AutoGluonで時系列データのAutoML

AutoGluonとは?
AutoGluonはAutoMLのフレームワークです。テーブル、時系列、マルチモーダルといった複数のデータの種類に対応しています。
この記事では時系列データのAutoMLを行ってみます。
環境はGoogle Corabです。
インストール
!pip install autogluonインポート
import pandas as pd
from autogluon.timeseries import TimeSeriesDataFrame, TimeSeriesPredictor時系列データにはTimeSeriesDataFrame、TimeSeriesPredictorを利用します。AutoGluonにはそれぞれデータの種類に応じたPredictorが実装されています。
データの読み込み
ここでは、M4コンペティションの時系列データ(1時間毎)を利用しています。
df = pd.read_csv("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/train.csv")
df.head()
train_data = TimeSeriesDataFrame.from_data_frame(
df,
id_column="item_id",
timestamp_column="timestamp"
)
train_data.head()PandasのDataframeからTimeSeriesDataFrameフォーマットに変換します。
学習
TimeSeriesPredictorを利用して学習を行います。
predictor = TimeSeriesPredictor(
prediction_length=48,
path="autogluon-m4-hourly",
target="target",
eval_metric="MASE",
)引数:
prediction_length:何ステップ先まで予測するように訓練されるべきかを指定します。例えば日次のデータで3を指定した場合は、3日間の予測が行われます。
path:モデルの保存先を指定します。
target:予測を行う目的変数を指定します。
eval_metric:評価指標を指定します。
AutoMLで学習されるモデルの一覧をmodel_names()で確認してみます。
predictor.model_names() モデルの一覧
Naive
SeasonalNaive
Theta
RecursiveTabular
DirectTabular
WeightedEnsemble
上記の各モデルで自動で学習が行われます。それでは、最後にfit()で学習を行います。
predictor.fit(
train_data,
presets="medium_quality",
time_limit=600,
)引数:
presets:コンフィグのプリセットを指定します。指定可能なプリセットはこちらで確認できます。上記のmedium_qualityはデフォルト設定で妥当な訓練時間と精度で学習を行おうとします。他にも速度重視や、精度重視のプリセットが用意されています。
time_limit:fit()が実行される時間を指定しています。指定されない場合、fit()は全てのモデルの訓練が完了するまで実行されます。
予測
予測をpredict()で行います。
デフォルトでは、検証セットで一番良いスコアを出したモデルを使用して予測が行われます。
predictions = predictor.predict(train_data)
predictions.head()
またどれがベストモデルか?といった各学習モデルの情報をinfo()で確認することができます。
predictor.info()
今回のベストモデルはWeightedEnsembleでした。
予測の可視化
import matplotlib.pyplot as plt
test_data = TimeSeriesDataFrame.from_path("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly_subset/test.csv")
plt.figure(figsize=(20, 3))
item_id = "H1"
y_past = train_data.loc[item_id]["target"]
y_pred = predictions.loc[item_id]
y_test = test_data.loc[item_id]["target"][-48:]
plt.plot(y_past[-200:], label="Past time series values")
plt.plot(y_pred["mean"], label="Mean forecast")
plt.plot(y_test, label="Future time series values")
plt.fill_between(
y_pred.index, y_pred["0.1"], y_pred["0.9"], color="red", alpha=0.1, label=f"10%-90% confidence interval"
)
plt.legend();
各モデルのパフォーマンスを確認する
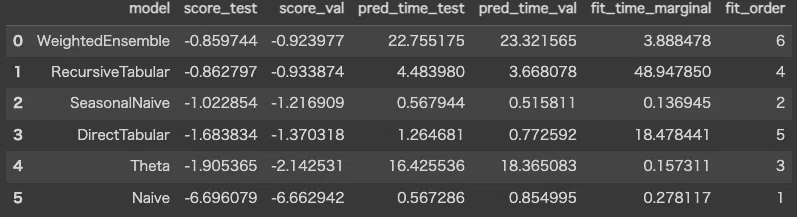
leaderboard()で各モデルのパフォーマンスを一覧で確認することができます。先ほど確認した6個のモデルのそれぞれのパフォーマンスが一覧で確認出来ます。
predictor.leaderboard(test_data)