明確になるようなデータセットを2つ用意してみます。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X1, _ = make_blobs(n_samples=300, centers=2, cluster_std=1.0, random_state=42)
kmeans1 = KMeans(n_clusters=2, random_state=42).fit(X1)
X2, _ = make_blobs(n_samples=300, centers=2, cluster_std=5.0, random_state=42)
kmeans2 = KMeans(n_clusters=2, random_state=42).fit(X2)
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].scatter(X1[:, 0], X1[:, 1], c=kmeans1.labels_, cmap='viridis', marker='o', edgecolor='k', s=50)
axes[0].set_title('Dataset 1')
axes[0].set_xlabel('Feature 1')
axes[0].set_ylabel('Feature 2')
axes[1].scatter(X2[:, 0], X2[:, 1], c=kmeans2.labels_, cmap='viridis', marker='o', edgecolor='k', s=50)
axes[1].set_title('Dataset 2')
axes[1].set_xlabel('Feature 1')
axes[1].set_ylabel('Feature 2')
plt.tight_layout()
plt.show()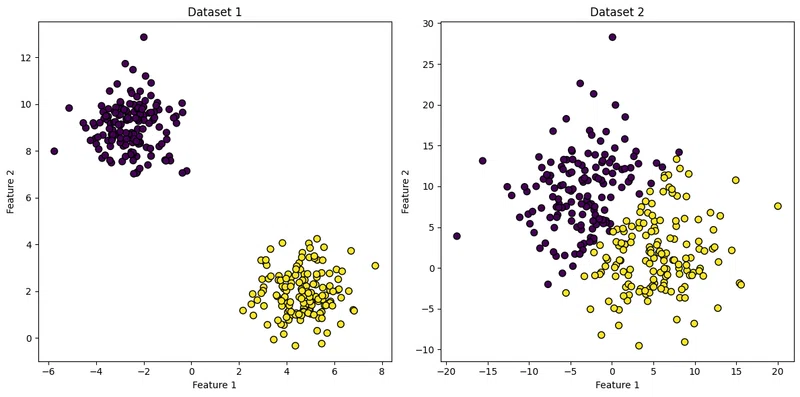
データセット1(左の図):各クラスタ内のデータポイントが密集していてクラスタも明確に分離しています。
データセット2(右の図):各クラスタ内のデータポイントが広がっていて、クラスタ間の境界が不明瞭です。
シルエットスコアの計算
それではこの2つのデータセットについてシルエットスコアを計算してみます。
from sklearn.metrics import silhouette_score
silhouette_score1 = silhouette_score(X1, kmeans1.labels_)
silhouette_score2 = silhouette_score(X2, kmeans2.labels_)
print("データセット1のシルエットスコア: {:.2f}".format(silhouette_score1))
print("データセット2のシルエットスコア: {:.2f}".format(silhouette_score2))sklearn.metricsのsilhouette_scoreを利用します。
結果は以下の通りになりました。
データセット1のシルエットスコア: 0.83
データセット2のシルエットスコア: 0.43
グラフからもわかるように、データセット1について高い品質を示す結果となりました。