K-fold 交差検証(Cross-Validation)のPurge & Embargoテクニックについて

交差検証(Cross-Validation)とは?
機械学習モデルを訓練する際には、データセットを通常は下記の目的別に分割します。
訓練用データ
検証用データ
テスト用データ
最も簡単な分割例としては、データ全体の20%をテスト用に分けておき、残りの80%を訓練用と検証用に使用します。検証用に20%を割り当てるとすると、訓練用は60%のデータしか残らないため、訓練用データが少なくなってしまう問題が起きます。また分割した検証用データに過学習してしまう可能性もあります。
この問題を解決するのが、交差検証(Cross-Validation)です。交差検証には様々なアプローチがありますが、K-fold 交差検証とよばれる基本的なアプローチがあります。
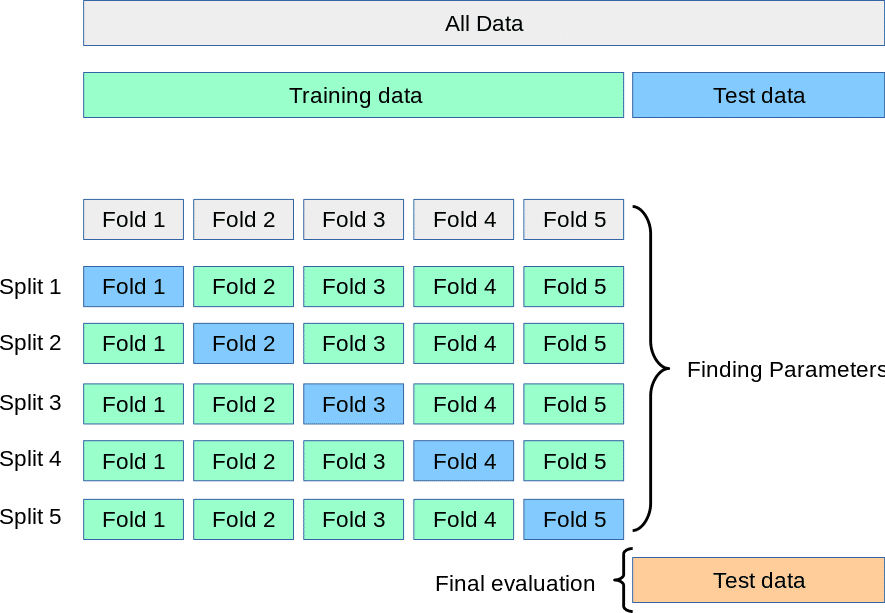
K-fold 交差検証は、全体のデータセットをk個のグループに分割します。
最初のグループを検証用に利用し、残りのグループを学習データとして利用します。それぞれのグループが検証に利用されるまで学習と評価を繰り返し、最終的に結果の平均をとります。
このK-fold 交差検証は一般的には機能しますが、時系列データでは独立同一分布(i.i.d.)ではないため、問題が生じます。時系列データは連続しているため、過去の値は未来の値に影響を及ぼす傾向があり、ある時刻 t の特徴は、時刻 t + 1の特徴と高い相関関係にあります。この問題を解決するためには、訓練データと検証データ間の相関関係に対処する必要がありますが、それに対してPurge & Embargoというテクニックがあります。
Purge
Purgeは訓練用と検証用の間に一定期間訓練用でもない検証用でもない期間を設けます。

Embargo
Embargoは検証用に続く、訓練用データとの間にのみ、一定期間訓練用でもない検証用でもない期間を設けます。

まとめ
今回は、交差検証の基本的なアプローチであるK-fold 交差検証から発展した
テクニックである、PurgeとEmbargoについて取り上げました。
次回は、Purge & Embargoテクニックを実際に実装してデモンストレーションを行ってみたいと思います。